一、Ceph概述
如何選擇存儲
- 底層協定
- 相容性
- 産品要有定位,功能有所取舍
- 針對特定市場的應用存儲
- 被市場認可的存儲系統
- 穩定性是第一位的
- 性能第二
- 資料功能要夠用
一)存儲分類
1、本地存儲
本地的檔案系統,不能在網絡上用。
如:ext3、ext4、xfs、ntfs
2、網絡存儲
網絡檔案系統,共享的是檔案系統
nfs:網絡檔案系統
hdfs、glusterfs:分布式網絡檔案系統
共享的是裸裝置:塊存儲 cinder,ceph(塊存儲、對象存儲、網絡檔案系統-分布式)、SAN(存儲區域網)
二)分布式存儲分類
1、Hadoop HDFS(大資料分布式檔案系統)
HDFS(Hadoop Distributed File System)是一個分布式檔案系統,是Hadoop生态系統的一個重要組成部分,是Hadoop中的存儲元件。HDFS是一個高吞吐量的資料通路,非常适合大規模資料集上的應用。
1)HDFS的優點
- 高容錯性
- 資料自動儲存多個副本
- 副本丢失後,自動恢複
- 良好的資料通路機制
- 一次寫入、多次讀取,保證資料一緻性
- 适合大資料檔案的存儲
- TB、甚至PB級資料
- 擴充能力很強
2)HDFS的缺點
- 低延遲資料通路
- 難以應付毫秒級以下的應用
- 海量小檔案存儲
- 占用NameNode大量記憶體
- 一個檔案隻能一個寫入者
- 僅支援append(追加)
2、OpenStack object storage(Swift)
Swift是OpenStack開源雲計算項目的子項目之一。Swift的目的是使用普通硬體來建構備援的、可擴充的分布式對象存儲叢集,存儲容量可達PB級。Swift的是Python開發
1)Swift的主要特點
- 各個存儲的節點完全對等,是對稱的系統架構
- 開發者通過一個restful http api與對象存儲系統互相作用
- 無單點故障:Swift的中繼資料存儲是完全均勻随機分布的,并且與對象檔案存儲一樣,中繼資料也會存儲多份。整個Swift叢集中,也沒有一個角色是單點的
- 在不影響性能的情況下,叢集通過增加外部節點進行擴充
- 無限的可擴充性:這裡的擴充性分兩方面:一是資料存儲容量無限可擴充了;二是Swift性能(如QPS、吞吐量等)可線性提升,擴容隻需簡單地新增機器,系統會自動完成資料遷移等工作,使各存儲及诶點重新達到平衡狀态
- 極高的資料持久性
2)Swift可以用一下用途
- 圖檔、文檔存儲
- 長期儲存的日志檔案
- 存儲媒體庫(圖檔、音樂、視訊等)
- 視訊監控檔案的存檔
總結:Swift适合用來存儲大量的、長期的、需要備份的對象
3、公有雲對象存儲
公有雲大都隻有對象存儲。例如,谷歌雲存儲是一個快速,具有可擴充性和高可用性的對象存儲。
AWS的s3,阿裡雲的對象存儲oss等等
4、GlusterFS
GlusterFS是一種全對稱的開源分布式檔案系統,所謂全對稱是指GlusterFS采用彈性雜湊演算法,沒有中心節點,所有節點全部平等。GlusterFS配置友善,穩定性好,可輕松達到PB級容量,數千個節點。
PB級容量 高可用性 基于檔案系統級别共享 分布式 去中心化
基本類型:條帶、複制、哈希
複合卷:就是分布式複制、分布式條帶、分布式條帶複制卷,像分布式複制,分布式條帶這兩個是比較常用的,像分布式條帶複制卷三種揉一塊的用的都比較少。
各種卷的整理:
- 分布卷:存儲資料時,将檔案随機存儲到各台glusterfs機器上
- 優點:存儲資料時,讀取速度快
- 缺點:一個birck壞掉,檔案就會丢失
- 複制卷:存儲資料時,所有檔案分别存儲到每台flusterfs機器上
- 優點:對檔案進行的多次備份,一個brick壞掉,檔案不會丢失,其他機器的brick上面有備份
- 缺點:占用資源
- 條帶卷:存儲資料時,換一個檔案分開存到每台glusterfs機器上
- 優點:對大檔案,讀寫速度快
- 缺點:一個brick壞掉,檔案就會壞掉
5、ceph
三)分布式存儲系統的特性
1、可擴充
分布式存儲系統可以擴充到幾百台甚至幾千台的叢集規模,而且随着叢集規模的增長,系統整體性能表現為線性增長。分布式存儲的水準擴充有以下特性:
- 節點擴充後,舊資料會自動遷移到新節點,實作負載均衡,避免單點過熱的情況出現
- 水準擴充隻需将新節點和原有叢集連接配接到同一網絡,整個過程不會對業務造成影響
- 當節點被添加到叢集,叢集系統的整體容量和性能也随之線性擴充,伺候新節點的資源就會被平台管理,被用于配置設定或者回收
2、低成本
分布式存儲系統的自動容錯、自動負載均衡機制使其可以建構在普通的PC機之上。另外,線性擴充能力也使得增加、減少機器非常友善,可以實作自動運維。
3、高性能
無論是針對整個叢集還是單台伺服器,都要求分布式存儲系統具備高性能。
4、易用
分布式存儲系統需要能夠提供易用的對外接口,另外,也要求具備完善的監控、運維工具,并能夠與其他系統內建。
5、易管理
可通過一個簡單的WEB界面就可以對整個系統進行配置管理,運維簡便,極低的管理成本。
分布式存儲系統的挑戰主要在于資料、狀态資訊和持久化,要求在自動遷移、自動容錯、并發讀寫的過程中保證資料的一緻性。分布式存儲涉及的技術主要來自兩個領域:分布式系統以及資料庫。
四)Ceph介紹
軟體定義存儲 (SDS) 利用基于軟體的方法管理資料存儲,并提供基于政策的資料層控制,獨立于底層的存儲硬體。
S3 Client:S3cmd http://s3tools.org/download
用于監控的ceph-dash管理控制台:https://github.com/Crapworks/ceph-dash
OpenStack RDO:http://rdo.fedorapeople.org/rdo-release.rpm
1、Ceph概要
Ceph是一個開源項目,他提供軟體定義的、統一的存儲解決方案。Ceph是一個可大規模擴充、高性能并且無單點故障的分布式存儲系統。從一開始他就運作在通用商用硬體上,具有高度可伸縮性,容量可擴充至EB級别,甚至高大。
Ceph正變成一個流行的雲存儲解決方案。雲依賴于商用硬體,而Ceph能和否充分利用商用硬體為你提供一個企業級、穩定、高度可伸縮性.
Ceph為企業提供了傑出的性能,無線的擴充性,強大并且靈活的存儲産品,進而幫助他們擺脫了昂貴的專用存儲。Ceph是一個運作與商用硬體之上的企業級、軟體定義、統一存儲解決方案,這也使得它成為最具成本效益而且功能多樣的存儲系統。
Ceph存儲系統在同一個底層架構上提供了塊、檔案和對象存儲,使得使用者可以自主選擇需要的存儲方式。
我們無法停止資料的生成,但需要縮小資料生成和資料存儲之間的差距
2、Ceph的架構在設計之初就包含下面的特性:
- 所有的元件必須可擴充
- 不能存在單點故障
- 解決方案必須是軟體定義的、開源的的并且可适用
- Ceph軟體應該運作在通用商用硬體上。
- Ceph所有元件必須盡可能自我管理
3、ceph的好處
對象是Ceph的基礎,也就是它的基本存儲單元。任何格式的資料,不管是塊、對象還是檔案,都是以對象的形式儲存在Ceph叢集的歸置組(Placement Group,PG)中。
- 滿足現在和将來對于非結構化資料存儲的需求
- 可以将平台和硬體獨立分開
- 智能地處理對象,可以為每個對象都建立叢集副本以提高其高可靠性
- 由于沒有實體存儲路徑綁定,使得對象非常靈活并且與為之無關:使得資料的量級能夠近線性地從PB級别擴充到EB級别
4、ceph核心元件及概念介紹
Ceph支援對象存儲(RADOSGW)、塊存儲(RBD)和檔案存儲(CephFS)。一個Ceph存儲叢集至少包含一個Ceph monitor、Ceph manager及Ceph OSD(Object Store Daemon)。若要運作CephFS client,還需要Ceph metadata server。以下是Ceph的整體架構圖:
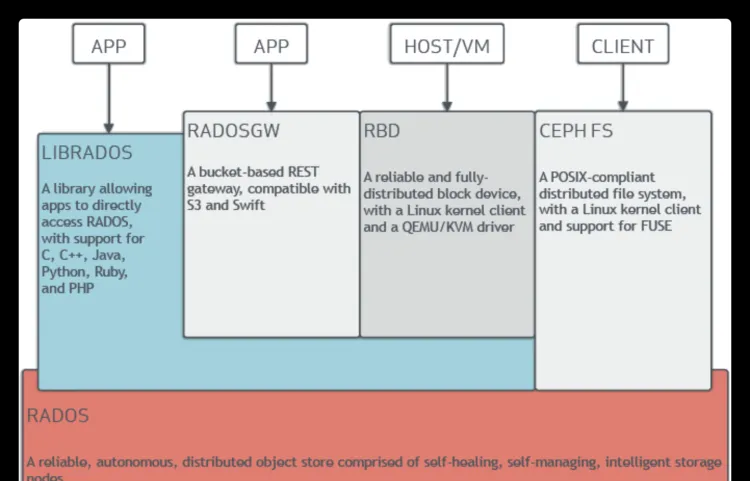
1)OSD:ceph OSD 存儲
Ceph OSD:OSD的英文全稱是Object Storage Device,它的主要功能是存儲資料、複制資料、平衡資料、恢複資料等,與其它OSD間進行心跳檢查等,并将一些變化情況上報給Ceph Monitor。一般情況下一塊硬碟對應一個OSD,由OSD來對硬碟存儲進行管理,當然一個分區也可以成為一個OSD。
Ceph OSD的架構實作由實體磁盤驅動器、Linux檔案系統和Ceph OSD服務組成,對于Ceph OSD Deamon而言,Linux檔案系統顯性的支援了其拓展性,一般Linux檔案系統有好幾種,比如有BTRFS、XFS、Ext4等,BTRFS雖然有很多優點特性,但現在還沒達到生産環境所需的穩定性,一般比較推薦使用XFS。
伴随OSD的還有一個概念叫做Journal盤,一般寫資料到Ceph叢集時,都是先将資料寫入到Journal盤中,然後每隔一段時間比如5秒再将Journal盤中的資料重新整理到檔案系統中。一般為了使讀寫時延更小,Journal盤都是采用SSD,一般配置設定10G以上,當然配置設定多點那是更好,Ceph中引入Journal盤的概念是因為Journal允許Ceph OSD功能很快做小的寫操作;一個随機寫入首先寫入在上一個連續類型的journal,然後重新整理到檔案系統,這給了檔案系統足夠的時間來合并寫入磁盤,一般情況下使用SSD作為OSD的journal可以有效緩沖突發負載。
2)MON:Ceph Monitor 監控叢集
Ceph Monitor:由該英文名字我們可以知道它是一個螢幕,負責監視Ceph叢集,維護Ceph叢集的健康狀态,同時維護着Ceph叢集中的各種Map圖,比如OSD Map、Monitor Map、PG Map和CRUSH Map,這些Map統稱為Cluster Map,Cluster Map是RADOS的關鍵資料結構,管理叢集中的所有成員、關系、屬性等資訊以及資料的分發,比如當使用者需要存儲資料到Ceph叢集時,OSD需要先通過Monitor擷取最新的Map圖,然後根據Map圖和object id等計算出資料最終存儲的位置。
3)MDS:源資料管理
Ceph MDS:全稱是Ceph MetaData Server,主要儲存的檔案系統服務的中繼資料,但對象存儲和塊儲存設備是不需要使用該服務的。
4)MGR:manger 管理叢集
用于收集ceph叢集狀态、運作名額,比如存儲使用率、目前性能名額和系統負載。對外提供ceph dashboard(ceph ui)和restful api。manager元件開啟高可用時,至少2個。
5)RGW:RADOS網關

rgw運作于librados之上,事實上就是一個稱之為Civetweb的web伺服器來響應api請求
用戶端使用标準api與rgw通信,而rgw則使用librados與ceph叢集通信
rgw用戶端通過s3或者swift api使用rgw使用者進行身份驗證。然後rgw網關代表使用者利用cephx與ceph存儲進行身份驗證
6)object
ceph最底層的存儲單元是object對象,每個object包含中繼資料和原始資料。
7)PG
PG全稱Placement Groups,是一個邏輯的概念,一個PG包含多個OSD。引入PG這一層其實是為了更好的配置設定資料和定位資料。
分布式存儲Ceph之PG狀态詳解:https://mp.weixin.qq.com/s?__biz=MzIyNTIyNzE0Ng==&mid=2247485152&idx=1&sn=4a9ee34e4d16ed67cd9eed884f1b7504&chksm=e803be05df7437132e197f28a5194c229f50d904332962e801c7b46e412058ee7eb42b3f3c9c&mpshare=1&scene=23&srcid=0710Tq3Pmx5WYpWilnFnLmq8#rd
8)RADOS
RADOS全稱Reliable Autonomic Distributed Object Store 是ceph叢集的精華,永華實作資料配置設定、Failover等叢集操作
9)CephFS
CephFS全稱Ceph File System是ceph對外提供的檔案系統服務。它使用ceph存儲叢集來存儲資料。ceph檔案系統與ceph塊裝置、同時提供s3和Swift api的ceph對象存儲、或者原生庫(librados)一樣,都使用着相同的ceph存儲叢集系統。
5、CRUSH算法
- 在背景計算存儲和讀取的位置,而不是為每個用戶端請求執行中繼資料表的查找
- 通過動态計算中繼資料,也就是不需要管理一個集中式的中繼資料表
- 利用分布式存儲的功能可以将一個大的計算負載分布到叢集中的多個節點,crush清晰的中繼資料管理方法比傳統存儲的更好
- 獨特的基礎感覺能力。使用者在ceph的crush map中可以自由地為他的基礎設施定義故障區域(可以在自己的環境中高效地管理他們的資料)
- crush使得ceph能夠自我管理和自我治愈(為因故障而丢失的資料執行恢複操作)
五)企業裡的典型場景
1、高性能場景
亮點在于它在低TCO下每秒擁有最高的IOPS。
典型的做法是使用包含了更快的SSD硬碟、PCIe SSD、NVMe做資料存儲的高性能節點。
通常用于塊存儲,也可以用在高IOPS的工作負載上。
2、通用場景
亮點在于高吞吐量和每吞吐量的低功耗。
通常的做法是擁有一個高帶寬、實體隔離的雙重網絡,使用SSD和PCIe SSD做OSD日志盤。
這種方法常用于塊存儲,若你的應用場景需要高性能的對象存儲和檔案存儲,也可以考慮使用。
3、大容量場景
亮點在于資料中心每TB存儲的低成本,以及機架單元實體空間的低成本。也被成為經濟存儲、廉價存儲、存儲/長期存儲。
通用的做法是使用插滿機械硬碟的密集伺服器,一般是8-14台伺服器,每台伺服器24-72TB的實體硬碟空間,
通常用于低功耗、大存儲容量的對象存儲和檔案存儲。
二、Ceph部署
一)ceph-deploy部署ceph
http://www.xuxiaopang.com/2020/10/09/list/
二)cephadm部署ceph
三)rook部署ceph到kubernetes中
https://www.rook.io/docs/rook/v1.7/ceph-storage.html
1、架構
- monitor叢集
- mgr叢集
- osd叢集
- pool管理
- 對象存儲
- 檔案存儲
- 監視和維護叢集狀态
- rook負責提供通路存儲所需的驅動
- Flex驅動(舊驅動,不建議使用)
- CSI驅動
- RBD塊存儲
- CephFS檔案存儲
- S3/Swift風格對象存儲
- mon
- rgw
- mds
- osd
- agent
- csi-rdbplugin
- csi-cephfsplugin
- 抽象化管理,隐藏細節
- pool
- volumes
- filesystems
- buckets
2、部署ceph
三、ceph性能調優介紹和硬體選型
一)硬體選型
- 把握一個原則:ceph的硬體選型需要根據存儲需求和企業的使用場景來制定
- 企業渴望什麼需要什麼:TCO低、高性能、高可靠
- 一般企業使用ceph的曆程:硬體選型——部署調優——性能測試——架構災備涉及——部分業務上限測試——運作維護(故障處理、預案演練等)
https://docs.ceph.com/en/pacific/start/hardware-recommendations/
Ceph OSD運作RADOS服務,需要通過CRUSH來計算資料的存放位置,複制資料,以及Cluster Map的拷貝。
通常建議每個OSD程序至少有一個CPU核。
- 硬體規劃:CPU、記憶體、網絡
- SSD選擇:在預算足夠的情況下,推薦使用PCIE SSD,這樣性能會得到進一步提升,延遲有很大的改善。
- BIOS設定:超線程,關閉節能
- NUMA設定:建議關閉。若要用可以通過cgroup将ceph-osd進行與某一個CPU Core以及同一個Node下的記憶體進行綁定。
二)系統層面
1、Linux Kernel
IO排程:使用Noop排程器替代核心預設的CFQ https://bbs.huaweicloud.com/forum/thread-113451-1-1.html
btrfs cfq, noop, deadline三種IO排程政策
預讀:read_ahead_kb建議設最大值
程序:pid_max設最大值;調整CPU頻率,使其運作在最大性能下
2、記憶體
SMP和NUMA
SWAP:vm_swappiness=0
全閃存支援:增加TCmalloc的Cache大小或者使用jemalloc替代TCmalloc
3、Cgroup
- 在對程式做CPU綁定或者使用Cgroup進行隔離時,注意不要跨CPU,以便更好地命中記憶體和緩存
- ceph程序和其他程序會互相搶占資源,使用Cgroup做好隔離措施
- 為Ceph程序預留足夠多的CPU和記憶體資源,防止影響性能
三)網絡層面
1、巨型幀
以太網的MTU是1500位元組,預設情況下以太網幀是1522位元組 = 1500(payload)+14(Ethernet header)+4(CRC)+4(VLAN tag)
巨型幀是将MTU調整到9000,進而通過減少網絡中資料包的個數來減輕網絡裝置處理標頭的額外開銷,可以極大地提高性能。
設定MTU,需要本地裝置和對端裝置同時開啟,可以極大提高性能。
2、中斷親和
進行網絡IO時,會出發系統中斷。預設情況下,所有的網卡中斷都交由CPU0處理。
當大量網絡IO出現時,處理大量網絡IO會導緻CPU0長時間處于滿負載狀态,以緻無法處理更多的IO導緻網絡丢包等并發問題,産生系統瓶頸。Linux2.4核心之後,引入了将中斷綁定到指定的CPU的技術,稱為中斷親和(SMP IRQ affinity)。Linux中所有的中斷情況在檔案 /proc/interrupts 中記錄。
可以通過 echo "$bitmask" > /proc/irq/$num/smp_affinity
bitmask代表CPU的掩碼,以十六進制表示,每一位代表一個CPU核。 這裡的$num代表中斷号。
但是,這樣手動設定CPU太過麻煩。實際中有 irqbalance 服務會定期(10秒)統計CPU的負載和系統的中斷量,自動遷移中斷,保持負載均衡。
irqbalance 在部分情況下确實能極大減少工作量,但由于它的檢測無法保證明時性,部分情況下會加劇系統負載。
是以,還是建議根據系統規劃,通過手動設定中斷親和,隔離部分CPU處理網卡中斷。
3、硬體加速
主要采取TOE網卡(TCP offload Engine),它主要處理以下工作:
1) 協定處理:對TCP/IP協定的處理,如IP資料包的校驗、TCP資料流的可靠性和一緻性處理。
2) 中斷處理:普通網卡上每個資料包都要觸發一次中斷,TOW網卡讓每個應用程式完成一次完整的資料處理後才觸發一次中斷。
3) 減少記憶體拷貝:因為在網卡内進行協定處理,是以不必将資料複制到核心緩沖區,而是直接複制到應用程式的緩沖區。
4、RDMA (Remote Direct Memory Access)
RDMA可以在不需要作業系統的幹預下,完成2個主機之間記憶體資料的傳輸。
RDMA工作過程中,應用程式與網卡直接互傳資料,中間不經過核心緩沖區。
RDMA在Ceph中主要由Mellanox維護,使用accelio實作了類似SampleMessager的xio消息處理機制。
5、DPDK (Data Plane Development Kit)
DPDK采用輪詢方式處理資料包處理過程,而不是使用CPU中斷處理資料包的方式。
DPDK重載了網卡驅動,驅動在收到資料包後,不使用中斷通知CPU,而是直接存入使用者态記憶體中,使得應用程式可以通過DPDK提供的接口從記憶體中直接讀取資料包。
使用DPDK類似于RDMA,避免了記憶體拷貝和上下文切換的時間。
四)Ceph層面優化
1、各種參數的配置
大緻有:global參數、journal相關參數、osd config tuning參數、recovery tuning參數、client tuning參數
2、PG數量優化
Total PGs = (osd number * [100-200]) / replica_number
即,osd的數量乘以100到200之間的一個數值(如果pool比較多,則乘以200),再除以副本數。
五)ceph優化之其他雜項
- osd_enable_op_tracker=false #預設開啟,可以跟蹤op執行時間
- throttler_perf_counter=false #預設開啟,可以觀察門檻值是否是瓶頸
- 當在特定環境調整到最佳性能後,建議關閉,tracker對性能影響較大
- cephx_sign_messages=false #預設開啟,若對安全要求不高,建議關閉
- filestore_fd_cache_size=4096 #預設256
- filestore_fd_cache_shards=256 #預設16,修改後,略有提升
四、ceph運維
一)ceph運維内容概述
1、手冊
- ceph運維手冊
- ceph預案手冊等
2、實操
- 部署ceph
- 進行預案演練
- 故障處理
- 叢集擴容
- 來保證ceph整個叢集的高可用性,確定資料不丢失,同時進行正常故障演練,保證出現故障後能夠有序的進行故障修複
二)雙活與容災
1、雙活場景
已經沒有主和備的角色分别了,是對稱式的,也就是兩邊會互相影響。這種影響,很有可能導緻兩邊一損俱損。
雙活隻會增加運維難度,而不會降低。雙活就得預防腦裂,而“預防腦裂”本身就可能會出各種問題,一旦軟體做的問題不夠健壯,反而會導緻更大的問題甚至腦裂。
2、異地容災
通過網際網路TCP/IP協定,将本地的資料實時備份到異地伺服器中,可以通過異地備份的資料進行遠端恢複,也可以在異地進行資料回退。
3、傳統存儲的雙活
利用虛拟化網關的實作起來,多一層運維比較複雜,現在的趨勢偏向存儲陣列的雙活。
三)ceph日常運維
1、叢集監控管理
1)叢集整體運作狀态
[root@cephnode01 ~]# ceph -s
cluster:
id: 8230a918-a0de-4784-9ab8-cd2a2b8671d0
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 27h)
mgr: cephnode01(active, since 53m), standbys: cephnode03, cephnode02
osd: 4 osds: 4 up (since 27h), 4 in (since 19h)
rgw: 1 daemon active (cephnode01)
data:
pools: 6 pools, 96 pgs
objects: 235 objects, 3.6 KiB
usage: 4.0 GiB used, 56 GiB / 60 GiB avail
pgs: 96 # id:叢集ID
# health:叢集運作狀态,這裡有一個警告,說明是有問題,意思是pg數大于pgp數,通常此數值相等。
# mon:Monitors運作狀态。
# osd:OSDs運作狀态。
# mgr:Managers運作狀态。
# mds:Metadatas運作狀态。
# pools:存儲池與PGs的數量。
# objects:存儲對象的數量。
# usage:存儲的理論用量。
# pgs:PGs的運作狀态 2)常用查詢狀态指令
叢集狀态: HEALTH_OK,HEALTH_WARN,HEALTH_ERR
# 僅僅顯示叢集是否正常
[root@ceph2 ~]#ceph health detail
HEALTH_OK
# 顯示叢集狀态/
[root@ceph2 ~]# ceph -s
cluster:
id: 35a91e48-8244-4e96-a7ee-980ab989d20d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph2,ceph3,ceph4
mgr: ceph4(active), standbys: ceph2, ceph3
mds: cephfs-1/1/1 up {0=ceph2=up:active}, 1 up:standby
osd: 9 osds: 9 up, 9 in; 32 remapped pgs
rbd-mirror: 1 daemon active
data:
pools: 14 pools, 536 pgs
objects: 220 objects, 240 MB
usage: 1764 MB used, 133 GB / 134 GB avail
pgs: 508 active+clean
28 active+clean+remapped
# 動态觀察ceph叢集
[root@ceph2 ~]# ceph -w 3)叢集标志
noup:OSD啟動時,會将自己在MON上辨別為UP狀态,設定該标志位,則OSD不會被自動辨別為up狀态
nodown:OSD停止時,MON會将OSD辨別為down狀态,設定該标志位,則MON不會将停止的OSD辨別為down狀态,設定noup和nodown可以防止網絡抖動
noout:設定該标志位,則mon不會從crush映射中删除任何OSD。對OSD作維護時,可設定該标志位,以防止CRUSH在OSD停止時自動重平衡資料。OSD重新啟動時,需要清除該flag
noin:設定該标志位,可以防止資料被自動配置設定到OSD上
norecover:設定該flag,禁止任何叢集恢複操作。在執行維護和停機時,可設定該flag
nobackfill:禁止資料回填
noscrub:禁止清理操作。清理PG會在短期内影響OSD的操作。在低帶寬叢集中,清理期間如果OSD的速度過慢,則會被标記為down。可以該标記來防止這種情況發生
nodeep-scrub:禁止深度清理
norebalance:禁止重平衡資料。在執行叢集維護或者停機時,可以使用該flag
pause:設定該标志位,則叢集停止讀寫,但不影響osd自檢
full:标記叢集已滿,将拒絕任何資料寫入,但可讀 4)叢集标志操作
a) 設定noout狀态
[root@ceph2 ~]# ceph osd set noout
noout is set b) 取消noout狀态
[root@ceph2 ~]# ceph osd unset noout
noout is unset c) 将指定檔案作為對象寫入到資源池中 put
[root@ceph2 ~]# rados -p ssdpool put testfull /etc/ceph/ceph.conf
2019-03-27 21:59:14.250208 7f6500913e40 0 client.65175.objecter FULL, paused modify 0x55d690a412b0 tid 0
[root@ceph2 ~]# rados -p ssdpool ls
testfull
test 5)PG操作
a) pg狀态
Creating:PG正在被建立。通常當存儲池被建立或者PG的數目被修改時,會出現這種狀态
Active:PG處于活躍狀态。可被正常讀寫
Clean:PG中的所有對象都被複制了規定的副本數
Down:PG離線
Replay:當某個OSD異常後,PG正在等待用戶端重新發起操作
Splitting:PG正在初分割,通常在一個存儲池的PG數增加後出現,現有的PG會被分割,部分對象被移動到新的PG
Scrubbing:PG正在做不一緻校驗
Degraded:PG中部分對象的副本數未達到規定數目
Inconsistent:PG的副本出現了不一緻。如果出現副本不一緻,可使用ceph pg repair來修複不一緻情況
Peering:Perring是由主OSD發起的使用存放PG副本的所有OSD就PG的所有對象和中繼資料的狀态達成一緻的過程。Peering完成後,主OSD才會接受用戶端寫請求
Repair:PG正在被檢查,并嘗試修改被發現的不一緻情況
Recovering:PG正在遷移或同步對象及副本。通常是一個OSD down掉之後的重平衡過程
Backfill:一個新OSD加入叢集後,CRUSH會把叢集現有的一部分PG配置設定給它,被稱之為資料回填
Backfill-wait:PG正在等待開始資料回填操作
Incomplete:PG日志中缺失了一關鍵時間段的資料。當包含PG所需資訊的某OSD不可用時,會出現這種情況
Stale:PG處理未知狀态。monitors在PG map改變後還沒收到過PG的更新。叢集剛啟動時,在Peering結束前會出現該狀态
Remapped:當PG的acting set變化後,資料将會從舊acting set遷移到新acting set。新主OSD需要一段時間後才能提供服務。是以這會讓老的OSD繼續提供服務,直到PG遷移完成。在這段時間,PG狀态就會出現Remapped b) stuck(卡住)狀态的PG
# 如果PG長時間(mon_pg_stuck_threshold,預設為300s)出現如下狀态時,MON會将該PG标記為stuck:
inactive:pg有peering問題
unclean:pg在故障恢複時遇到問題
stale:pg沒有任何OSD報告,可能其所有的OSD都是down和out
undersized:pg沒有充足的osd來存儲它應具有的副本數
預設情況下,Ceph會自動執行恢複,但如果未成自動恢複,則叢集狀态會一直處于HEALTH_WARN或者HEALTH_ERR
如果特定PG的所有osd都是down和out狀态,則PG會被标記為stale。要解決這一情況,其中一個OSD必須要重生,且具有可用的PG副本,否則PG不可用
Ceph可以聲明osd或PG已丢失,這也就意味着資料丢失。
需要說明的是,osd的運作離不開journal,如果journal丢失,則osd停止 c) 管理stuck狀态的PG # 檢查處于stuck狀态的pg
[root@ceph2 ceph]# ceph pg dump_stuck
ok
PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY
17.5 stale+peering [0,2] 0 [0,2] 0
17.4 stale+peering [2,0] 2 [2,0] 2
17.3 stale+peering [2,0] 2 [2,0] 2
17.2 stale+peering [2,0] 2 [2,0] 2
17.1 stale+peering [0,2] 0 [0,2] 0
17.0 stale+peering [2,0] 2 [2,0] 2
17.1f stale+peering [2,0] 2 [2,0] 2
17.1e stale+peering [0,2] 0 [0,2] 0
17.1d stale+peering [2,0] 2 [2,0] 2
17.1c stale+peering [0,2] 0 [0,2] 0
[root@ceph2 ceph]# ceph osd blocked-by
osd num_blocked
0 19
2 13
# 檢查導緻pg一直阻塞在peering 狀态的osd
ceph osd blocked-by
# 檢查某個pg的狀态
ceph pg dump |grep pgid
# 聲明pg丢失
ceph pg pgid mark_unfound_lost revert|delete
# 聲明osd丢失(需要osd狀态為down 且out)
ceph osd lost osdid --yes-i-really-mean-it 6)pool管理
a) 檢視pool狀态
ceph osd pool stats
ceph osd lspools b)限制pool配置更改
# 禁止pool被删除
ceph tell osd.* injectargs --osd_pool_default_flag_nodelete true
# 禁止修改pool的pg_num和pgp_num
ceph tell osd.* injectargs --osd_pool_default_flag_nopgchange true
# 禁止修改pool的size和min_size
ceph tell osd.* injectargs --osd_pool_default_flag_nosizechang true 7)檢視osd狀态
ceph osd stat
ceph osd status
ceph osd dump
ceph osd tree
ceph osd df 8)Monitor 狀态和檢視仲裁狀态
ceph mon stat
ceph mon dump
ceph quorum_status 9)叢集空間用量
ceph df
ceph df 2、叢集配置管理
1)檢視運作配置
ceph daemon {daemon-type}.{id} config show
# ceph daemon osd.0 2)tell子指令格式
# 使用 tell 的方式适合對整個叢集進行設定,使用 * 号進行比對,就可以對整個叢集的角色進行設定。而出現節點異常無法設定時候,隻會在指令行當中進行報錯,不太便于查找。
指令格式:
# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]
指令舉例:
# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1
# daemon-type:為要操作的對象類型如osd、mon、mds等。
# daemon id:該對象的名稱,osd通常為0、1等,mon為ceph -s顯示的名稱,這裡可以輸入*表示全部
# injectargs:表示參數注入,後面必須跟一個參數,也可以跟多個 3)daemon 子指令
# 使用 daemon 進行設定的方式就是一個個的去設定,這樣可以比較好的回報,此方法是需要在設定的角色所在的主機上進行設定。
指令格式:
# ceph daemon {daemon-type}.{id} config set {name}={value}
指令舉例:
# ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false 3、叢集操作
1)操作守護程序
1、啟動所有守護程序
# systemctl start ceph.target
2、按類型啟動守護程序
# systemctl start ceph-mgr.target
# systemctl start ceph-osd@id
# systemctl start ceph-mon.target
# systemctl start ceph-mds.target
# systemctl start ceph-radosgw.target 2)添加和删除OSD
a) 添加 osd
# 格式化磁盤
ceph-volume lvm zap /dev/sd<id>
# 進入到ceph-deploy執行目錄/my-cluster,添加OSD
ceph-deploy osd create --data /dev/sd<id> $hostname b) 删除osd
# 調整osd的crush weight為 0
ceph osd crush reweight osd.<ID> 0.0
# 将osd程序stop
systemctl stop ceph-osd@<ID>
# 将osd設定out
ceph osd out <ID>
# 立即執行删除OSD中資料
ceph osd purge osd.<ID> --yes-i-really-mean-it
# 解除安裝磁盤
umount 3)擴容pg
ceph osd pool set {pool-name} pg_num 128
ceph osd pool set {pool-name} pgp_num 128
# 在更改pool的PG數量時,需同時更改PGP的數量。PGP是為了管理placement而存在的專門的PG,它和PG的數量應該保持一緻。如果你增加pool的pg_num,就需要同時增加pgp_num,保持它們大小一緻,這樣叢集才能正常rebalancing。 4)pool操作
a) 列出存儲池
ceph OSD lspools b) 建立存儲池
# 指令格式:
ceph osd pool create {pool-name} {pg-num} [{pgp-num}]
# 指令舉例:
ceph osd pool create rbd 32 32 c) 設定存儲池配置
指令格式:
# ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
指令舉例:
# ceph osd pool set-quota rbd max_objects 10000 d) 删除存儲池
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it] e) 重命名存儲池
ceph osd pool rename {current-pool-name} {new-pool-name} f) 檢視存儲池統計資訊
rados df g) 給存儲池做快照
ceph osd pool mksnap {pool-name} {snap-name} h) 删除存儲池的快照
ceph osd pool rmsnap {pool-name} {snap-name} i) 擷取存儲池選項值
ceph osd pool get {pool-name} {key} j) 調整存儲池選項值
ceph osd pool set {pool-name} {key} {value}
# size:設定存儲池中的對象副本數,詳情參見設定對象副本數。僅适用于副本存儲池。
# min_size:設定 I/O 需要的最小副本數,詳情參見設定對象副本數。僅适用于副本存儲池。
# pg_num:計算資料分布時的有效 PG 數。隻能大于目前 PG 數。
# pgp_num:計算資料分布時使用的有效 PGP 數量。小于等于存儲池的 PG 數。
# hashpspool:給指定存儲池設定/取消 HASHPSPOOL 标志。
# target_max_bytes:達到 max_bytes 閥值時會觸發 Ceph 沖洗或驅逐對象。
# target_max_objects:達到 max_objects 閥值時會觸發 Ceph 沖洗或驅逐對象。
# scrub_min_interval:在負載低時,洗刷存儲池的最小間隔秒數。如果是 0 ,就按照配置檔案裡的
# osd_scrub_min_interval 。
# scrub_max_interval:不管叢集負載如何,都要洗刷存儲池的最大間隔秒數。如果是 0 ,就按照配置檔案裡的
# osd_scrub_max_interval 。
# deep_scrub_interval:“深度”洗刷存儲池的間隔秒數。如果是 0 ,就按照配置檔案裡的
# osd_deep_scrub_interval 。 k) 擷取對象副本數
ceph osd dump | grep 'replicated size' l)調整pool的副本
# 設定pool的副本數
ceph osd pool set <poolname> size <num>
# 擷取pool的副本數
ceph osd pool get <poolname> size 5)使用者管理
Ceph 把資料以對象的形式存于各存儲池中。Ceph 使用者必須具有通路存儲池的權限才能夠讀寫資料。另外,Ceph 使用者必須具有執行權限才能夠使用 Ceph 的管理指令。
a) 檢視使用者資訊
# 檢視所有使用者資訊
ceph auth list
# 擷取所有使用者的key與權限相關資訊
ceph auth get client.admin
# 如果隻需要某個使用者的key資訊,可以使用pring-key子指令
ceph auth print-key client.admin b) 添加使用者
ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool'
ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool'
ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring
ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' c) 修改使用者權限
# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool'
# ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
# ceph auth caps client.ringo mon ' ' osd ' ' e) 删除使用者
# ceph auth del {TYPE}.{ID}
其中, {TYPE} 是 client,osd,mon 或 mds 的其中一種。{ID} 是使用者的名字或守護程序的 ID 。 6)增加和删除Monitor
一個叢集可以隻有一個 monitor,推薦生産環境至少部署 3 個。 Ceph 使用 Paxos 算法的一個變種對各種 map 、以及其它對叢集來說至關重要的資訊達成共識。建議(但不是強制)部署奇數個 monitor 。Ceph 需要 mon 中的大多數在運作并能夠互相通信,比如單個 mon,或 2 個中的 2 個,3 個中的 2 個,4 個中的 3 個等。初始部署時,建議部署 3 個 monitor。後續如果要增加,請一次增加 2 個。
a) 增加一個monnitor
# ceph-deploy mon create $hostname
注意:執行ceph-deploy之前要進入之前安裝時候配置的目錄。/my-cluster b) 删除monitor
# ceph-deploy mon destroy $hostname
注意: 確定你删除某個 Mon 後,其餘 Mon 仍能達成一緻。如果不可能,删除它之前可能需要先增加一個。 7)ceph故障排除
此時說明部分osd的存儲已經超過門檻值,mon會監控ceph叢集中OSD空間使用情況。如果要消除WARN,可以修改這兩個參數,提高門檻值,但是通過實踐發現并不能解決問題,可以通過觀察osd的資料分布情況來分析原因。
nearfull osds or pools nearfull
a) 配置檔案設定阙值
"mon_osd_full_ratio": "0.95",
"mon_osd_nearfull_ratio": "0.85" b) 自動處理
ceph osd reweight-by-utilization
ceph osd reweight-by-pg 105 c) 手動處理
ceph osd reweight osd.2 0.8 d) 全局處理
ceph mgr module ls
ceph mgr module enable balancer
ceph balancer on
ceph balancer mode crush-compat
ceph config-key set "mgr/balancer/max_misplaced": "0.01" 4、pg狀态和osd 狀态
1)PG狀态概述
一個PG在它的生命周期的不同時刻可能會處于以下幾種狀态中:
Creating(建立中)
在建立POOL時,需要指定PG的數量,此時PG的狀态便處于creating,意思是Ceph正在建立PG。
Peering(互聯中)
peering的作用主要是在PG及其副本所在的OSD之間建立互聯,并使得OSD之間就這些PG中的object及其中繼資料達成一緻。
Active(活躍的)
處于該狀态意味着資料已經完好的儲存到了主PG及副本PG中,并且Ceph已經完成了peering工作。
Clean(整潔的)
當某個PG處于clean狀态時,則說明對應的主OSD及副本OSD已經成功互聯,并且沒有偏離的PG。也意味着Ceph已經将該PG中的對象按照規定的副本數進行了複制操作。
Degraded(降級的)
當某個PG的副本數未達到規定個數時,該PG便處于degraded狀态,例如:
在用戶端向主OSD寫入object的過程,object的副本是由主OSD負責向副本OSD寫入的,直到副本OSD在建立object副本完成,并向主OSD發出完成資訊前,該PG的狀态都會一直處于degraded狀态。又或者是某個OSD的狀态變成了down,那麼該OSD上的所有PG都會被标記為degraded。
當Ceph因為某些原因無法找到某個PG内的一個或多個object時,該PG也會被标記為degraded狀态。此時用戶端不能讀寫找不到的對象,但是仍然能通路位于該PG内的其他object。
Recovering(恢複中)
當某個OSD因為某些原因down了,該OSD内PG的object會落後于它所對應的PG副本。而在該OSD重新up之後,該OSD中的内容必須更新到目前狀态,處于此過程中的PG狀态便是recovering。
Backfilling(回填)
當有新的OSD加入叢集時,CRUSH會把現有叢集内的部分PG配置設定給它。這些被重新配置設定到新OSD的PG狀态便處于backfilling。
Remapped(重映射)
當負責維護某個PG的acting set變更時,PG需要從原來的acting set遷移至新的acting set。這個過程需要一段時間,是以在此期間,相關PG的狀态便會标記為remapped。
Stale(陳舊的)
預設情況下,OSD守護程序每半秒鐘便會向Monitor報告其PG等相關狀态,如果某個PG的主OSD所在acting set沒能向Monitor發送報告,或者其他的Monitor已經報告該OSD為down時,該PG便會被标記為stale。 2)OSD狀态
單個OSD有兩組狀态需要關注,其中一組使用in/out标記該OSD是否在叢集内,另一組使用up/down标記該OSD是否處于運作中狀态。兩組狀态之間并不互斥,換句話說,當一個OSD處于“in”狀态時,它仍然可以處于up或down的狀态。
OSD狀态為in且up
這是一個OSD正常的狀态,說明該OSD處于叢集内,并且運作正常。
OSD狀态為in且down
此時該OSD尚處于叢集中,但是守護程序狀态已經不正常,預設在300秒後會被踢出叢集,狀态進而變為out且down,之後處于該OSD上的PG會遷移至其它OSD。
OSD狀态為out且up
這種狀态一般會出現在新增OSD時,意味着該OSD守護程序正常,但是尚未加入叢集。
OSD狀态為out且down
在該狀态下的OSD不在叢集内,并且守護程序運作不正常,CRUSH不會再配置設定PG到該OSD 五、ceph MDS 性能測試分析
ceph MDS在主處理流程中使用了單線程,這導緻了其單個MDS的性能受到了限制,最大單個MDS可達8k ops/s,CPU使用率達到的 140%左右。但這可能也是ceph MDS的優勢:
- 單線程使内部不用考慮太複雜的鎖機制,能發揮最大的單MDS性能優勢。
- 由于MDS是無狀态的,在單個實體節點可以部署多個MDS來提供并發,進而提高性能。通過上述手動設定負載均衡測試可知:如果負載均衡,性能可以随MDS線性增加。
- 目前MDS的負載均衡實作的不是很好,後續有待提供和改善。目前可以針對具體的應用,手動實作負載均衡,這在某些特定應用場景是可行的。
目前生産環境中,做了大量的長時間測試,Ceph核心用戶端确實可以提供3倍性能,但是還是推薦使用fuse用戶端。在長穩測試中,核心用戶端偶然會有當機的情況,fuse用戶端還比較穩定。
- 測試對象:要區分硬:SSD、RAID、SAN和雲硬碟等,因為他們有不同的特點
- 測試名額:IOPS和MBPS(吞吐率),下面會具體闡述
- 測試工具:Linux下常用Fio、dd工具,rados bench,Windows iometer
- 測試參數:IO大小、尋址空間、隊列深度、讀寫模式和随機/順序模式
- 測試方法:科學合理的測試步驟