注意點: 1. 用Fiddler抓取登陸後的headers,cookies; 2. 每抓取一次網頁暫停一點時間防止反爬蟲; 3. 抓取前,需要關閉Fiddler以防止端口占用.
還需解決的問題:
爬取記錄較多時,會觸發反爬蟲機制。
用Fiddler抓取登陸後的headers,cookies
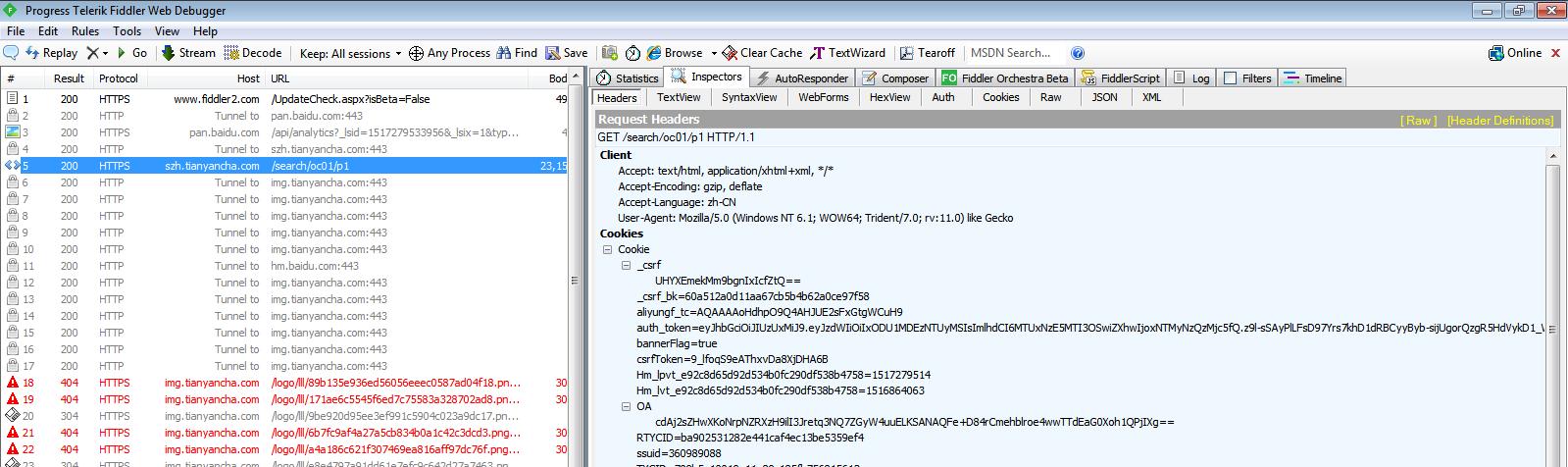
也可使用火狐F12檢視

#-*- coding: utf-8 -*-
import sys
import time
import urllib
import bs4
import re
import random
import requests
def main(startUrl):
print(startUrl)
global csvContent
headers = {'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
cookies = {
'_csrf':'iN90P1mtdXxv/ZWpt8W8kg==',
'_csrf_bk':'b095b5ac898229ebf3adc8f0e901523a',
'aliyungf_tc':'AQAAAAoHdhpO9Q4AHJUE2sFxGtgWCuH9',
'auth_token':'eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxODU1MDEzNTUyMSIsImlhdCI6MTUxNzE5MTI3OSwiZXhwIjoxNTMyNzQzMjc5fQ.z9l-sSAyPlLFsD97Yrs7khD1dRBCyyByb-sijUgorQzgR5HdVykD1_W_gn8R2aZSUSRhR_Dq0jPNEYPJlI22ew',
'bannerFlag':'true',
'csrfToken':'9_lfoqS9eAThxvDa8XjDHA6B',
'Hm_lpvt_e92c8d65d92d534b0fc290df538b4758':'1517191269',
'Hm_lvt_e92c8d65d92d534b0fc290df538b4758':'1516864063',
'OA':'TkU7nzii8Vwbw4JYrV6kjTg0WS645VnS6CIervVVizo=',
'ssuid':'360989088',
'TYCID':'709b5a10019e11e89c185fb756815612',
'tyc-user-info':'%257B%2522token%2522%253A%2522eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxODU1MDEzNTUyMSIsImlhdCI6MTUxNzE5MTI3OSwiZXhwIjoxNTMyNzQzMjc5fQ.z9l-sSAyPlLFsD97Yrs7khD1dRBCyyByb-sijUgorQzgR5HdVykD1_W_gn8R2aZSUSRhR_Dq0jPNEYPJlI22ew%2522%252C%2522integrity%2522%253A%25220%2525%2522%252C%2522state%2522%253A%25220%2522%252C%2522vipManager%2522%253A%25220%2522%252C%2522vnum%2522%253A%25220%2522%252C%2522onum%2522%253A%25220%2522%252C%2522mobile%2522%253A%252218550135521%2522%257D',
'undefined':'709b5a10019e11e89c185fb756815612'
}
resultPage = requests.get(startUrl, headers= headers, cookies = cookies)
randomTime= random.random()*10+5
print('randomTime '+str(randomTime))
time.sleep(randomTime)
soup = bs4.BeautifulSoup(resultPage.text,'html.parser')
industry = soup.find_all(attrs={'class': 'in-block overflow-width vertival-middle sec-c2'})[0].string;
companys= soup.find_all(attrs={'class': 'search_right_item ml10'})
for company in companys:
tempCsvContent=''
tempCsvContent+=industry+','
tempCsvContent+=company.contents[0].a.string+','
# if(company.contents[0].a.string=='昆山市大千園藝場'):
# break;
for child in company.contents[1].div.children:
content= str(child.get_text);
if None!=re.search("法定代表人",content):
try:
tempCsvContent+=child.a.string+','
except:
tempCsvContent+=','
elif None!=re.search("注冊資本",content):
try:
tempCsvContent+=child.span.string+','
except:
tempCsvContent+=','
elif None!=re.search("注冊時間",content):
try:
tempCsvContent+=child.span.string+','
except:
tempCsvContent+=','
elif None!=re.search("江蘇",content):
try:
tempCsvContent+=re.match('^.*?f20">(\d+).*$',content).group(1)+','
except:
tempCsvContent+=','
else:
None
try:
tempCsvContent+=company.contents[0].a.attrs['href'] +','
link = company.contents[0].a.attrs['href']
linkResult = requests.get(link, headers= headers, cookies = cookies)
randomTime2= random.random()*10+5
print('randomTime 2 '+str(randomTime2)+' '+link)
time.sleep(randomTime2)
linkSoup = bs4.BeautifulSoup(linkResult.text,'html.parser')
location = linkSoup.find_all(attrs={'colspan': '4'})[0].text.replace('附近公司','');
tempCsvContent+=location+',';
selfRisk = linkSoup.find(attrs={'class': 'new-err selfRisk pl5 pr5'}).string;
tempCsvContent+=selfRisk+',';
roundRisk = linkSoup.find(attrs={'class': 'new-err roundRisk pl5 pr5'}).string;
tempCsvContent+=roundRisk+',';
riskItems = linkSoup.find(attrs={'class': 'navigation new-border-top new-border-right new-c3 js-company-navigation'}).find(attrs={'class': 'over-hide'}).find_all(attrs={'class': 'float-left f14 text-center nav_item_Box'});
for content in riskItems[2].contents[1]:
value = str(content)
try:
if('<span class="c9">' in value):
tempCsvContent+=content.span.string+',';
else:
tempCsvContent+='0'+',';
except:
tempCsvContent+='0'+',';
for content in riskItems[3].contents[1]:
value = str(content)
try:
if('<span class="c9">' in value):
tempCsvContent+=content.span.string+',';
else:
tempCsvContent+='0'+',';
except:
tempCsvContent+='0'+',';
for content in riskItems[4].contents[1]:
value = str(content)
try:
if('<span class="c9">' in value):
tempCsvContent+=content.span.string+',';
else:
tempCsvContent+='0'+',';
except:
tempCsvContent+='0'+',';
for content in riskItems[5].contents[1]:
value = str(content)
try:
if('<span class="c9">' in value):
tempCsvContent+=content.span.string+',';
else:
tempCsvContent+='0'+',';
except:
tempCsvContent+='0'+',';
tempCsvContent=tempCsvContent.rstrip(',')
tempCsvContent+='\r'
csvContent+=tempCsvContent
except:
print('exception')
tempCsvContent=''
print(csvContent)
print()
print()
print()
print()
print()
if __name__ == '__main__':
for i in range(3,4):
name=str(i).zfill(2)
file = open('D:\\result-'+name+'.csv','w')
csvContent='行業分類,企業描述,法定代表人,注冊資本,注冊時間,分數, 細節, 注冊位址, 天眼風險-自身風險, 天眼風險-周邊風險, 法律訴訟, 法院公告, 失信人, 被執行人, 開庭公告, 經營異常, 行政處罰, 嚴重違法,股權出質,動産抵押,欠稅公告,司法拍賣, 招投标,債券資訊,購地資訊,招聘,稅務評級,抽查檢查,産品資訊,進出口信用,資質證書,微信公衆号,商标資訊,專利,軟體著作權,作品著作權,網站備案\r'
for j in range(1,6):
# randomTime= random.random()*10+10
# print('randomTime header '+str(randomTime))
# time.sleep(randomTime)
main('https://szh.tianyancha.com/search/oc'+str(i).zfill(2)+'/p'+str(j))
file.write(csvContent)
file.close
csvContent=''
print(csvContent)
運作結果示例
代碼連結