1. 實作原理
代碼示例:
public class Test {
public static void main(String[] args) {
Test test = new Test();
synchronized (test) {
}
}
} 通過 javac 指令編譯成 class ,再通過 javap -c 檢視位元組碼如下:
Compiled from "Test.java"
public class com.francis.juc.juc.sync.Test {
public com.francis.juc.juc.sync.Test();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: new #2 // class com/francis/juc/juc/sync/Test 建立一個對象test,并将其引用值壓入棧頂
3: dup // 複制棧頂數值并将複制值壓入棧頂(test的引用)
4: invokespecial #3 // Method "<init>":()V 調用超類構造方法,執行個體初始化方法,私有方法
7: astore_1 // 将棧頂元素存儲到局部變量表變量槽 1 中
8: aload_1 // 将局部變量Slow 1 的元素(即test)入棧
9: dup
10: astore_2
11: monitorenter // 以棧頂元素(即test)作為鎖,開始同步
12: aload_2
13: monitorexit // 退出同步
14: goto 22 // 方法正常結束,跳至22行結束
17: astore_3 // 從這步開始是異常路徑,見下面異常表的Taget 17
18: aload_2 // 将局部變量Slow 2的元素(即test)入棧
19: monitorexit // 退出同步
20: aload_3 // 将局部變量Slow 3的元素(即異常對象)入棧
21: athrow // 将棧頂的異常抛出
22: return // 從目前方法傳回void
Exception table:
from to target type
12 14 17 any
17 20 17 any
} Java虛拟機的指令集中有 monitorenter 和 monitorexit 兩條指令來支援 synchronized 關鍵字的語義,正确實作 synchronized 關鍵字需要 Javac 編譯器與 Java 虛拟機兩者共同協作支援,編譯器必須確定無論方法通過何種方式完成,方法中調用過的每條monitorenter 指令都必須有其對應的 monitorexit 指令,而無論這個方法是正常結束還是異常結束。
後續有時間還會繼續完善此文章。。。
2. Java 對象頭的組成
HotSpot虛拟機中,對象在記憶體中的布局分為三塊區域:對象頭、執行個體資料和對齊填充。
HotSpot虛拟機對象頭(Object Header)分為兩部分: Mark Word 和 Klass Pointer 。
Mark Word :存儲對象自身的運作時資料,如哈希碼(HashCode)、GC分代年齡(Generational GC Age)、鎖狀态标志、線程持有的鎖、偏向線程ID、偏向時間戳,這部分資料的長度在32位和64位的Java虛拟機中分别會占用32個或64個比特。
Klass Pointer :存儲對象的類型指針,該指針指向它的類中繼資料,虛拟機通過這個指針确定該對象是哪個類的執行個體。
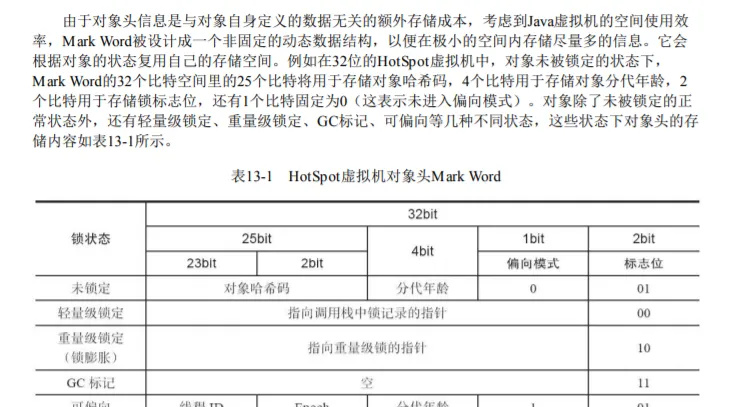
以64位作業系統為例,對象頭存儲内容如下:
|--------------------------------------------------------------------------------------------------------------|
| Object Header (128 bits) |
|--------------------------------------------------------------------------------------------------------------|
| Mark Word (64 bits) | Klass Word (64 bits) |
|--------------------------------------------------------------------------------------------------------------|
| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 無鎖
|----------------------------------------------------------------------|--------|------------------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 偏向鎖
|----------------------------------------------------------------------|--------|------------------------------|
| ptr_to_lock_record:62 | lock:2 | OOP to metadata object | 輕量鎖
|----------------------------------------------------------------------|--------|------------------------------|
| ptr_to_heavyweight_monitor:62 | lock:2 | OOP to metadata object | 重量鎖
|----------------------------------------------------------------------|--------|------------------------------|
| | lock:2 | OOP to metadata object | GC
|--------------------------------------------------------------------------------------------------------------| lock: 鎖狀态辨別位,總共四種狀态。
biased_lock:偏向鎖标記,為1時表示對象啟用偏向鎖,為0時表示對象沒有偏向鎖。
age:Java GC标記位對象年齡。
identity_hashcode:對象辨別Hash碼,采用延遲加載技術。當對象使用HashCode()計算後,并會将結果寫到該對象頭中。當對象被鎖定時,該值會移動到線程Monitor中。
thread:持有偏向鎖的線程ID和其他資訊。這個線程ID并不是JVM配置設定的線程ID号,和Java Thread中的ID是兩個概念。
epoch:偏向時間戳。
ptr_to_lock_record:指向棧中鎖記錄的指針。
ptr_to_heavyweight_monitor:指向線程Monitor的指針。
3. JOL 列印對象頭
1.maven項目pom.xml 中增加如下依賴:
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency> 2.建立測試類:
public class Test {
private boolean flag = false;
public static void main(String[] args) {
Test test = new Test();
System.out.println(ClassLayout.parseInstance(test).toPrintable());
}
} 3.檢視輸出結果:
com.francis.juc.juc.sync.Test object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 1 boolean Test.flag false
13 3 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total 第一行: 00000001,代表無鎖。
unused:1 | age:4 | biased_lock:1 | lock:2
0 0000 0 01 第三行: 表示的是被指針壓縮為32位的klass pointer(64位 JVM會預設使用選項 +UseCompressedOops 開啟指針壓縮,将指針壓縮至32位)。
第四行:表示 Test 對象屬性 flag 1位元組的boolean值。
第五行:代表了對象的對齊字段 為了湊齊64位的對象,對齊字段占用了3個位元組,24bit。
4. 鎖優化
JDK6 為了線上程之間更高效地共享資料及解決競争問題,實作了各種鎖優化技術,如:适應性自旋(Adaptive Spinning)、鎖消除(Lock Elimination)、鎖膨脹(Lock Coarsening)、輕量級鎖(Lightweight Locking)、偏向鎖(Biased Locking)等。
1.自旋鎖與自适應自旋
所謂的自旋鎖就是讓後面請求鎖的那個線程“稍等一會”,但不放棄處理器的執行時間,看看持有鎖的線程是否很快就會釋放鎖。為了讓線程等待,我們隻須讓線程執行一個忙循環(自旋)。
自旋鎖在JDK 1.4.2中就已經引入,隻不過預設是關閉的,可以使用-XX:+UseSpinning參數來開啟,在JDK 6中就已經改為預設開啟了。自旋等待不能代替阻塞,且先不說對處理器數量的要求,自旋等待本身雖然避免了線程切換的開銷,但它是要占用處理器時間的,是以如果鎖被占用的時間很短,自旋等待的效果就會非常好,反之如果鎖被占用的時間很長,那麼自旋的線程隻會白白消耗處理器資源,而不會做任何有價值的工作,這就會帶來性能的浪費。是以自旋等待的時間必須有一定的限度,如果自旋超過了限定的次數仍然沒有成功獲得鎖,就應當使用傳統的方式去挂起線程。自旋次數的預設值是十次,使用者也可以使用參數-XX:PreBlockSpin來自行更改。
不過無論是預設值還是使用者指定的自旋次數,對整個Java虛拟機中所有的鎖來說都是相同的。在JDK 6中對自旋鎖的優化,引入了自适應的自旋。*自适應意味着自旋的時間不再是固定的了,而是由前一次在同一個鎖上的自旋時間及鎖的擁有者的狀态來決定的。*如果在同一個鎖對象上,自旋等待剛剛成功獲得過鎖,并且持有鎖的線程正在運作中,那麼虛拟機就會認為這次自旋也很有可能再次成功,進而允許自旋等待持續相對更長的時間,比如持續100次忙循環。另一方面,如果對于某個鎖,自旋很少成功獲得過鎖,那在以後要擷取這個鎖時将有可能直接省略掉自旋過程,以避免浪費處理器資源。有了自适應自旋,随着程式運作時間的增長及性能監控資訊的不斷完善,虛拟機對程式鎖的狀況預測就會越來越精準,虛拟機就會變得越來越“聰明”了。
2.鎖消除
鎖消除是指虛拟機即時編譯器在運作時,對一些代碼要求同步,但是對被檢測到不可能存在共享資料競争的鎖進行消除。鎖消除的主要判定依據來源于 逃逸分析 的資料支援,如果判斷到一段代碼中,在堆上的所有資料都不會逃逸出去被其他線程通路到,那就可以把它們當作棧上資料對待,認為它們是線程私有的,同步加鎖自然就無須再進行。
舉一個例子:
public static void main(String[] args) {
concatString("a", "b", "c");
}
public static String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
} 我們都知道 StringBuffer.append() 是加了 synchronized 關鍵字的,但經過逃逸分析,發現變量 sb 的作用于僅限于 concatString 方法中,是以這裡雖然有鎖,但是可以被安全地消除掉。在解釋執行時這裡仍然會加鎖,但在經過服務端編譯器的即時編譯之後,這段代碼就會忽略所有的同步措施而直接執行。
3.鎖粗化
原則上,我們在編寫代碼的時候,總是推薦将同步塊的作用範圍限制得盡量小——隻在共享資料的實際作用域中才進行同步,這樣是為了使得需要同步的操作數量盡可能變少,即使存在鎖競争,等待鎖的線程也能盡可能快地拿到鎖。
大多數情況下,上面的原則都是正确的,但是如果一系列的連續操作都對同一個對象反複加鎖和解鎖,甚至加鎖操作是出現在循環體之中的,那即使沒有線程競争,頻繁地進行互斥同步操作也會導緻不必要的性能損耗。
鎖消除中所示連續的append()方法就屬于這類情況。如果虛拟機探測到有這樣一串零碎的操作都對同一個對象加鎖,将會把加鎖同步的範圍擴充(粗化)到整個操作序列的外部,以上述代碼為例,就是擴充到第一個append()操作之前直至最後一個append()操作之後,這樣隻需要加鎖一次就可以了。
4.輕量級鎖
輕量級鎖是JDK 6時加入的新型鎖機制,它名字中的“輕量級”是相對于使用作業系統互斥量來實作的傳統鎖而言的,是以傳統的鎖機制就被稱為“重量級”鎖。不過,需要強調一點,輕量級鎖并不是用來代替重量級鎖的,它設計的初衷是在沒有多線程競争的前提下,減少傳統的重量級鎖使用作業系統互斥量産生的性能消耗。
加鎖過程:
判斷對象是否被鎖定(鎖标志位為“01”狀态),如果沒有鎖定,虛拟機首先将在目前線程的棧幀中建立一個名為鎖記錄(Lock Record)的空間,用于存儲鎖對象目前的Mark Word的拷貝(官方為這份拷貝加了一個Displaced字首,即Displaced Mark Word),這時候線程堆棧與對象頭的狀态如圖所示:

如果對象被鎖定,則進入第3步。
虛拟機将使用CAS操作嘗試把對象的Mark Word更新為指向Lock Record的指針。如果這個更新動作成功了,即代表該線程擁有了這個對象的鎖,并且對象Mark Word的鎖标志位(Mark Word的最後兩個比特)将轉變為“00”,表示此對象處于輕量級鎖定狀态。這時候線程堆棧與對象頭的狀态如圖所示:
如果更新失敗,進入第三步。
虛拟機首先會檢查對象的Mark Word是否指向目前線程的棧幀,如果是,說明目前線程已經擁有了這個對象的鎖,那直接進入同步塊繼續執行就可以了,否則就說明這個鎖對象已經被其他線程搶占了。如果出現兩條以上的線程争用同一個鎖的情況,那輕量級鎖就不再有效,必須要膨脹為重量級鎖,鎖标志的狀态值變為“10”,此時Mark Word中存儲的就是指向重量級鎖(互斥量)的指針,後面等待鎖的線程也必須進入阻塞狀态。
解鎖過程:
它的解鎖過程也同樣是通過CAS操作來進行的,如果對象的Mark Word仍然指向線程的鎖記錄,那就用CAS操作把對象目前的Mark Word和線程中複制的Displaced Mark Word替換回來。假如能夠成功替換,那整個同步過程就順利完成了;如果替換失敗,則說明有
其他線程嘗試過擷取該鎖,就要在釋放鎖的同時,喚醒被挂起的線程。
輕量級鎖對象頭示例:
public class Test {
private boolean flag = false;
public static void main(String[] args) {
Test test = new Test();
synchronized (test) {
System.out.println(ClassLayout.parseInstance(test).toPrintable());
}
}
} com.francis.juc.juc.sync.Test object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) c8 f2 a7 02 (11001000 11110010 10100111 00000010) (44561096)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 1 boolean Test.flag false
13 3 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total 第一行: 11001000 最後兩位00表示輕量級鎖。
鎖膨脹過程:
5.偏向鎖
偏向鎖也是JDK 6中引入的一項鎖優化措施,它的目的是消除資料在無競争情況下的同步原語,進一步提高程式的運作性能。如果說輕量級鎖是在無競争的情況下使用CAS操作去消除同步使用的互斥量,那偏向鎖就是在無競争的情況下把整個同步都消除掉,連CAS操作都不去做了。
偏向鎖中的“偏”,就是偏心的“偏”、偏袒的“偏”。它的意思是這個鎖會偏向于第一個獲得它的線程,如果在接下來的執行過程中,該鎖一直沒有被其他的線程擷取,則持有偏向鎖的線程将永遠不需要再進行同步。
如果讀者了解了前面輕量級鎖中關于對象頭Mark Word與線程之間的操作過程,那偏向鎖的原理就會很容易了解。假設目前虛拟機啟用了偏向鎖(啟用參數-XX:+UseBiased Locking,這是自JDK 6起HotSpot虛拟機的預設值),那麼當鎖對象第一次被線程擷取的時候,虛拟機将會把對象頭中的标志位設定為“01”、把偏向模式設定為“1”,表示進入偏向模式。同時使用CAS操作把擷取到這個鎖的線程的ID記錄在對象的Mark Word之中。如果CAS操作成功,持有偏向鎖的線程以後每次進入這個鎖相關的同步塊時,虛拟機都可以不再進行任何同步操作(例如加鎖、解鎖及對Mark Word的更新操作等)。
一旦出現另外一個線程去嘗試擷取這個鎖的情況,偏向模式就馬上宣告結束。根據鎖對象目前是否處于被鎖定的狀态決定是否撤銷偏向(偏向模式設定為“0”),撤銷後标志位恢複到未鎖定(标志位為“01”)或輕量級鎖定(标志位為“00”)的狀态,後續的同步操作就按照上面介紹的輕量級鎖那樣去執行。偏向鎖、輕量級鎖的狀态轉化及對象Mark Word的關系如圖所示:
偏向鎖對象頭示例:
public class Test {
private boolean flag = false;
public static void main(String[] args) throws InterruptedException {
// 偏向鎖在 JDK 1.6 以上,預設開啟,程式啟動大概4秒左右才會被激活
// 可使用 JVM 參數 -XX:BiasedLockingStartupDelay=0 來關閉延遲
Thread.sleep(5000);
Test test = new Test();
synchronized (test) {
System.out.println(ClassLayout.parseInstance(test).toPrintable());
}
}
} com.francis.juc.juc.sync.Test object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 38 8d 02 (00000101 00111000 10001101 00000010) (42809349)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 1 boolean Test.flag false
13 3 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total 第一行: 00000101 後三位101表示偏向鎖。
-
- 深入了解 JVM 第三版
-