Driver的任務送出過程
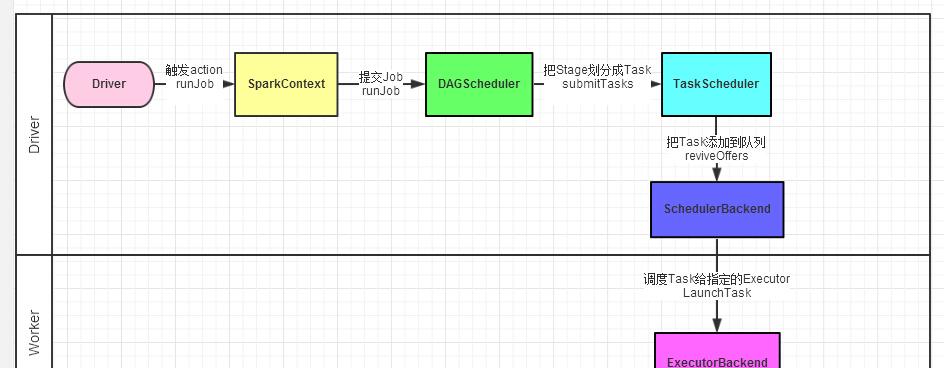
1、Driver程式的代碼運作到action操作,觸發了SparkContext的runJob方法。
2、SparkContext調用DAGScheduler的runJob函數。
3、DAGScheduler把Job劃分stage,然後把stage轉化為相應的Tasks,把Tasks交給TaskScheduler。
4、通過TaskScheduler把Tasks添加到任務隊列當中,交給SchedulerBackend進行資源配置設定和任務排程。
5、排程器給Task配置設定執行Executor,ExecutorBackend負責執行Task。
Spark排程管理
本文主要介紹在單個任務内Spark的排程管理,Spark排程相關概念如下:
- Task(任務):單個分區資料及上的最小處理流程單元。
- TaskSet(任務集):由一組關聯的,但互相之間沒有Shuffle依賴關系的任務所組成的任務集。
- Stage(排程階段):一個任務集對應的排程階段。
- Job(作業):有一個RDD Action生成的一個或多個排程階段所組成的一次計算作業。
- Application(應用程式):Spark應用程式,由一個或多個作業組成。
各概念間的邏輯關系如下圖所示:

Spark的排程管理子產品中,最重要的類是DAGScheduler和TaskScheduler,TaskScheduler負責每個具體任務的實際實體排程,DAGScheduler負責将作業拆分成不同階段的具有依賴關系的多批任務,可以了解為DAGScheduler負責任務的邏輯排程。Spark排程管理示意圖如下:
排程階段的拆分
一個Spark任務送出後,DAGScheduler從RDD依賴鍊末端的RDD出發,周遊整個RDD依賴鍊,将Job分解成具有前後依賴關系的多個stage。DAGScheduler是根據ShuffleDependency劃分stage的,也就是說當某個RDD的運算需要将資料進行shuffle操作時,這個包含了shuffle依賴關系的RDD将被用來作為輸入資訊,建構一個新的排程階段。以此為依據劃分排程階段,可以確定有依賴關系的資料能夠按照正确的順序得到處理和運算。
如何進行Stage劃分?下圖給出的是對應Spark應用程式代碼生成的Stage。它的具體劃分依據是根據RDD的依賴關系進行,在遇到寬依賴時将兩個RDD劃分為不同的Stage。
從上圖中可以看到,RDD G與RDD F間的依賴是寬依賴,是以RDD F與 RDD G被劃分為不同的Stage,而RDD G 與 RDD 間為窄依賴,是以 RDD B 與 RDD G被劃分為同一個Stage。通過這種遞歸的調用方式,将所有RDD進行劃分。
Stage劃分算法
由于Spark的算子建構一般都是鍊式的,這就涉及了要如何進行這些鍊式計算,Spark的政策是對這些算子,先劃分Stage,然後在進行計算。
由于資料是分布式的存儲在各個節點上的,是以為了減少網絡傳輸的開銷,就必須最大化的追求資料本地性,所謂的資料本地性是指,在計算時,資料本身已經在記憶體中或者利用已有緩存無需計算的方式擷取資料。
Stage劃分算法思想
(1)一個Job由多個Stage構成
一個Job可以有一個或者多個Stage,Stage劃分的依據就是寬依賴,産生寬依賴的算子:reduceByKey、groupByKey等等
(2)根據依賴關系,從前往後依次執行多個Stage
SparkApplication 中可以因為不同的Action觸發衆多的Job,也就是說一個Application中可以有很多的Job,每個Job是有一個或者多個Stage構成,後面的Stage依賴前面的Stage,也就是說隻有前面的Stage計算完後,後面的Stage才會運作。
(3)Stage的執行時Lazy級别的
所有的Stage會形成一個DAG(有向無環圖),由于RDD的Lazy特性,導緻Stage也是Lazy級别的,隻有遇到了Action才會真正發生作業的執行,在Action之前,Spark架構隻是将要進行的計算記錄下來,并沒有真的執行。
排程階段的送出
在劃分Stage的步驟中會得到一個或多個有依賴關系的Stage,其中直接觸發作業的RDD關聯的排程階段被稱為FinalStage,DAGScheduler從FinalStage開始生成一個Job。Job和Stage的關系存儲在一個映射表中,用于在該排程階段全部完成時做一些後續處理,如報告狀态、清理作業相關資料等。
具體送出一個Stage時,首先判斷其依賴的所有父Stage的結果是否可用。如果所有父Stage的結果都可用,則送出該Stage。如果有任何一個父Stage的結果不可用,則嘗試疊代送出目前不可用的父Stage。在疊代過程中,父Stage還未運作的Stage都被放到等待隊列中,等待将來被送出。
下圖是一個具有四個排程階段的Job的Stage送出順序:
當一個屬于中間過程排程階段的任務(這種類型的任務所對應的類為ShuffleMapTask)完成後,DAGScheduler會檢查對應排程階段的所有任務是否都完成了。如果完成了,則DAGScheduler将重新掃描一次等待清單中所有的Stage,檢查它們是否還有依賴的Stage沒有完成。如果所有依賴的Stage都已執行完畢,則送出該Stage。
任務結果的擷取
根據任務結果的大小不同,ResultTask傳回的結果分為兩中形式:
- 如果結果足夠小,則直接放在DirectTaskResult對象内。
- 如果超過特定尺寸(預設約10MB),則在Executor端會将DirectTaskResult序列化,将序列化的結果作為一個資料塊存放在BlockManager中,然後将BlockManager傳回的BlockId放在IndirectTaskResult對象中傳回給TaskScheduler,TaskScheduler進而調用TaskResultGetter将IndirectTaskResult中的BlockId取出并通過BlockManager最終取得對應的DirectTaskResult。
轉自:http://www.cnblogs.com/BYRans/