看過我HashMap系列教程的人都應該對HashMap的原理都有了比較深的了解
深入源碼分析HashMap到底是怎樣将元素put進去的
HashMap擴容後,元素是如何重新分布的
”準備用HashMap存1w條資料,構造時傳10000會觸發擴容嗎?“
java的hashmap,如果确定隻裝載100個元素,new HashMap(?)多少是最佳的,why?
讀HashMap源碼之tableSizeFor
大家都知道HashMap是線程不安全的,可是為什麼是不安全的呢?其實我們看一下源碼就知道
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 下面這行代碼在多線程情況下就有可能出問題
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 上述
putVal
方法中,有注釋的那行代碼,在多線程情況下就可能會出現問題
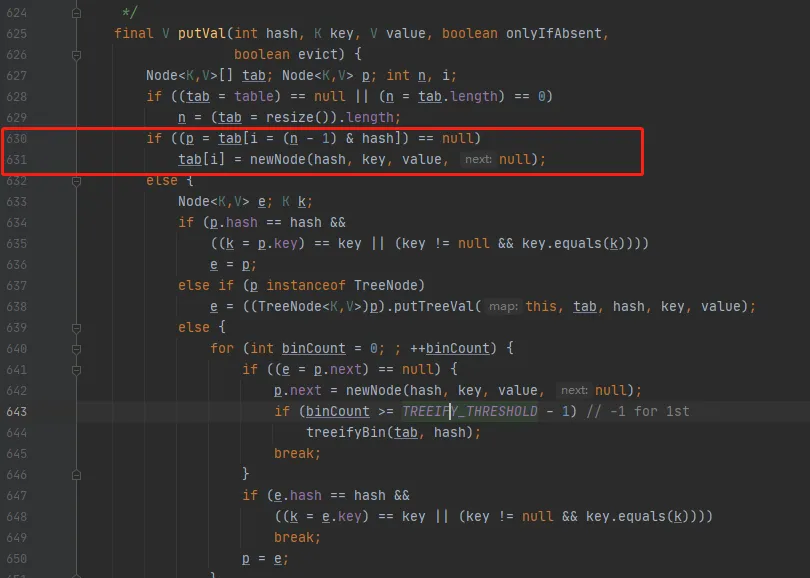
這行代碼的意思是:在進行
(n-1)-1 & hash
後,如果該位置沒有元素,是直接将元素放到這個位置的
如果線程A和線程B同時進行put操作,剛好這兩條不同的資料hash值一樣,并且該位置資料為null
是以接下來線程A、B本應該都會進入源碼
631
行進行執行操作
如果此時,線程A進入後還未進行資料插入時挂起了,沒有擷取到CUP時間片
而線程B正常執行,進而B正常插入資料,放入一個元素,然後執行完了B走了,
此時輪到線程A擷取CPU時間片,在挂起前已經執行了源碼
630
行
線程A将不用再進行hash判斷了,而是直接執行源碼
631
行
杯具來了:線程A會把線程B插入的資料給覆寫,發生線程不安全
針對這個情況怎麼處理呢,可以直接對整個方法加鎖,用
synchronized
,但性能損耗太大
官方推薦使用
ConcurrentHashMap
,采用分段鎖機制,即避免了線程不安全,也極大照顧了性能損耗
