√全連接配接 NN :每個神經元與前後相鄰層的每一個神經元都有連接配接關系,輸入是特征,輸出為預測的結果。
參數個數:∑(前層 × 後層 + 後層)
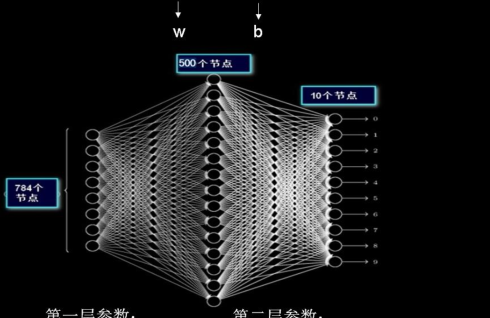
一張分辨率僅僅是 28x28 的黑白圖像,就有近 40 萬個待優化的參數。現實
生活中高分辨率的彩色圖像,像素點更多,且為紅綠藍三通道資訊。
待優化的參數過多,容易導緻模型過拟合為避免這種現象,實際應用中一般不會将原始圖檔直接喂入全連接配接網絡。
√在實際應用中,會先對原始圖像進行特征提取,把提取到的特征喂給全連接配接
網絡,再讓全連接配接網絡計算出分類評估值。

例:先将此圖進行多次特征提取,再把提取後的計算機可讀特征喂給全連接配接
網絡。
√ 卷積 Convolutional
卷積是一種有效提取圖檔特征的方法 。 一般用一個正方形卷積核,周遊圖檔
上的每一個像素點。圖檔與卷積 核 重合區域内 相對應的每一個像素值 乘卷積核
内相對應點的權重,然後求和, 再 加上偏置後,最後得到輸出圖檔中的一個像
素值
例:上面是 5x5x1 的灰階圖檔,1 表示單通道,5x5 表示分辨率,共有 5 行 5
列個灰階值。若用一個 3x3x1 的卷積核對此 5x5x1 的灰階圖檔進行卷積,偏置項
b=1,則求卷積的計算是:(-1)x1+0x0+1x2+(-1)x5+0x4+1x2+(-1)x3+0x4+1x5+1=1(注
意不要忘記加偏置 1)。
輸出圖檔邊長=(輸入圖檔邊長–卷積核長+1)/步長,此圖為:(5 – 3 + 1)/ 1
= 3,輸出圖檔是 3x3 的分辨率,用了 1 個卷積核,輸出深度是 1,最後輸出的是
3x3x1 的圖檔。
√ 全零填充 Padding
有時會在輸入圖檔周圍進行全零填充,這樣可以保證輸出圖檔的尺寸和輸入
圖檔一緻。
例:在前面 5x5x1 的圖檔周圍進行全零填充,可使輸出圖檔仍保持 5x5x1 的
次元。這個全零填充的過程叫做 padding。
輸出資料體的尺寸=(W−F+2P)/S+1
W:輸入資料體尺寸,
F:卷積層中神經元感覺域,
S:步長,
P:零填充的數
量。
例:輸入是 7×7,濾波器是 3×3,步長為 1,填充為 0,那麼就能得到一個 5×5
的輸出。如果步長為 2,輸出就是 3×3。
如果輸入量是 32x32x3,核是 5x5x3,不用全零填充,輸出是(32-5+1)/1=28,
如果要讓輸出量保持在 32x32x3,可以對該層加一個大小為 2 的零填充。可以根
據需求計算出需要填充幾層零。32=(32-5+2P)/1 +1,計算出 P=2,即需填充 2層零。
√**使用 padding 和不使用 padding **
上一行公式是使用 padding 的輸出圖檔邊長,下一行公式是不使用 padding
的輸出圖檔邊長。公式如果不能整除,需要向上取整數。如果用全零填充,也就
是 padding=SAME。如果不用全零填充,也就是 padding=VALID。
√Tensorflow 給出的計算卷積函數
函數中要給出四個資訊:對輸入圖檔的描述、對卷積核的描述、對卷積核滑動步長的描述以及是否使用 padding
1) 對輸入圖檔的描述:用 batch 給出一次喂入多少張圖檔,每張圖檔的分
辨率大小,比如 5 行 5 列,以及這些圖檔包含幾個通道的資訊,如果是灰階圖
則為單通道,參數寫 1,如果是彩色圖則為紅綠藍三通道,參數寫 3。
2) 對卷積核的描述:要給出卷積核的行分辨率和列分辨率、通道數以及用
了幾個卷積核。比如上圖描述,表示卷積核行列分辨率分别為 3 行和 3 列,且是
1 通道的,一共有 16 個這樣的卷積核,卷積核的通道數是由輸入圖檔的通道數
決定的,卷積核的通道數等于輸入圖檔的通道數,是以卷積核的通道數也是 1。
一共有 16 個這樣的卷積核,說明卷積操作後輸出圖檔的深度是 16,也就是輸出
為 16 通道。
3 )對卷積核滑動步長的描述:上圖第二個參數表示橫向滑動步長,第三個
參數表示縱向滑動步長。第一個 1 和最後一個 1 這裡固定的。這句表示橫向縱向
都以 1 為步長。
4 )是否使用padding: :用的是VALID。注意這裡是以字元串的形式給出VALID。
√對多通道的圖檔求卷積
多數情況下,輸入的圖檔是 RGB 三個顔色組成的彩色圖,輸入的圖檔包含了
紅、綠、藍三層資料,卷積核的深度應該等于輸入圖檔的通道數,是以使用 3x3x3
的卷積核,最後一個 3 表示比對輸入圖像的 3 個通道,這樣這個卷積核有三層,
每層會随機生成 9 個待優化的參數,一共有 27 個待優化參數 w 和一個偏置 b。
對于彩色圖,按層分解開,可以直覺表示為上面這張圖,三個顔色分量: 紅色分量、綠色分量和藍色分量。
卷積計算方法和單層卷積核相似,卷積核為了比對紅綠藍三個顔色,把三層
的卷積核套在三層的彩色圖檔上,重合的 27 個像素進行對應點的乘加運算,最
後的結果再加上偏置項 b,求得輸出圖檔中的一個值。
這個 5x5x3 的輸入圖檔加了全零填充,使用 3x3x3 的卷積核,所有 27 個點與
對應的待優化參數相乘,乘積求和再加上偏置 b 得到輸出圖檔中的一個值 6。
針對上面這幅彩色圖檔,用 conv2d 函數實作可以表示為:
一次輸入 batch 張圖檔,輸入圖檔的分辨率是 5x5,是 3 通道的,卷積核是
3x3x3,一共有 16 個卷積核,這樣輸出的深度就是 16,核滑動橫向步長是 1,縱
向步長也是 1,padding 選擇 same,保證輸出是 5x5 分辨率。由于一共用了 16
個卷積核,是以輸出圖檔是 5x5x16。
√池化 Pooling
Tensorflow 給出了計算池化的函數。 最大池化用
tf.nn.max_pool
函數,平均
用 池化用
tf.nn.avg_pool
函數。
函數中要給出四個資訊,對輸入的描述、對池化核的描述、對池化核滑動步
用 長的描述和是否使用 padding
1 )對輸入的描述:給出一次輸入 batch 張圖檔、行列分辨率、輸入通道的個
數。
2) 對池化核的描述:隻描述行分辨率和列分辨率,第一個和最後一個參數
固定是 1。
3 )對池化核滑動步長的描述:隻描述橫向滑動步長和縱向滑動步長,第一
個和最後一個參數固定是 1。
4 )**是否使用 padding **:padding 可以是使用零填充 SAME 或者不使用零填充
VALID。
√舍棄 Dropout
在神經網絡訓練過程中,為了減少過多參數常使用 dropout 的方法,将一部
分神經元按照一定機率從神經網絡中舍棄。這種舍棄是臨時性的,僅在訓練時舍
棄一些神經元;在使用神經網絡時,會把所有的神經元恢複到神經網絡中。比如
上面這張圖,在訓練時一些神經元不參加神經網絡計算了。Dropout 可以有效減
少過拟合。
Tensorflow 提供的 的 dropout 的函數:用 tf.nn.dropout 函數。第一個參數連結
上一層的輸出,第二個參數給出神經元舍棄的機率。
在實際應用中 ,用 常常在前向傳播建構神經網絡時使用 dropout來減小過拟合加快模型的訓練速度。