傳統系統日志收集的問題
在傳統項目中,如果在生産環境中,有多台不同的伺服器叢集,如果生産環境需要通過日志定位項目的Bug的話,需要在每台節點上使用傳統的指令方式查詢,這樣效率非常底下。
通常,日志被分散在儲存不同的裝置上。如果你管理數十上百台伺服器,你還在使用依次登入每台機器的傳統方法查閱日志。這樣是不是感覺很繁瑣和效率低下。當務之急我們使用集中化的日志管理,例如:開源的syslog,将所有伺服器上的日志收集彙總。
集中化管理日志後,日志的統計和檢索又成為一件比較麻煩的事情,一般我們使用grep、awk和wc等Linux指令能實作檢索和統計,但是對于要求更高的查詢、排序和統計等要求和龐大的機器數量依然使用這樣的方法難免有點力不從心。
查詢指令:
tail -n 300 myes.log | grep 'node-1'
tail -100f myes.log
ELK分布式日志收集系統介紹
ElasticSearch 是一個基于Lucene的開源分布式搜尋伺服器。它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格接口,多資料源,自動搜尋負載等。它提供了一個分布式多使用者能力的全文搜尋引擎,基于RESTful web接口。Elasticsearch是用Java開發的,并作為Apache許可條款下的開放源碼釋出,是第二流行的企業搜尋引擎。設計用于雲計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用友善。
Logstash 是一個完全開源的工具,它可以對你的日志進行收集、過濾、分析,支援大量的資料擷取方法,并将其存儲供以後使用(如搜尋)。說到搜尋,logstash帶有一個web界面,搜尋和展示所有日志。一般工作方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責将收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去。
Kibana 是一個基于浏覽器頁面的Elasticsearch前端展示工具,也是一個開源和免費的工具,Kibana可以為 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以幫助您彙總、分析和搜尋重要資料日志。
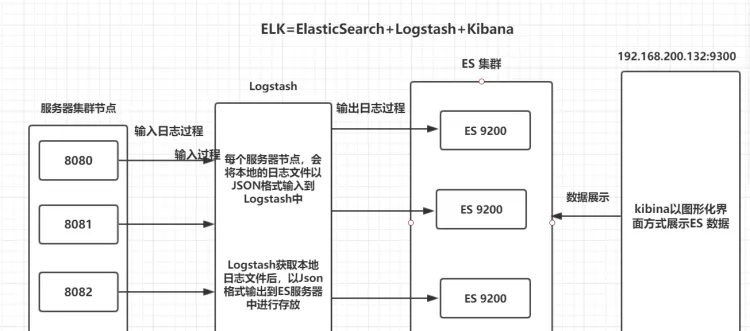
ELK分布式日志收集原理
1、每台伺服器叢集節點安裝Logstash日志收集系統插件
2、每台伺服器節點将日志輸入到Logstash中
3、Logstash将該日志格式化為json格式,根據每天建立不同的索引,輸出到ElasticSearch中
4、浏覽器使用安裝Kibana查詢日志資訊
環境安裝
1、安裝ElasticSearch
2、安裝Logstash
3、安裝Kibana
Logstash介紹
Logstash是一個完全開源的工具,它可以對你的日志進行收集、過濾、分析,支援大量的資料擷取方法,并将其存儲供以後使用(如搜尋)。說到搜尋,logstash帶有一個web界面,搜尋和展示所有日志。一般工作方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責将收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去。 核心流程:Logstash事件處理有三個階段:inputs → filters → outputs。是一個接收,處理,轉發日志的工具。支援系統日志,webserver日志,錯誤日志,應用日志,總之包括所有可以抛出來的日志類型。
Logstash工作原理
Logstash事件處理有三個階段:inputs → filters → outputs。是一個接收,處理,轉發日志的工具。支援系統日志,webserver日志,錯誤日志,應用日志,總之包括所有可以抛出來的日志類型。
logstash:輸入(讀取本地檔案或者連接配接資料庫)、輸出Json 格式。
Input:輸入資料到logstash,再由logstatsh輸出(Json格式)資料到es伺服器上。
一些常用的輸入為:
file:從檔案系統的檔案中讀取,類似于tail -f指令
syslog:在514端口上監聽系統日志消息,并根據RFC3164标準進行解析
redis:從redis service中讀取
beats:從filebeat中讀取
Filters:資料中間處理,對資料進行操作。
一些常用的過濾器為:
grok:解析任意文本資料,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字元串,轉換成為具體的結構化的資料,配合正規表達式使用。内置120多個解析文法。
mutate:對字段進行轉換。例如對字段進行删除、替換、修改、重命名等。
drop:丢棄一部分events不進行處理。
clone:拷貝 event,這個過程中也可以添加或移除字段。
geoip:添加地理資訊(為前台kibana圖形化展示使用)
Outputs:outputs是logstash處理管道的最末端元件。一個event可以在處理過程中經過多重輸出,但是一旦所有的outputs都執行結束,這個event也就完成生命周期。
一些常見的outputs為:
elasticsearch:可以高效的儲存資料,并且能夠友善和簡單的進行查詢。
file:将event資料儲存到檔案中。
graphite:将event資料發送到圖形化元件中,一個很流行的開源存儲圖形化展示的元件。
Codecs:codecs 是基于資料流的過濾器,它可以作為input,output的一部配置設定置。Codecs可以幫助你輕松的分割發送過來已經被序列化的資料。
一些常見的codecs:
json:使用json格式對資料進行編碼/解碼。
multiline:将彙多個事件中資料彙總為一個單一的行。比如:java異常資訊和堆棧資訊。

Logstash環境安裝
1、上傳 logstash 安裝包,我的目錄為 /usr/local/es/
2、解壓 tar –zxvf logstash-6.4.3.tar.gz
3、在config目錄下放入test01.conf、test02.conf 讀入并且讀出日志資訊
示範效果
1、啟動./logstash -f ../config/test01.conf、./logstash -f ../config/test01.conf 分别指的是二個不同的配置檔案,test01 是控制台輸出 沒有添加時間 輸出,test02 是列印了時間。
2、啟動./elasticsearch
3、啟動./kibana Logstash 讀取本地檔案位址,實時存放在ES中,以每天格式建立不同的索引進行存放。
Kibana 平台查詢
GET /es-2019.06.12/_search
test01.conf
input {
# 從檔案讀取日志資訊 輸送到控制台
file {
path => "/usr/local/es/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式讀取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标準輸出
# stdout {}
# 輸出進行格式化,采用Ruby庫來解析日志
stdout { codec => rubydebug }
}
test02.conf
input {
# 從檔案讀取日志資訊 輸送到控制台
file {
path => "/usr/local/es/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式讀取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标準輸出
# stdout {}
# 輸出進行格式化,采用Ruby庫來解析日志
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.200.135:9200"]
#### 建立索引 根據每天建立索引
index => "es-%{+YYYY.MM.dd}"
}
}
ES與Mysql保持資料一緻性原理
logstash包含輸入(讀取本地檔案或者連接配接資料庫)與輸出、過濾器。
如果資料新增或者修改了,ES 與 資料庫如何保持一緻性?
logstash做定時任務(每分鐘查詢一次),定時去mysql查詢資料。
原理:根據updateTime字段作為條件進行查詢。第一次發送Sqli請求的時候,修改時間參數值是為系統最開始的時間是1970年,可以查詢到所有的資料。會将最後一條資料的updateTime記錄下來,作為下一次修改時間的條件進行查詢。
第一次查詢 sql: SELECT * FROM user WHERE update_time >= '1970-01-01 08:00:00'; // updateTime 系統開始時間:1970-01-01 08:00:00
第二次查詢 sql: SELECT * FROM user WHERE update_time >= '2019-07-13 11:15:23';// 2019-07-13 11:15:23 是 第一次查詢的所有資料中,最後一條資料的 updateTime
如下圖:可以看到定時任務查詢的sql,還有定時為1分鐘查一次。
新增資料或者修改資料的時候都會記錄updateTime 時間。