生活中所受的苦,終會以一種形式回歸!
前言
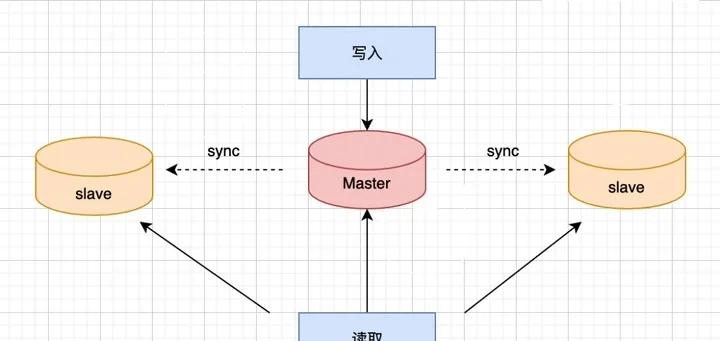
在實際的生産環境中,由單台MySQL作為獨立的資料庫是完全不能滿足實際需求的,無論是在安全性,高可用性以及高并發等各個方面
是以,一般來說都是通過叢集主從複制(Master-Slave)的方式來同步資料,再通過讀寫分離(MySQL-Proxy)來提升資料庫的并發負載能力進行部署與實施
總結MySQL主從叢集帶來的作用是:
- 提高資料庫負載能力,主庫執行讀寫任務(增删改),備庫僅做查詢。
- 提高系統讀寫性能、可擴充性和高可用性。
- 資料備份與容災,備庫在異地,主庫不存在了,備庫可以立即接管,無須恢複時間。
說到主從同步,離不開binlog這個東西,先介紹下binlog吧
biglog
binlog是什麼?有什麼作用?
用于記錄資料庫執行的寫入性操作(不包括查詢)資訊,以二進制的形式儲存在磁盤中。可以簡單了解為記錄的就是sql語句
binlog 是 mysql 的邏輯日志,并且由
Server
層進行記錄,使用任何存儲引擎的 mysql 資料庫都會記錄 binlog 日志
在實際應用中, binlog 的主要使用場景有兩個:
- 用于主從複制,在主從結構中,binlog 作為操作記錄從 master 被發送到 slave,slave伺服器從 master 接收到的日志儲存到 relay log 中。
- 用于資料備份,在資料庫備份檔案生成後,binlog儲存了資料庫備份後的詳細資訊,以便下一次備份能從備份點開始。
日志格式
binlog 日志有三種格式,分别為 STATMENT 、 ROW 和 MIXED
在 MySQL 5.7.7 之前,預設的格式是 STATEMENT , MySQL 5.7.7 之後,預設值是 ROW
日志格式通過
binlog-format
指定。
- STATMENT :基于 SQL 語句的複制,每一條會修改資料的sql語句會記錄到 binlog 中
- ROW :基于行的複制
- MIXED :基于 STATMENT 和 ROW 兩種模式的混合複制,比如一般的資料操作使用 row 格式儲存,有些表結構的變更語句,使用 statement 來記錄
我們還可以通過mysql提供的檢視工具mysqlbinlog檢視檔案中的内容,例如
mysqlbinlog mysql-bin.00001 | more binlog檔案大小和個數會不斷的增加,字尾名會按序号遞增,例如
mysql-bin.00002
等。
主從複制原理

可以看到mysql主從複制需要三個線程:master(binlog dump thread)、slave(I/O thread 、SQL thread)
- binlog dump線程:
- I/O線程:
- SQL線程:
基本過程總結
- 主庫寫入資料并且生成binlog檔案。該過程中MySQL将事務串行的寫入二進制日志,即使事務中的語句都是交叉執行的。
- 在事件寫入二進制日志完成後,master通知存儲引擎送出事務。
- 從庫伺服器上的IO線程連接配接Master伺服器,請求從執行binlog日志檔案中的指定位置開始讀取binlog至從庫。
- 主庫接收到從庫的IO線程請求後,其上複制的IO線程會根據Slave的請求資訊分批讀取binlog檔案然後傳回給從庫的IO線程。
- Slave伺服器的IO線程擷取到Master伺服器上IO線程發送的日志内容、日志檔案及位置點後,會将binlog日志内容依次寫到Slave端自身的Relay Log(即中繼日志)檔案的最末端,并将新的binlog檔案名和位置記錄到
master-info
- 從庫伺服器的SQL線程會實時監測到本地Relay Log中新增了日志内容,然後把RelayLog中的日志翻譯成SQL并且按照順序執行SQL來更新從庫的資料。
- 從庫在
relay-log.info
并行複制
在MySQL 5.6版本之前,Slave伺服器上有兩個線程I/O線程和SQL線程。
I/O線程負責接收二進制日志,SQL線程進行回放二進制日志。如果在MySQL 5.6版本開啟并行複制功能,那麼SQL線程就變為了coordinator線程,coordinator線程主要負責以前兩部分的内容
上圖的紅色框框部分就是實作并行複制的關鍵所在
這意味着coordinator線程并不是僅将日志發送給worker線程,自己也可以回放日志,但是所有可以并行的操作傳遞由worker線程完成。
coordinator線程與worker是典型的生産者與消費者模型。
不過到MySQL 5.7才可稱為真正的并行複制,這其中最為主要的原因就是slave伺服器的回放與主機是一緻的即master伺服器上是怎麼并行執行的slave上就怎樣進行并行回放。不再有庫的并行複制限制,對于二進制日志格式也無特殊的要求。
為了相容MySQL 5.6基于庫的并行複制,5.7引入了新的變量
slave-parallel-type
,其可以配置的值有:
- DATABASE:預設值,基于庫的并行複制方式
- LOGICAL_CLOCK:基于組送出的并行複制方式
下面分别介紹下兩種并行複制方式
按庫并行
每個 worker 線程對應一個 hash 表,用于儲存目前正在這個worker的執行隊列裡的事務所涉及到的庫。其中hash表裡的key是資料庫名,用于決定分發政策。該政策的優點是建構hash值快,隻需要庫名,同時對于binlog的格式沒有要求。
但這個政策的效果,隻有在主庫上存在多個DB,且各個DB的壓力均衡的情況下,這個政策效果好。是以,對于主庫上的表都放在同一個DB或者不同DB的熱點不同,則起不到多大效果
組送出優化
該特性如下:
- 能夠同一組裡送出的事務,定不會修改同一行;
- 主庫上可以并行執行的事務,從庫上也一定可以并行執行。
具體是如何實作的:
- 在同一組裡面一起送出的事務,會有一個相同的
commit_id
commit_id+1
commit_id
- 在從庫使用時,相同
commit_id
commit_id
更詳細内容可以去官網看看:https://dev.mysql.com/doc/refman/5.7/en/replication-options-slave.html
下面開始介紹主從延時
主從延遲
主從延遲是怎麼回事?
根據前面主從複制的原理可以看出,兩者之間是存在一定時間的資料不一緻,也就是所謂的主從延遲。
我們來看下導緻主從延遲的時間點:
- 主庫 A 執行完成一個事務,寫入 binlog,該時刻記為T1.
- 傳給從庫B,從庫接受完這個binlog的時刻記為T2.
- 從庫B執行完這個事務,該時刻記為T3.
那麼所謂主從延遲,就是同一個事務,從庫執行完成的時間和主庫執行完成的時間之間的內插補點,即T3-T1。
我們也可以通過在從庫執行
show slave status
,傳回結果會顯示
seconds_behind_master
,表示目前從庫延遲了多少秒。
seconds_behind_master如何計算的?
- 每一個事務的binlog都有一個時間字段,用于記錄主庫上寫入的時間
- 從庫取出目前正在執行的事務的時間字段,跟目前系統的時間進行相減,得到的就是
seconds_behind_master
主從延遲原因
為什麼會主從延遲?
正常情況下,如果網絡不延遲,那麼日志從主庫傳給從庫的時間是相當短,是以T2-T1可以基本忽略。
最直接的影響就是從庫消費中轉日志(relaylog)的時間段,而造成原因一般是以下幾種:
1、從庫的機器性能比主庫要差
比如将20台主庫放在4台機器,把從庫放在一台機器。這個時候進行更新操作,由于更新時會觸發大量讀操作,導緻從庫機器上的多個從庫争奪資源,導緻主從延遲。
不過,目前大部分部署都是采取主從使用相同規格的機器部署。
2、從庫的壓力大
按照正常的政策,讀寫分離,主庫提供寫能力,從庫提供讀能力。将進行大量查詢放在從庫上,結果導緻從庫上耗費了大量的CPU資源,進而影響了同步速度,造成主從延遲。
對于這種情況,可以通過一主多從,分擔讀壓力;也可以采取binlog輸出到外部系統,比如Hadoop,讓外部系統提供查詢能力。
3、大事務的執行
一旦執行大事務,那麼主庫必須要等到事務完成之後才會寫入binlog。
比如主庫執行了一條insert … select非常大的插入操作,該操作産生了近幾百G的binlog檔案傳輸到隻讀節點,進而導緻了隻讀節點出現應用binlog延遲。
是以,DBA經常會提醒開發,不要一次性地試用delete語句删除大量資料,盡可能控制數量,分批進行。
4、主庫的DDL(alter、drop、create)
1、隻讀節點與主庫的DDL同步是串行進行,如果DDL操作在主庫執行時間很長,那麼從庫也會消耗同樣的時間,比如在主庫對一張500W的表添加一個字段耗費了10分鐘,那麼從節點上也會耗費10分鐘。
2、從節點上有一個執行時間非常長的的查詢正在執行,那麼這個查詢會堵塞來自主庫的DDL,表被鎖,直到查詢結束為止,進而導緻了從節點的資料延遲。
5、鎖沖突
鎖沖突問題也可能導緻從節點的SQL線程執行慢,比如從機上有一些select .... for update的SQL,或者使用了MyISAM引擎等。
6、從庫的複制能力
一般場景中,因偶然情況導緻從庫延遲了幾分鐘,都會在從庫恢複之後追上主庫。但若是從庫執行速度低于主庫,且主庫持續具有壓力,就會導緻長時間主從延遲,很有可能就是從庫複制能力的問題。
從庫上的執行,即
sql_thread
更新邏輯,在5.6版本之前,是隻支援單線程,那麼在主庫并發高、TPS高時,就會出現較大的主從延遲。
是以,MySQL自5.7版本後就已經支援并行複制了。可以在從服務上設定
slave_parallel_workers
為一個大于0的數,然後把
slave_parallel_type
參數設定為
LOGICAL_CLOCK
,這就可以了
mysql> show variables like 'slave_parallel%';
+------------------------+----------+
| Variable_name | Value |
+------------------------+----------+
| slave_parallel_type | DATABASE |
| slave_parallel_workers | 0 |
+------------------------+----------+ 怎麼減少主從延遲
主從同步問題永遠都是一緻性和性能的權衡,得看實際的應用場景,若想要減少主從延遲的時間,可以采取下面的辦法:
- 降低多線程大事務并發的機率,優化業務邏輯
- 優化SQL,避免慢SQL,減少批量操作,建議寫腳本以update-sleep這樣的形式完成。
- 提高從庫機器的配置,減少主庫寫binlog和從庫讀binlog的效率差。
- 盡量采用短的鍊路,也就是主庫和從庫伺服器的距離盡量要短,提升端口帶寬,減少binlog傳輸的網絡延時。
- 實時性要求的業務讀強制走主庫,從庫隻做災備,備份。
參考書籍:
- 高性能MySQL
- MySQL技術内幕
原作者:月伴飛魚