Kafka-處理請求
broker的大部分工作室處理用戶端、分區副本和控制器發送給分區首領的請求。kafka提供了一個二進制協定(基于TCP),指定了請求消息的格式以及broker如何對請求作出響應--包括成功處理請求或在處理請求過程中遇到錯誤。用戶端發起連接配接并發送請求,broker處理請求并作出響應。broker按照請求到達的順序來處理它們--這種順序保證讓kafka具有了消息隊列的特性,同時保證儲存的消息也是有序的。
所有的請求消息都包含一個标準消息頭:
Request type:也就是API key
Request version:(broker可以處理不同版本的用戶端請求,并根據用戶端版本作出不同的響應)
Correlation ID:一個具有唯一性的數字,用于辨別請求消息,同時也會出現在響應消息和錯誤日志裡(用于診斷問題)
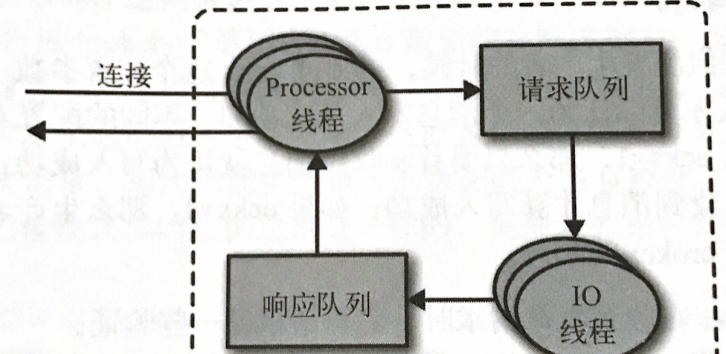
broker會在它所監聽的每一個端口上運作一個Acceptor線程,這個線程會建立一個連接配接,并把它交給processor線程去處理。processor線程(也被叫做網絡線程)的數量是可以配置的。網絡線程負責從用戶端擷取請求消息,把它們放進請求隊列,然後從響應隊列擷取響應消息,把它們發送給用戶端。
請求消息被放到請求隊列後,IO線程會負責處理它們。
生産請求:生産者發送的請求,它包含用戶端要寫入broker的消息。
擷取請求:在消費者和跟随者副本需要從broker讀取消息時發送的請求。
kafka處理請求的内部流程:
生産請求和擷取請求都必須發送給分區的首領副本。如果broker收到一個針對特定分區的請求,而該分區的首領在另一個broker上,那麼發送請求的用戶端會收到一個非分區首領的錯誤響應。當針對特定分區的擷取請求被發送到一個不含有該分區首領的broker上,也會出現同樣的錯誤。kafka用戶端要自己負責把生産請求和擷取請求發送到正确的broker上。
用戶端使用了另一種請求類型,也就是中繼資料請求。這種請求包含了用戶端感興趣的主體清單。伺服器端的響應消息裡指明了這些主題所包含的分區、每個分區都有哪些副本,以及哪個副本是首領。中繼資料請求可以發送給任意一個broker,因為所有broker都緩存了這些資訊。
一般情況下,用戶端會把這些資訊緩存起來,并直接往目标broker上發送生産請求和擷取請求。它們需要時不時地通過發送中繼資料請求來重新整理這些資訊(重新整理的時間間隔通過metadata.max.age.ms參數來配置),進而知道中繼資料是否發生了變化--比如,在新broker加入叢集時,部分副本會被移動到新的broker上。另外,如果用戶端收到非首領錯誤,它會在嘗試重發請求之前先重新整理中繼資料,因為這個錯誤說明了用戶端正在使用過期的中繼資料資訊,之前的請求被發到了錯誤的broker上。

1.生産請求
acks配置參數:指定了需要多少個broker确認才可以認為一個消息寫入是成功的。不同的配置對寫入成功的界定是不一樣的,如果acks=1,那麼隻要首領收到消息就認為寫入成功;如果acks=all,那麼需要所有同步副本收到消息才算寫入成功;如果acks=0,那麼生産者在把消息發出去之後,完全不需要等待broker的響應。
包含首領副本的broker在收到生産請求時,會對請求做一些驗證。
a.發送資料的使用者是否有主題寫入權限。
b.請求裡包含的acks值是否有效(隻允許出現0、1、all)
c.如果acks=all,是否有足夠多的同步副本保證消息已經被安全寫入(我們可以對broker進行配置,如果同步副本的數量不足,broker可以拒絕處理新消息)
之後,消息被寫入本地磁盤。在Linux系統上,消息會被寫到檔案系統緩存裡,并不保證它們何時會被重新整理到磁盤上。kafka不會一直等待資料被寫到磁盤上--它依賴複制功能來保證消息的持久性。
在消息被寫入分區的首領之後,broker開始檢查acks配置參數--如果acks被設為0或1,那麼broker立即傳回響應;如果acks被設為all,那麼請求會被儲存在一個叫做煉獄的緩沖區裡,直到首領發現所有跟随者副本都複制了消息,響應才會被傳回給用戶端。
2.擷取請求
Broker處理擷取請求的方式與處理生産請求的方式很相似。用戶端發送請求,向broker請求主題分區裡具有特定偏移量的消息。用戶端還可以指定broker最多可以從一個分區裡傳回多少資料。這個限制是非常重要的,因為用戶端需要為broker傳回的資料配置設定足夠的記憶體。如果沒有這個限制,broker傳回的大量資料有可能耗盡用戶端的記憶體。
請求需要先到達指定的分區首領上,然後用戶端通過查詢中繼資料來確定請求的路由是正确的。首領在收到請求時,它會先檢查請求是否有效:比如,指定的偏移量在分區上是否存在,如果用戶端請求的是已經被删除的資料,或者請求的偏移量不存在,那麼broker将傳回一個錯誤。
如果請求的偏移量存在,broker将按照用戶端指定的數量上限從分區裡讀取消息,再把消息傳回給用戶端。kafka使用零複制技術向用戶端發送消息:也就是說,kafka直接把消息從檔案(更确切地說是Linux檔案系統緩存)裡發送到網絡通道,而不需要經過任何中間緩沖區。這是kafka與其它大部分資料庫系統不一樣的地方,其它資料庫在将資料發送給用戶端之前會先把它們儲存在本地檔案緩存裡。這項技術避免了位元組複制,也不需要管理記憶體緩沖區,進而獲得更好的性能。
用戶端除了可以設定broker傳回資料的上限,也可以設定下限。例如,如果把下限設定為10KB,就是在告訴broker,等到有10KB資料的時候再發送給用戶端。在主題消息流量不是很大的情況下,這樣可以減少CPU和網絡開銷。用戶端發送一個請求,broker等到有足夠的資料時才把它們傳回給用戶端,然後用戶端再送出請求,而不是讓用戶端每隔幾毫秒就發送一次請求,每次隻能得到很少的資料甚至沒有資料。如下圖所示,來回傳送次數更少,是以開銷更小。
用戶端一直等待broker積累資料也是不現實的,在等待了一段時間之後,就可以把可用的資料拿回處理,而不是一直等下去。是以用戶端可以定義一個逾時時間,告訴broker,如果無法在X毫秒内積累滿足要求的資料量,那麼就把目前這些資料傳回。
并不是所有儲存在分區首領上的資料都可以被用戶端讀取。大部分用戶端隻能讀取已經被寫入所有同步副本的消息(跟随者副本也不行,盡管它們也是消費者--否則複制功能就無法工作)。分區首領知道每個消息會被複制到哪個副本上,在消息還沒有被寫入所有同步副本之前,是不會發送給消費者的--嘗試擷取這些消息的請求會得到空的響應而不是錯誤。