本文提出了一種基于CNN的3D物體識别方法,能夠從3D圖像表示中識别3D物體,并在比較了不同的體素時的準确性。已有文獻中,3D CNN使用3D點雲資料集或者RGBD圖像來建構3D CNNs,但是CNN也可以用于直接識别物體體積表示的體素。本文中,我們提出了3D CAD物體檢測。
相關工作
- 3D形狀描述符。 現代3D物體識别模型起始于60年代,早期的識别架構基于幾何模型。然而,大多數識别工作基于手工提取的特征描述符,例如點特征直方圖,3D形狀上下文等。CNN第一次用于識别3D物體識别時用于識别RGBD圖像,其中深度作為額外的輸入通道。基于深度的方法在概念上非常類似于基于二維的識别方法。深度僅作為CNN的第四個通道,使用3D合成模型作為CNN的輸入。然而,使用深度通道和顔色通道産生2.5D,不能提供物體的全部幾何資訊。近年來,研究者嘗試了基于多視圖和體積資訊來更好的形狀描述符。
- 卷積神經網絡。CNNs是為圖像和音頻信号等二維資料而設計的。它廣泛應用于各種計算機視覺任務和資料科學中。CNN在基于二維圖像的任務中被廣泛使用的原因是可以獲得大量的基準資料集,與手工制作的特征相比,這些大型資料集有助于生成更好的圖像描述符。本文将相似的特征學習方法應用于三維資料而不是二維資料。
- 三維資料上的卷積神經網絡. 近年來,随着基于距離和三維CAD資料集的可用性,研究人員獲得了與二維圖像相比的圖像中物體的附加資訊。在深度網絡中,采用動作、多視圖和基于體積的方法來表示三維資料。将基于運動的CNN結構成功地應用于動作識别任務中。Wu等人開發了第一個基于體積資料的CNN架構,即3DShapeNets。3DShapeNets使用一個深度信念網絡來表示三維幾何形狀,将其表示為三維體素網格上二進制變量的機率分布。他們也用他們的方法從深度圖中完成形狀。然而,我們的工作靈感來自VoxNet,它是由Maturana & Shere設計的。VoxNet由一個簡單而有效的CNN組成,接受類似于Wu等人的輸入體素網格。3D ShapeNets和VoxelNet提供了最先進的結果。另外值得注意的作品還有Shi等人提出的全景視圖[22]和Su等人提出的多視圖CNN。
資料集
近年來,已有一些3D資料集可用。但是,這些資料集沒有像包含2D圖像的ImageNet1資料集那樣大。有許多合理大小的三維資料集。大多數三維資料集是基于點雲的,這些點雲是通過距離掃描器擷取的,比如ModelNet2、Sydney Urban Objects3、SUN-3D4。ModelNet資料集用于訓練和測試提出的CNN模型。ModelNet資料集包含來自662個不同對象類的127,915張CAD三維圖像。ModelNet40是ModelNet的一個子集,它是3D對象識别的基準,并分為9843個訓練圖像和2468個測試圖像中使用。在實驗中,我們還在ModelNet10上測試了我們的網絡。ModelNet10有10個對象類别,它是ModelNet40的一個子集。在實驗中,我們還在ModelNet10上測試了我們的網絡。ModelNet10有10個對象類别,它是ModelNet40的一個子集。
方法
通過從目标類中選擇最相似的特征,實作了三維CNN中的目辨別别。對象識别過程可分為兩部分,即三維對象的資料表示和CNN對表示資料的訓練。我們在提出的架構中使用了三維體資料表示。大多數研究人員使用體素或點雲方法來表示體積資料。我們在CNNs中使用了基于體素的資料表示。體素是在二進制“occupation grid”的幫助下生成的。與二維資料集相比,dataset提供的模型數量較少,是以,為了利用網絡,我們向模型提供了沿重力方向30°的旋轉。所有的體素都是由ModelNet 資料集中提供的網格模型渲染到12個不同的方向後生成的。本文所提出的網絡是Voxnet的改進版本。我們使用了兩種不同的網絡進行教育訓練。
網絡模型1
Network-1包括三個卷積層和兩個完全連接配接的層。大多數研究人員使用的體素大小等于或小于32×32×32。但是,我們認為32×32×32像素對于一個物體的準确預測是非常少的。在二維圖像任務中,實驗表明小于227×227的疊代對二維圖像中的目辨別别任務效果不佳。為了充分利用網絡,我們使用體素有32×32×32、64×64×64、128×128×128三種不同尺寸。體素中的許多像素表示空單元,産生大量不必要的矩陣乘法(零值矩陣)。為了降低這一成本,我們使用5×5×5的核來代替體積CNNs中常用的3×3×3卷積核。卷積(layer)操作後使用ReLU和max-pooling(大小為2×2×2)層。池化層來減少過多參數的過拟合。為了避免資料過拟合,由于方向和相似的視圖,我們在第一個完全連接配接層之前使用dropout層,機率為0.5。
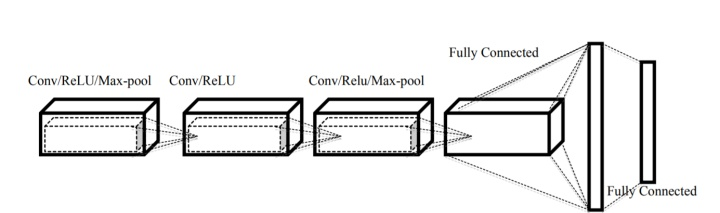
網絡模型2
網絡模型2的靈感來自AlexNet的網絡架構。它由五個卷積層和三個全連接配接的層組成。網絡模型2還使用了體素的多個視圖。我們以30度旋轉訓練網絡。除了池之外,此網絡具有network-1中使用的所有設定。為了訓練網絡,我們沒有使用網絡中池化層。在我們看來,池化可以在對象的形狀上産生歧義。Network-2幫助我們了解CNN的深度如何影響識别模型的性能。

實驗
該網絡使用ModelNet資料集進行訓練和測試。所有的三維CAD圖像都使用[19]提供的腳本在體素中轉換。我們測試了不同尺寸的體素32×32×32、64×64×64和128×128×128的網絡。我們分别實作了這兩個網絡,并比較了它們的結果。然而,兩種網絡的結果有非常小的差異。我們比較了ModelNet10和ModelNet40資料集的體素大小相同的結果。結果表明,高分辨率體素提高了識别任務的精度。與VoxNet相比,我們的模型具有更好的精度。然而,VoxNet在其架構中隻有不到100萬個參數,而我們的network-2有超過200萬個參數。我們訓練network-2不使用pooling來測試pooling對volume - CNN的效果。但結果表明,池化層對結果沒有顯著影響。池化層對性能沒有影響的原因之一是,用于訓練和測試的所有體素都是實心的。ModelNet資料集中沒有一個對象模型,它具有空心對象。結果如圖4所示,圖5為損耗和精度。
結論
本文描述了基于體素的三維資料表示的三維資料識别任務。分析了CNN在不同體素尺寸下的性能。分析進一步設計新的網絡和測試不同大小的體素,以找到适合CNN操作的大小。實驗結果表明,體素的大小直接影響目辨別别任務。但是另一方面,增加體素的大小會在容量CNN架構中造成性能瓶頸。為了克服這一問題,我們應該探索一種關于時間和空間的優化資料結構來處理體素的大尺寸。