最近研究了Raft 協定,談談自己對 Raft 協定的了解。希望這篇文章能夠幫助大家了解 Raft 論文
Raft 是什麼?
Raft 是一種分布式系統的一緻性算法。
在分布式系統中,我們需要讓一組機器作為一個整體向外界提供服務。由于在實際的條件下,我們認為每台機器都是不100%可靠的,随時都可能發生當機。每台機器之間的通信也不是可靠的,可能發生通信的阻塞、丢失、重試。是以需要某些算法來保證在大多數機器都正常的情況下向外提供可靠的服務。
在 Raft提出之前,Paxos 已經被提出,但是 Paxos 相當複雜。Raft 的目标就是提出一種易于了解的分布式一緻性算法。
在了解 Raft 之前需要了解一下什麼狀态機:
論文指出,Raft 是一種用來管理日志複制的一緻性算法。是以我們就要先了解一下。什麼是日志複制狀态機。我們思考一個問題。如果你要與你的小夥伴分享一個很複雜的操作及計算。一般來說你有兩種做法: 第一種:你自己負責計算,經過一段時間的計算,算出結果後,直接把計算結果告訴你的小夥伴。 第二種:你把每一個操作的步驟都告訴你的夥伴,告訴他怎麼做,由你的夥伴自己計算出結果。
第二種方式,就是複制狀态機的工作原理。複制狀态機是通過複制日志來實作的。每一台伺服器儲存着一份日志,日志中包含一系列的指令,狀态機會按順序執行這些指令。因為每一台計算機的狀态機都是确定的,是以每個狀态機的狀态都是相同的,執行的指令是相同的,最後的執行結果也就是一樣的了。
在實際中這種有很多類似的應用比如 mysql 的主從同步就是通過 binlog 進行同步。
在現實生活中,如何有效的組織多人進行協助,最自然的想法就是選舉一個上司,交由上司極大的權威,就能極大的提升整個團隊工作效率。
下面就談談我對 Raft 算法的了解。
基本安全保證:
為了保證過程正确性,Raft需要保證以下的性質時刻為真:
- 選舉安全原則: 同一屆任期内至多隻能有一個上司人。
- 上司人隻加原則: 上司人的日志隻能增加,不能重寫或者删除。
- 日志比對原則: 如果兩個日志具有相同的任期和索引,則這兩段日志在[0,索引]之間的日志完全相同。
- 上司人完全原則: 如果一條日志被送出,那麼後續的任意任期的上司人都會有這條日志。
- 狀态機安全原則: 如果一個伺服器已經将給定索引位置的日志條目應用到狀态機中,則所有其他伺服器不會在該索引位置應用不同的條目。
選取上司者
是以 Raft 算法成立的最重要的前提之一就是選舉。
- Raft 由多個節點組成。
- 強上司者, 整個 Raft 在同一時間,隻有一個上司者,日志有上司者負責分發和同步。
- 上司選舉, 上司是由民主選舉産生的,叢集中多數節點投票通過就能成為主。
對于在叢集中的節點。在任意時間中,都有可能處于以下三種狀态之一:
- 跟随者
- 候選人
- 上司人
每個上司人都有一個任期限制。每一屆任期的開始階段,都是選舉。如果選舉出了上司者就由該上司人負責上司叢集。如果沒有選舉出上司,就會進入下一次選舉。直到選舉出上司者為止。
角色之間的轉換:
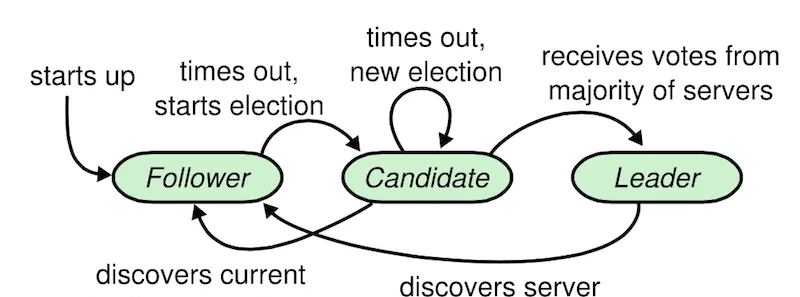
上司者會周期性的向每台機器發送心跳,確定自己的上司地位。
跟随者在長時間沒有收到上司人的心跳,就會發起投票成為候選人,同時任期 + 1,如果獲得超過半數的支援,就升任為上司。
如果候選人,在發起投票的時候,發現叢集裡面有上司人的時候,就會重新成為追随者。
如果候選人,發起投票後,一定時間裡面沒有收到超過半數的回報,就會再次發起投票。
如果上司者發現在叢集中發現存在下一任期的上司者,就會變為追随者。
日志同步
在選舉出上司人以後,就開始處理用戶端的日志。
上司者在收到用戶端的請求,每個請求包含一個操作的指令。上司者會将指令記錄到自己的日志中,并向自己的追随者發起同步的請求,要求自己的追随者複制這個指令。
一旦這個指令被大多數的追随者儲存了。上司者就認為這個狀态已經處于送出(commited)的狀态。同時告知用戶端,指令已經被送出。如果這個時候,追随者發生了崩潰或者延時。上司者會一直嘗試重試,直到追随者接受指令,并存儲到自己的日志中。這個過程一直持續到所有的追随者最終存儲了所有的日志條目。
作為 Raft 的節點需要保證如下性質。
- 如果在不同日志中的兩個條目有着相同的索引和任期号,則它們所存儲的指令是相同的。
- 如果在不同日志中的兩個條目有着相同的索引和任期号,則它們之間的所有條目都是完全一樣的。
有了如上性質的保證。如果在某些情況下,發生了追随者的日志與上司者不同步的情況。(包括的情況,就可能是丢失日志,或者儲存了上司者沒有的日志,或者兩兼有),在 Raft 算法中,上司人通過強制追随者們複制它的日志來處理日志的不一緻。這就意味着,在追随者上的沖突日志會被上司者的日志覆寫。
為了使得追随者的日志同自己的一緻,上司人需要找到追随者同它的日志一緻的地方,然後删除追随者在該位置之後的條目,然後将自己在該位置之後的條目發送給追随者。
安全分析
需要分析在各種情況下,每個角色發生當機,資料的安全性。
選舉限制
Raft 保證自己的日志,永遠由上司者向追随者流動。也就是說上司者永遠不會删改自己的日志,隻能向上增加日志。為了達成這個限制,Raft 使用投票的方式來阻止沒有包含全部日志條目的伺服器赢得選舉。
當一個候選人發起投票的時候,需要告訴大家,自己最新的日志。其他節點在投票的時候,要保證自己的日志不能比候選人的新,否則就拒絕投票。通過這個限制就保證了擷取多數票的上司者的日志,至少比大多數人要新。
任期越大,日志越長,越容易成為上司者。
送出之前任期的日志條目

這個在論文中比較難以了解。我看到這一節的時候也是讀了好幾遍才了解論文的意思。實際上作者表達的意思是圖 (d)是正确的,而(e)是錯誤的。
因為 2 号日志沒有commited,但是由于一系列操作,造成了 2 号日志沒有送出,但是高任期的leader 卻認為 2 号日志被送出了。
為了解決這個問題。Raft 限制,隻有目前任期的 leader 可以決定一條日志是否 commited,而不能由高任期的 leader 通過計算某條日志(例子中的 2号日志)超過半數節點持有,就确定日志被commited。
換句話說,就是 Raft 限制每個leader 隻能确定自己任期内的日志是否commited。而不能由高任期的 leader确定。
追随者和候選人崩潰
由于 Raft 是一個強上司的,少數服從多數的系統。上面花了了很多的篇幅讨論 leader 奔潰後 Raft 協定是如何保證準确性和安全性的。如果追随者或者候選人挂了,就比較簡單了。
如果候選人崩潰,一段時間以後,某個節點會出發逾時,重新發起選舉,一切就回複正常了。
如果一個追随者崩潰,會被 leader 感覺。 leader 會一直重試,直到追随者恢複,并同步所有日志。
系統的擴容
分布式系統一大優勢就是能夠快速擴容。
Raft 為了保證擴容的安全性,采用了兩段two-phase)方法。
在Cold 和 Cnew 之間存在一個中間态, Cold,new 的狀态。防止剛開始擴容的時候,新的一組機器數量大于老叢集數量,就有可能在新機器中自發投票選舉出一個 leader,造成叢集中有兩個leader形成腦裂。
- 日志條目被複制給叢集中新、老配置的所有伺服器。
- 新、老配置的伺服器都能成為上司人。
- 需要分别在兩種配置上獲得大多數的支援才能達成一緻(針對選舉和送出)
需要解決三個問題:
- 為了不拖慢整個叢集相應速度,可以不給新加入的節點投票權。知道日志追齊以後再開放投票權力
- 如果擴容以後,老的 leader 屬于被踢出的節點,老 leader 不會立即下線,而是繼續工作,直到 Cnew 被送出。這個時候 leader 自己隻負責管理叢集而自己不追加日志。
- 将要被被删除的節點,不會收到上司的心跳,就會不停的認為自己逾時,會不斷的成為候選人,并不斷的發起投票。造成叢集的 leader 不斷的退位,然後再次産生 leader。造成叢集的響應能力降低。為了避免這個問題,當伺服器确認目前上司人存在時,伺服器會忽略請求投票。每個伺服器在開始一次選舉之前,至少等待一個最小選舉逾時時間。
日志的壓縮:
日志的壓縮比較容易了解,随着叢集的使用,日志的數量越來越大,就會降低叢集的性能,同時占用大量的存儲空間。是以需要定期對日志進行壓縮。快照是最簡單的壓縮方法。在快照系統中,整個系統的狀态都以快照的形式寫入到穩定的持久化存儲中,然後到那個時間點之前的日志全部丢棄。
用戶端互動
整個 Raft 協定中,用戶端隻與 leader 進行互動。
用戶端與叢集通信的時候,首先随便與叢集中的任意一個節點互動,詢問 leader 是誰。
是用戶端對于每一條指令都賦予一個唯一的序列号。然後,狀态機跟蹤每條指令最新的序列号和相應的響應。如果接收到一條指令,它的序列号已經被執行了,那麼就立即傳回結果,而不重新執行指令。這樣保證互動的指令是幂等的。如果一條指令被重複送出,并不會造成狀态機的錯誤。
- 上司人必須擁有最新的資料,這一點是必然的。Raft 天然保證這個特性。
- 上司人在通路資料之前需要發送一次心跳,保證自己的上司地位。
參考:
- Raft 首頁
- Raft 中文翻譯
- Raft java 實作