Lenet 神經網絡是 Yann LeCun 等人在 1998 年提出的,該神經網絡充分考慮圖像
的相關性。
√ Lenet 神經網絡結構為:
①輸入為 32*32*1 的圖檔大小,為單通道的輸入;
②進行卷積,卷積核大小為 5*5*1 ,個數為 6 6 ,步長為 1 ,非全零填充模式;
③将卷積結果通過非線性激活函數;
④進行池化,池化大小為 2*2 ,步長為 1 ,全零填充模式;
⑤進行卷積,卷積核大小為 5*5*6 ,個數為 16 ,步長為 1 ,非全零填充模式;
⑥将卷積結果通過非線性激活函數;
⑦進行池化,池化大小為 2*2 ,步長為 1 ,全零填充模式;
⑧全連接配接層進行 10 分類。
Lenet 神經網絡的結構圖及特征提取過程如下所示:
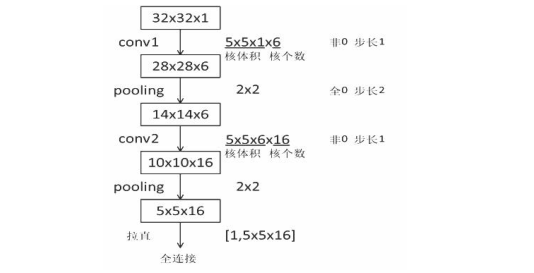
Lenet 神經網絡的輸入是 32*32*1,經過 5*5*1 的卷積核,卷積核個數為 6 個,
采用非全零填充方式,步長為 1,根據非全零填充計算公式:輸出尺寸=(輸入
尺寸-卷積核尺寸+1)/步長=(32-5+1)/1=28.故經過卷積後輸出為 28*28*6。
經過第一層池化層,池化大小為 2*2,全零填充,步長為 2,由全零填充計算公
式:輸出尺寸=輸入尺寸/步長=28/2=14,池化層不改變深度,深度仍為 6。用同
樣計算方法,得到第二層池化後的輸出為 5*5*16。将第二池化層後的輸出拉直
送入全連接配接層。

√ 根據 Lenet 神經網絡的結構可 得, Lenet 神經網絡具有如下特點:
① 卷積( Conv )、池化( ave- - pooling )、非線性激活函數( sigmoid ) 互相交替;
② 層與層之間稀疏連接配接 , 減少計算複雜度 。
√對 對 Lenet 神經網絡進行微調 ,使其适應 M nist 資料集 :
由于 Mnist 資料集中圖檔大小為 28x28x1 的灰階圖檔,而 Lenet 神經網絡的輸入
為 32 x 32x1,故需要對 Lenet 神經網絡進行微調。
①輸入為 28*28*1 的圖檔大小,為單通道的輸入;
②進行卷積,卷積核大小為 5*5*1,個數為 32,步長為 1,全零填充模式;
③将卷積結果通過非線性激活函數;
④進行池化,池化大小為 2*2,步長為 2,全零填充模式;
⑤進行卷積,卷積核大小為 5*5*32,個數為 64,步長為 1,全零填充模式;
⑥将卷積結果通過非線性激活函數;
⑦進行池化,池化大小為 2*2,步長為 2,全零填充模式;
⑧全連接配接層,進行 10 分類。
√ Lenet 神經網絡在 Mnist 資料集上的實作,主要分為三個部分:前向傳播過程
(
mnist_ lenet 5_forward.py
)、反向傳播過程(
mnist_ lenet 5_backword.py
)、
測試過程(
mnist_ lenet 5_test.py
)
第一,前向傳播過程(
mnist_lenet5_forward.py
)實作對網絡中參數和偏置的
初始化、定義卷積結構和池化結構、定義前向傳播過程。具體代碼如下所示:
#coding:utf-8
import tensorflow as tf
IMAGE_SIZE = 28
NUM_CHANNELS = 1
CONV1_SIZE = 5
CONV1_KERNEL_NUM = 32
CONV2_SIZE = 5
CONV2_KERNEL_NUM = 64
FC_SIZE = 512
OUTPUT_NODE = 10
def get_weight(shape, regularizer):
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b = tf.Variable(tf.zeros(shape))
return b
def conv2d(x,w):
return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def forward(x, train, regularizer):
conv1_w = get_weight([CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_KERNEL_NUM], regularizer)
conv1_b = get_bias([CONV1_KERNEL_NUM])
conv1 = conv2d(x, conv1_w)
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
pool1 = max_pool_2x2(relu1)
conv2_w = get_weight([CONV2_SIZE, CONV2_SIZE, CONV1_KERNEL_NUM, CONV2_KERNEL_NUM],regularizer)
conv2_b = get_bias([CONV2_KERNEL_NUM])
conv2 = conv2d(pool1, conv2_w)
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
pool2 = max_pool_2x2(relu2)
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
fc1_w = get_weight([nodes, FC_SIZE], regularizer)
fc1_b = get_bias([FC_SIZE])
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_w) + fc1_b)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
fc2_w = get_weight([FC_SIZE, OUTPUT_NODE], regularizer)
fc2_b = get_bias([OUTPUT_NODE])
y = tf.matmul(fc1, fc2_w) + fc2_b
return y
注釋:
1 )定義前向傳播過程中常用到的參數。
圖檔大小即每張圖檔分辨率為 28*28,故 IMAGE_SIZE 取值為 28;Mnist 資料集
為灰階圖,故輸入圖檔通道數
NUM_CHANNELS
取值為 1;第一層卷積核大小為 5,
卷積核個數為 32,故
CONV1_SIZE
取值為 5,
CONV1_KERNEL_NUM
取值為 32;第二
層卷積核大小為 5,卷積核個數為 64,故
CONV2_SIZE
取值為 5,
CONV2_KERNEL_NUM
為 64;全連接配接層第一層為 512 個神經元,全連接配接層第二層為 10 個神經元,故
FC_SIZE
取值為 512,
OUTPUT_NODE
取值為 10,實作 10 分類輸出。
2 )把前向傳播過程中,常用到的方法定義為函數,友善調用。
在
mnist_lenet5_forward.py
檔案中,定義四個常用函數:權重 w 生成函數、偏
置 b 生成函數、卷積層計算函數、最大池化層計算函數,其中,權重 w 生成函數
和偏置 b 生成函數與之前的定義相同。
√ ① 卷積層計算函數描述如下:
tf.nn.conv2d( 輸入描述[ [ batch, 行分辨率, , 列分辨率, , 通道數] ] ,
卷積核描述[ [ 行分辨率, , 列分辨率, , 通道數, , 卷積核個數] ] ,
核滑動步長 [1, , 行步長, , 列步長, , 1] ,
填充模式 padding
tf.nn.conv2d(x=[100,28,28,1], w=[5,5,1,6], strides=[1,1,1,1],
padding='SAME')
本例表示卷積輸入 x 為 28*28*1,一個 batch_size 為 100,卷積核大小為 5*5,
卷積核個數為 6,垂直方向步長為 1,水準方向步長為 1,填充方式為全零填充。
√ ② 最大池化層計算函數描述如下:
tf .nn.max_pool( 輸入描述[ [ batch, 行分辨率,列分辨率,通道數] ] ,
池化核描述 [1, 行分辨率, , 列分辨率 ,1] ] ,
池化核滑動步長 [1, , 行步長, , 列步長, , 1] ,
填充模式 padding)
tf.nn.max_pool(x=[100,28,28,1],ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding='SAME')
本例表示卷積輸入 x 為 28*28*1,一個 batch_size 為 100,池化核大小用 ksize,
第一維和第四維都為 1,池化核大小為 2*2,垂直方向步長為 1,水準方向步長
為 1,填充方式為全零填充。
3 )定義前向傳播過程
①實作第一層卷積
conv1_w =get_weight([CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,
CONV1_KERNEL_NUM],regularizer)
conv1_b = get_bias([CONV1_KERNEL_NUM])
根據先前定義的參數大小,初始化第一層卷積核和偏置項。
conv1 = conv2d(x, conv1_w)
實作卷積運算,輸入參數為 x 和第一層卷積核參數。
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
第一層卷積的輸出值作為非線性激活函數的輸入值,首先通過
tf.nn.bias_add()
對卷積後的輸出添加偏置,并過
tf.nn.relu()
完成非線性激活。
pool1 = max_pool_2x2(relu1)
根據先前定義的池化函數,将第一層激活後的輸出值進行最大池化。
√
tf.nn.relu()
用來實作非線性激活,相比 d sigmoid 和 和 tanh 函數, relu 函數可
以實作快速的收斂。
②實作第二層卷積
conv2_w =get_weight([CONV2_SIZE,CONV2_SIZE,CONV1_KERNEL_NUM,
CONV2_KERNEL_NUM],regularizer)
conv2_b = get_bias([CONV2_KERNEL_NUM])
初始化第二層卷積層的變量和偏置項,該層每個卷積核的通道數要與上一層
卷積核的個數一緻。
conv2 = conv2d(pool1, conv2_w)
實作卷積運算,輸入參數為上一層的輸出 pool1 和第二層卷積核參數。
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
實作第二層非線性激活函數。
pool2 = max_pool_2x2(relu2)
根據先前定義的池化函數,将第二層激活後的輸出值進行最大池化。
③ 将 第二層 池化層的輸出 2 pool2 矩陣 轉化為全連接配接層的輸入格式 即 向量
pool_shape = pool2.get_shape().as_list()
根據
.get_shape()
函數得到
pool2`` 輸出矩陣的次元,并存入 list 中。其中,
pool_shape[0]```為一個 batch 值。
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
從 list 中依次取出矩陣的長寬及深度,并求三者的乘積,得到矩陣被拉長後的
長度。
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
将 pool2 轉換為一個 batch 的向量再傳入後續的全連接配接。
√get_shape 函數用于擷取一個張量的次元,并且輸出張量每個次元上面的值。 。
例如:
A = tf.random_normal(shape=[3,4])
print A.get_shape()
輸出結果為:(3,4)
④ 實作第三層全連接配接層 :
fc1_w = get_weight([nodes, FC_SIZE], regularizer)
初始化全連接配接層的權重,并加入正則化。
fc1_b = get_bias([FC_SIZE])
初始化全連接配接層的偏置項。
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_w) + fc1_b)
将轉換後的 reshaped 向量與權重 fc1_w 做矩陣乘法運算,然後再加上偏置,最
後再使用 relu 進行激活。
if train: fc1 = tf.nn.dropout(fc1, 0.5)
如果是訓練階段,則對該層輸出使用 dropout,也就是随機的将該層輸出中的一
半神經元置為無效,是為了避免過拟合而設定的,一般隻在全連接配接層中使用。
⑤ 實作第四層全連接配接層的前向傳播過程 :
fc2_w = get_weight([FC_SIZE, OUTPUT_NODE], regularizer)
fc2_b = get_bias([OUTPUT_NODE])
初始化全連接配接層對應的變量。
y = tf.matmul(fc1, fc2_w) + fc2_b
将轉換後的 reshaped 向量與權重 fc2_w 做矩陣乘法運算,然後再加上偏置。
return y
傳回輸出值有,完成整個前向傳播過程,進而實作對 Mnist 資料集的 10 分類。
第二,反向傳播過程(
mnist_lenet5_backward.py
),完成訓練神經網絡的參數。
具體代碼如下所示:
#coding:utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_lenet5_forward
import os
import numpy as np
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.005
LEARNING_RATE_DECAY = 0.99
REGULARIZER = 0.0001
STEPS = 50000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH="./model/"
MODEL_NAME="mnist_model"
def backward(mnist):
x = tf.placeholder(tf.float32,[
BATCH_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE])
y = mnist_lenet5_forward.forward(x,True, REGULARIZER)
global_step = tf.Variable(0, trainable=False)
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name='train')
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
for i in range(STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(
BATCH_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS))
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
if i % 100 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
def main():
mnist = input_data.read_data_sets("./data/", one_hot=True)
backward(mnist)
if __name__ == '__main__':
main()
訓練 Lenet 網絡後,輸出結果如下:
由運作結果可以看出,損失值在不斷減小,且可以實作斷點續訓。
第三,測試過程
(mnist_lenet5_test.py)
,對 Mnist 資料集中的測試資料進行
預測,測試模型準确率。具體代碼如下所示:
#coding:utf-8
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_lenet5_forward
import mnist_lenet5_backward
import numpy as np
TEST_INTERVAL_SECS = 5
def test(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32,[
mnist.test.num_examples,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE])
y = mnist_lenet5_forward.forward(x,False,None)
ema = tf.train.ExponentialMovingAverage(mnist_lenet5_backward.MOVING_AVERAGE_DECAY)
ema_restore = ema.variables_to_restore()
saver = tf.train.Saver(ema_restore)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_lenet5_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
reshaped_x = np.reshape(mnist.test.images,(
mnist.test.num_examples,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS))
accuracy_score = sess.run(accuracy, feed_dict={x:reshaped_x,y_:mnist.test.labels})
print("After %s training step(s), test accuracy = %g" % (global_step, accuracy_score))
else:
print('No checkpoint file found')
return
time.sleep(TEST_INTERVAL_SECS)
def main():
mnist = input_data.read_data_sets("./data/", one_hot=True)
test(mnist)
if __name__ == '__main__':
main()
注釋:
1)在測試程式中使用的是訓練好的網絡,故不使用 dropout,而是讓所有神經
元都參與運算,進而輸出識别準确率。
2)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
Extracting ./data/train-images-idx3-ubyte.gz
Extracting ./data/train-labels-idx1-ubyte.gz
Extracting ./data/t10k-images-idx3-ubyte.gz
Extracting ./data/t10k-labels-idx1-ubyte.gz
INFO:tensorflow:Restoring parameters from ./model/mnist_model-4301
After 4301 training step(s), test accuracy = 0.9717
INFO:tensorflow:Restoring parameters from ./model/mnist_model-4301
After 4301 training step(s), test accuracy = 0.9717
INFO:tensorflow:Restoring parameters from ./model/mnist_model-4301