摘要:Serveless計算的目标和機會是讓雲程式設計者像使用進階語言那樣受益。
本文分享自華為雲社群《簡化雲程式設計,伯克利對serverless的看法(翻譯)》,作者: 二手雄獅。
譯者言:
作為了解一個技術最好的方式之一就是對相關論文進行閱讀,比如spark論文,kafka論文,對自己的提升也是非常巨大的,由于一句話中經常涉及巨大的資訊量,是以将論文徹底翻譯為中文,仔細了解閱讀是非常必要的,幾年前我曾經讀過spark論文的英文版,泛泛而看,再加上後續并沒有長期應用,其實已經忘記的差不多了。畢竟自己英文也沒那麼好,如果總看英文版的長篇大論,其實并不是高效的學習方式,倒不如花幾天時間進行論文翻譯加深了解。最後也附了自己的批注希望幫助閱讀者了解。
我在19年翻譯了這篇文章,今天分享希望能夠促進大家對serverless的了解
原文https://www2.eecs.berkeley.edu/Pubs/TechRpts/2019/EECS-2019-3.pdf
Copyright © 2019, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission.
1.介紹
2009年,為了幫助解釋雲計算的好處,“伯克利對雲計算的看法”,闡述了6個潛力優勢:
- 無限的計算資源按需使用的出現
- 消除了雲使用者一線的承諾
- 根據需要短期支付計算資源使用費用的能力。
- 由于許多非常大的資料中心而顯著降低成本的規模經濟。
- 通過資源虛拟化,簡化運維,增加使用率
- 通過複用來自不同組織的工作負載,獲得更高的硬體使用率
在過去十年中這些優勢被大範圍的意識到,但是雲使用者繼續承受 複雜操作和許多工作負載的負擔仍然不能從有效的多路複用中受益。這些不足主要與未能實作最後兩個潛在優勢有關
雲計算免除了使用者的實體基礎設施管理,但留給他們的是要管理的虛拟資源。
複用很适合應用在批量處理的工作負載場景[t1] ,比如map reduce,高性能計算,這種可以充分利用被配置設定的資源的執行個體的場景。但是在有狀态服務中,工作的并不好,比如移植企業級軟體,比如資料庫到雲上運作[t2] 。
2009年,在雲計算虛拟化方法中有兩個互相競争的方法,如論文中所述:
亞馬遜EC2是這一系列産品中的一個,ec2執行個體更像是實體硬體,使用者可以幾乎操作從核心向上的軟體的全棧。而另一個極端的系列是特定領域應用的平台,比如GAE。強制在無狀态計算層和有狀态存儲層間,進行幹淨的分離的應用結構。app engine的令人印象深刻的自動擴充和高可用性機制。。。依賴于這種限制
市場最終擁抱了亞馬遜的低層級的虛拟機方法,去上雲,于是google,微軟等其他雲廠商也提供了類似的接口。我們相信低層級的虛拟機的成功的主要原因是,早期雲計算使用者想要完全重建和他們本地計算一樣的雲環境來簡化移植工作負載的工作量。那是實際的需求,足夠的明智,比起單獨為雲寫新程式優先級更高,尤其是在雲有多成功還不明确的時候。
這個抉擇的缺點是,開發者不得不自己管理虛拟機,基本上通過成為系統管理者或者和系統管理者一起配合,來完成環境安裝。表1列舉操作雲環境必須管理的問題。這一長串低層級虛拟機管理的責任激發了一些有着簡單應用的客戶尋求新應用程式上雲的更容易的路徑。比如,假設
- 為可用性做到備援,這樣一台機器的故障不會導緻服務中斷。
- 在發生災難時保留服務的備援拷貝的地理分布
- 通過負載均衡,請求路由高效利用資源
- 根據負載變化自動伸縮系統
- 監控服務確定他們一直健康地運作
- 記錄日志用于debug和性能調優
- 系統更新,包括安全更新檔
- 在新執行個體可用時遷移到新執行個體。
表1:為雲使用者建立環境需要解決的八個問題。一些問題需要采取許多步驟。比如,自動伸縮需要決定伸縮所需;選擇伺服器的大小和類型,申請伺服器,等待他們上線,在之上配置應用,確定沒有錯誤發生,使用監控工具監控他們,然後發送請求測試他們。
一個應用想要從手機發送圖檔到雲端,雲端應該先建立圖檔縮略圖,把他們放到網站,完成這些任務的代碼可能有幾百行java script代碼,這些開發量比起準備好用來運作它的伺服器的開發量,是可以忽略不計的。
意識到這些需求使得亞馬遜推出了一種新的選擇,叫AWS Lambda。Lambda提供雲函數,為serverless計算吸引了很多的關注。盡管無伺服器計算可以說是一種沖突的說法–你仍然在使用伺服器進行計算–因為它推崇雲使用者隻需編寫代碼并将所有伺服器配置和管理任務留給雲提供商。雲函數被包裝為FaaS提供給使用者,代表着serverless計算的核心,雲平台也提供專門的serverless架構滿足特比定的應用需求作為BaaS提供。簡單來說Serverless計算=FaaS+BaaS
在我們的定義中,要認為服務是無伺服器的,它必須自動地伸縮無需顯式地進行配置,并根據使用情況計費。在剩下的時間裡 本文主要研究雲函數的産生、演變和未來。雲函數在當今無伺服器計算中是一種泛用的元素,并引領着走向簡化和面向雲的泛用程式設計模型。
接下來,我們定義無伺服器計算,就像伯克利對雲計算的看法這篇論文一樣,接着,我們列出如果無伺服器計算要兌現他的承諾,所要解決的挑戰和研究機遇。我們不确定哪種解決方案會勝利,我們相信所有的問題最終都會被解決,使得無伺服器成為雲計算的的門面。
2.無伺服器計算的誕生
在任何serverless平台,使用者隻需要用進階語言編寫雲函數。選擇一個觸發函數運作的觸發器–比如加載圖檔到雲存儲或增加縮略圖到資料庫–讓serverless平台處理其他的所有事:執行個體選擇,伸縮,部署,容錯,監控,日志,安全更新檔等等。表2總結了無伺服器和傳統計算方法的不同。在論文中我們稱傳統的為serverful雲計算。注意到上述兩種方法代表了基于函數的/以伺服器為中心的計算平台的終點,他們都使用容器編排架構,如Kubernetes作為中間層
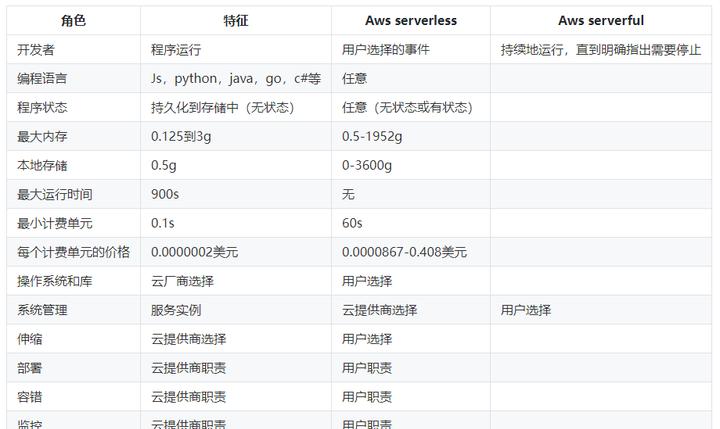
表2:以開發者和系統管理者2個大類分别列舉,serverless和虛拟機的特征。lambda和按需ec2的規格和價格

圖1,展示serverless如何簡化應用部署,使得雲資源更容易被使用。在雲的上下文中,serverful計算就像是程式設計語言中的彙編語言,serverless計算像是python這樣的進階别語言。彙程式設計式員計算簡單的公式,比如c=a+b,得選擇1個或多個寄存器使用,加載值到寄存器中,然後計算公式,然後再存儲結果。這就好比使用serverful計算的幾個步驟,先配置資源,确定可使用的資源,然後在資源中加載代碼和資料,然後開始計算,把結果傳回或者存儲起來,最終将資源釋放。Serveless計算的目标和機會是讓雲程式設計者像使用進階語言那樣受益。其他的一些進階語言特性也可以天然的對應到serverless計算中。自動化的記憶體管了解放了開發者,不需要在管理記憶體資源,serverless computing解放了開發者,不必再管理伺服器資源。
準确地說,serverful和serverless計算有3個關鍵的差別:
- 計算存儲解耦。存儲和計算分别伸縮,獨立配置和計算。存儲由獨立的雲服務提供,計算則是無狀态的。
- 執行代碼而無需管理資源配置設定。不用請求資源,使用者提供代碼片段,雲負責自動配置資源并執行代碼。
- 按使用的資源支付而不是按配置設定的資源支付。按照執行來計費,比如執行時間,而不是基礎雲平台,比如被配置設定的vm的規格。
通過這些差別,接下來我們解釋為何serveless不同于一些相似的解決方案,包括以前的和現在的。
圖1:serverless的架構,serverless層在應用層和基礎雲平台之間,簡化雲程式設計。雲函數(比如FaaS)提供通用計算并且由專門的BaaS補足生态系統,比如對象存儲,資料庫,消息。具體地,一個在AWS上的serverless應用可能會使用lambda,同時使用S3(對象存儲)和dynamoDB(kv資料庫)。一個在google上運作的serverless應用則使用cloud function,同時使用cloud firestore(移動應用背景資料庫),cloud Pub/Sub(消息)。Serverless還有大資料的服務,比如AWS Athena和google BigQuery(big data query),google cloud DataFlow和AWS Glue(big data transform)。下邊的基礎雲平台包括VM,VPC,塊存儲,IAM,還有計費,監控
2.1 Serverless的語境場景
要使severless計算成為可能需要怎樣的技術突破?有些人認為無伺服器計算僅僅是對先前産品的重新命名,可能就是個泛用PaaS平台比如heroku,Firebase或者Parse。有些人指出90年代提供的共享web托管環境提供的和現在serverless計算提供的差不多。比如這些方案都有無狀态的程式設計模型,用于多租,彈性響應請求,标準的函數調用API,通用的網關接口(CGI)等高層級,甚至允許進階别語言編寫的源代碼直接進行部署,比如PHP,Perl。Google原先的App Engine幾年前在serverless流行之前就被市場拒絕了,它也允許開發者部署代碼,将大部分其他操作丢給雲提供商。我們相信serverless計算相對PaaS和其他模型有着顯著的創新。
如今的雲函數severless在以下幾個重要方面差別于他的前身們:更好的伸縮,強隔離性,平台靈活性,服務生态系統支援。在這些因素中,AWS Lambda提供的自動伸縮與以前的方案完全背道而馳。不同于serverful的自動伸縮技術,它更準确的跟蹤工作負載。當需要時能快速的響應伸縮,沒有需求時甚至可以縮到0資源,0開銷。它以更細粒度的方式産生成本。提供最小的計費,每增加100ms收一次費,而其他的自動甚多服務都是按照小時收費。最關鍵的不同,使用者隻需要為執行代碼的時間支付開銷。而不是所有它為程式預留的資源。這種差別確定了雲提供商在自動縮放時獲得利益同時承擔風險[t3] ,也是以他們提供激勵措施[t4] ,以確定高效的資源配置設定。
Severless計算依賴強大的性能和安全隔離使多租戶,硬體共享成為可能。類VM的隔離是目前标準雲函數的多租硬體共享方案,但由于VM的配置時間需要會長達數秒,serverless提供商使用複雜的技術來加速建立函數執行環境。一種方法反映在AWS Lambda, 它維護一個VM執行個體warm pool,需要時配置設定給租戶,一個active pool用來運作函數并服務後續的調用。資源生命周期管理和多租裝箱打包需要達到一個高使用率,這是severless計算成功的關鍵技術。我們認識到幾個最近的proposal目标都是減少多租隔離引起的開銷,他們通過容器,unikernal,library OSes或者language VMs。比如google宣布app engine,cloud functions,cloud ML engine采用gvisor。Amazon釋出Firecracker VMs用于lambda和 fargate。CloudFlare workers serverless平台,在使用浏覽器沙盒技術的javascript雲函數之間提供多租隔離
幾個其他的差別幫助serverless成功。通過允許使用者帶入自己的庫,serverless計算相對PaaS服務能夠幫助更廣泛的應用,後者隻能支援特定的使用場景。Serverless計算跑在現代化資料中心中,比起老的web托管環境有着更大的規模。
如第1節所述,cloud function(即FaaS)使serverless模式變得流行。必須認識到他們的成功部分歸功于BaaS的産品,自公有雲開始以來就一直存在服務,比如AWS S3。在我們看來,這些服務都是領域相關,高優化度的serverless計算的實作。雲函數表示serverless計算的通用形式。通過對比幾個服務的程式設計接口和成本模型,我們把這些看法總結在了表3
表3: serverless計算服務與他們相應的程式設計接口和消費模型。注意上述的bigquery,athena,cloud functions,使用者需要分别地為他們消耗的存儲再付錢(比如google cloud storage,AWS S3或者Azure Blob Storage)。
一種用于部署微服務的容器編排技術。不像serverless計算,k8s是一種簡化Serverful計算的技術。得益于google内部多年的使用和開發,它獲得了大量系統快速的采用,k8s提供短生存周期的計算環境,就像serverless計算那樣,且有着更少的限制,比如,在硬體資源,執行時間,網絡通信方面。它還可以以極小的适配,部署原本部署在公有雲的應用。而serverless計算引入了規範轉變,它完全卸下了操作類的職責,并轉嫁給了提供商,細粒度[t5] 的多租複用成為可能。K8s托管服務,比如GKE,EKS提供中間層:他們卸下了管理k8s的工作,并使開發者可以靈活的配置任意的容器。K8s和serverless計算的關鍵不同是計費模型。前者按保留資源收費,後者按功能執行持續時間收費。
K8s還完美比對了混合應用,部分跑在本地硬體,部分跑在雲上。我們的看法是這種混合應用在向雲過渡中是有道理的。然而長期來看,我們相信雲規模上升後的經濟成本、更快的網絡帶寬、增長的雲服務和通過serverless計算簡化雲管理将降低這種混合應用的重要性。
邊緣計算在後PC時代是雲計算的好夥伴,我們本篇專注在serverless計算如何在資料中心中轉變程式設計習慣,有趣的潛在趨勢是這也會影響到邊緣。幾個CDN提供商使使用者能在最接近他們的設施裡執行他們的函數,不論使用者在哪,AWS IoT greengrass甚至在邊緣裝置內建了serverless執行
既然我們已經定義并決定了serverless計算的語境場景,讓我們看看為什麼它對雲提供商,使用者,研究者那麼有吸引力
2.2 Serverless計算的吸引力
對于提供商來說,serverless通過開發簡化吸引新的客戶,幫助現有客戶更多的使用雲資源(譯者: BaaS)提升了商業增長。例如最近的調查發現,24%的serverless使用者都是雲計算新使用者,30%現有的Serverful客戶也使用Serverless計算。另外短運作時間、小記憶體占用和無狀态天然改進了複用,通過更容易的使提供商找到不在使用中的資源并執行這些任務。提供商也可以利用不太受歡迎的計算節點—執行個體類型完全由提供商決定—比如舊的伺服器也許已經對serverful使用者沒什麼吸引力了。這些都增加了現有資源的收入。
表4:serverless計算的使用場景受歡迎程度,2018年調查
客戶的收益是程式設計生産力提升,同時在許多應用場景都可以節省成本,這是底層伺服器使用率更高的結果。即便serverless使客戶更高效了,然而傑文斯悖論[t6] 說的是高效的使用隻會增加使用者和需求量,最終擴大使用量而不是縮減。
Serverless 提升了雲部署層級從x86機器代碼到進階程式設計語言—99%的雲計算機使用x86指令集,使得架構改革。如果ARM和RISC-V提供更好的成本效益,Serverless計算可以很容易的切換指令集。雲提供商還能去研究面向語言的優化和領域相關的特定架構[t7] 來加速某種語言編寫的程式的執行速度,比如python。
使用者喜歡Severless,因為能夠在不了解雲基礎設施的情況下進行函數部署,專家節省了部署的時間,集中精力在應用獨有的問題上。既然函數隻在執行時計費,且是細粒度的計費,那麼Serverless使用者可以節省金錢,這意味着他們隻付他們使用的東西,而不是他們保留的東西,表格4展示了目前歡迎度高的serverless使用場景。
研究者都被吸引到了serverless計算,尤其是在雲函數方面,因為它是一種新的通用計算抽象,很可能成為雲計算的未來,因為還有很多加速性能,克服限制的可能性。
3.如今Serverless計算平台的限制
雲函數已經成功應用到多種工作負載,包括API服務,事件流處理,特定ETL(表3)。
為了看看是什麼阻礙了他應用于一般的工作負載,我們嘗試建立我們感興趣的應用的serverless版本,并研究其他人釋出的樣例。它們并不代表目前無伺服器計算生态系統之外的其他資訊技術;它們隻是一些簡單的例子,用來揭示可能會阻礙許多其他應用的serverless版本發展的共通弱點。
在本章中,我們展示5個研究項目的概覽,并讨論阻礙serverless平台實作最先進的性能的障礙,比如,比對serverful部署下的工作負載的性能。我們特别關注使用通用雲函數的方法,而不是依賴于其他特定serverless應用(BaaS)。然而在我們最後的例子中,SQLLite,我們識别一個use case映射到FaaS後非常糟糕,我們得出結論,資料庫和嚴重依賴狀态的應用還是适合作為BaaS提供,一個附件在論文最後,有着每個應用更詳細的資訊。
有趣的是,即使是折衷[t8] 的應用程式組合也暴露了類似的弱點,我們在描述應用程式之後列出了這些弱點。表5總結了五個應用程式。
ExCamera:視訊實時編碼。提供實時的編碼服務,比如youtube,取決于視訊大小,如今的編碼方案可以花費幾十分鐘甚至數小時。為了能夠實時編碼,ExCamera将慢速的編碼部分并行化,串行執行快速的部分。ExCamera暴露内部的編解碼狀态,允許編解碼任務以純粹的函數語義執行。特别地,每個任務需要以有着視訊幀的内部狀态做為輸入,并将修改後的内部狀态作為輸出。
MapReduce:分析架構如MapReduce,Hadoop,Spark,部署在傳統的管理叢集中。而有些分析的工作負載已經開始遷移到serverless,這些工作負載大多由Map作業組成,下一步自然是支援全面的MapReduce作業。這個努力背後的驅動力是利用serverless計算的靈活性高效的支援作業,這些作業在執行期間所需的消耗各有不同。
Numpywren:線性代數。大規模線性代數計算是一種傳統的部署在超算或者由高速低延遲時間的網絡連接配接的高性能計算叢集。在這樣的曆史背景下,serverless看上去不适合這個場景[t9] ,但是有兩個理由說明為什麼serverless可能線上性代數計算中是有道理的。第一,管理叢集是一些沒有CS背景的科學家的巨大障礙。第二,并行的量會在計算期間顯著地變化。配置一個節點數量恒定的叢集要不就是會拖慢作業速度,要不就是沒法充分利用叢集性能。
Cirrus:機器學習訓練。機器學習的研究者使用VM叢集來執行不同的ML工作流任務,比如預處理,模型訓練,超參優化。這種方法的一個挑戰是,流水線的不同階段需要不同的資源,如同線性代數一樣,一個固定大小的叢集,會導緻嚴重的利用不足或嚴重降速。Serverless計算可以通過為不同階段配置設定合理資源來克服這個挑戰,還可以解放開發者不再維護叢集。
Serverless SQLLite:資料庫。自動伸縮的資料庫服務已經存在了,但是要更好的了解Serverless的局限性,那麼了解是什麼使得資料庫工作負載這麼的有挑戰是十分重要的。在這個上下文中,我們考慮是否有第三方可以直接使用雲函數來實作一個Serverless Database,一個解決方案是在雲函數中運作通用事務型資料庫,例如PostgresSQL,Oracle,mysql。然而這就會面臨幾個挑戰,第一,Serverless計算沒有内置的持久化存儲,是以我們需要利用遠端的,這會造成巨大的延遲。第二,資料庫采用面向連接配接的協定,比如,資料庫作為server運作接收用戶端的連接配接。這種方案與運作在網絡位址轉換後面的雲函數沖突,是以不能支援這些連結。最後,許多高性能資料庫依賴于共享記憶體,雲函數是隔離的,無法共享記憶體。一些不分享記憶體的資料庫希望節點一直線上,可以直接定位到。全部這些問題對在無伺服器上運作傳統資料庫軟體或實作等效功能提出了重大挑戰,是以我們希望資料庫就放在BaaS。
這些應用希望使用Serverless的一個關鍵理由是細粒度的自動伸縮,這樣資源使用率就可以比對每個應用不同的需求,表格5總結了這5個應用的特征,挑戰和workaround。我們利用他們來識别目前serverless計算的4個局限性
表5:Serverless新應用領域的需求總結
3.1 細粒度操作場景下存儲的不足
Serverless平台天然的無狀态使它很難支援應用進行細粒度狀态分享。這主要是由于現在的雲提供商提供的存儲服務的限制引起的。表6總結了雲存儲服務的特點。
表6:理想的serverless存儲和雲提供商存儲服務特性。綠色表示好,橙色中等,紅色為糟糕。
持久性和可用性保證描述了系統對故障的容忍程度:
Local表示隻能保證一個地區的可靠,distributed確定能夠多個地區可靠,ephemeral表示資料存在記憶體中,應用崩潰,資料就會丢失。理想的Serverless存儲提供與塊存儲相當的成本效益,同時可以透明的讓雲函數配置并通路存儲
對象存儲比如S3,Azure Blob Storage,有着高可擴充性,提供便宜的長期對象存儲。但是卻有着高通路成本和延遲。根據最近的測試,所有這種服務花費至少10微秒讀或寫小對象。S3提供高吞吐,但是他變得更貴了。維持10萬IOPS, 需要花費每分鐘30美元,比運作ElastiCache多3到4個數量級。ElastiCache提供高性能,讀寫延遲小于毫秒,并且一個redis sever一個線程可提供超過10w IOPS的吞吐。
Key value資料庫,例如DynamoDB,Google cloud Datastore提供高IOPS,但是非常貴,而且需要較長時間啟動。最後,雲廠商還提供記憶體存儲執行個體,比如memcached,redis,但是他們不能容錯,也不能像Severless平台那樣自動伸縮。
如我們再表5看到的,建構在Serverless的應用需要透明化配置的存儲服務,與計算的伸縮相比對的存儲量。不同的應用推動不同的持久化和可用性保證,還可能推動延遲或其他性能測量方法。我們相信這需要開發一種短暫的和持久的serverless存儲,我們會進一步在第4部分讨論。
3.2 缺少細粒度協調器
為了擴充支援有狀态應用,serverless架構需要提供一種方法,可以讓任務協作。比如,如果任務A需要任務B的輸出,必須有一種方法讓A知道輸入已經準備好了,甚至A和B在不同的節點中。許多協定[t10] 的目的都是確定資料的一緻性,也需要類似的協調者。
現在的雲存儲服務都沒有通知能力。但是雲廠商提供獨立的通知服務,比如SNS和SQS,這些服務顯著地增加了延遲,有時達到幾百毫秒。此外,當用于細粒度的協調時,它們可能代價高昂。已經有了一些相關的研究,比如Pocket,它沒有很多的缺點,但是還沒有雲廠商去采用它。
如前所述,應用沒有選擇,隻能選擇基于VM管理的系統,這些系統内提供通知,如ElastiCache和SAND,或者實作自己的通知機制比如ExCamera,它讓雲函數之間通過一個長期運作的基于虛拟機的伺服器互相通信。這種局限性還表明一種新的Serverless計算變種可能值得探索,比如給函數執行個體命名并允許直接尋址以通路其内部狀态(Actor as a service)
3.3 糟糕的性能和标準通信模式
廣播,聚合,和shuffle在分布式系統中是一些最通用的通信原語。這些操作被應用到機器學習和大資料分析。圖2展示了這幾種原語在基于VM的和函數解決方案的通信模式。
圖2,:3種分布式系統通用通信模式:a表示VM執行個體,每個執行個體運作2個函數或是任務。B表示同樣的模式但換成了雲函數執行個體。注意VM方案有更少的遠端通信。這是因為
VM執行個體在發送前或收到後提供了大量的機會點,可以跨任務在本地共享、聚合或組合資料
使用VM方案,所有運作在一個執行個體中的任務可以在發送結果到其他執行個體前,共享data的複制用于廣播,本地聚合。是以廣播和聚合的複雜度是O(N),N是VM執行個體數。然而雲函數的複雜度是O(NK),K是每個VM中的函數執行個體。而shuffle操作更具戲劇性。VM方案,本地任務可以組合資料是以2個VM執行個體間隻有一條消息。假設同樣數量的發送者和接受者就是N的平方條消息。對比看,雲函數需要NK的平方條消息。函數比VM有更小的核心數,K一般從10到100。既然應用沒法控制函數的位置,一個serverless應用可能比VM方案多發送2到4個數量級的資料
3.4 可預測的性能
即便雲函數比起傳統VM執行個體有着更低的啟動延遲,但是對于某些應用程式,在啟動新執行個體時發生的延遲可能很高。有三個影響冷啟動延遲的因素:
- 啟動雲函數的時間
- 初始化軟體環境的實踐,比如,python庫
- 使用者自己的代碼
後兩者可以使前者相形見绌。花費1秒的可以可以啟動函數,但是可能需要10多秒來加載應用的庫。[t11]
另一個阻礙預測性能的是硬體資源的可變性,這是雲提供商可以靈活地來選擇底層伺服器的結果。在我們的實驗中,我們有時占用的CPU是不同的時代的産品。這種不确定性暴露了雲提供商在希望最大限度地利用其資源和可預測性之間進行了基本的取舍權衡。
4 Serverless計算會變得怎麼樣
既然我們已經解釋了如今的serverless計算和他的局限性,讓我們看看未來,了解如何将他的優勢利用到更多的應用。研究者已經開始着手解決上述的問題,并且探索如何改進serverless平台和跑在其上的工作負載。伯克利同僚和我們的一些人所做的額外工作重視以資料為中心,分布式系統,機器學習,程式設計模型在serverless計算的機遇和挑戰。在這裡,我們廣泛的看看增加在serverless計算中運作良好的應用程式和硬體的類型,識别5個領域的研究挑戰:抽象,系統,網絡,安全和架構
4.1 抽象
資源需求: 現在serverless允許開發者指定函數的記憶體大小和執行時間限制,但沒有其他的資源需求。這種抽象阻礙了那些想要更多地控制指定資源的人,比如CPU,GPU。一種可以讓開發者明确指定這些資源需求的方法。然而這将使雲提供商更難通過複用實作高使用率,因為他為函數排程增加了更多的限制。它還違背了無伺服器的精神,增加了雲應用程式開發者的管理開銷
更好的選擇是提高抽象級别,讓雲提供商推斷資源需求,而不是讓開發人員指定它們。為此,雲提供商可以使用多種方法,從靜态代碼分析到分析以前的運作,再到動态(重新)編譯,将代碼重新定位到其他機器架構。自動提供适當的記憶體量特别有吸引力,但是當方案必須與自動垃圾回收合作時是非常有挑戰的。有些研究提議這些語言運作時能被serverless平台內建。
資料依賴: 如今的雲函數平台不會感覺函數間的資料依賴,更不用說這些函數可能交換的資料量了。這種忽視會導緻次優的系統布局,進而導緻低效的通信模式,如我們前述的MapReduce和numpywren
一種解決這個挑戰的方法是,雲提供商暴露API讓應用指定他的計算圖,通過更好的位置決策,最小化通信并改進性能。我們注意到許多通用的分布式架構(例如MapReduce,Spark, Beam, Cloud Datafow),并行資料庫(BigQuery,Cosmos DB),還有編排架構(Airflow)可以在内部産生一個圖。原則上這些系統内可以在修改後跑在蘊含出上并暴露圖給雲提供商[t12] 。注意AWS Step Functions代表着這個發展方向的進步,它提供有狀态機器語言和API
4.2系統挑戰
高性能,價格合理,透明配置的存儲: 如表3和5所讨論的,我們2個不同的未解決的存儲需求:serverless臨時存儲和持久存儲
臨時存儲。在第三部分的前4個應用被存儲的速度和延遲限制了,存儲用于在雲函數間傳送狀态。同時需要的容量也是不同的,他們都需要這樣的一種存儲來維護應用存活期間的狀态。一旦應用結束,狀态就可以被丢棄。這樣的短暫存儲也許可以使用其他應用的緩存來進行配置。[t13]
一種提供短暫存儲的方法是建構一個網絡棧優化的分布式記憶體服務,確定微秒級延遲。這種系統確定應用的函數在應用生存期間能夠高效的存儲交換狀态。這種記憶體服務需要根據應用需求自動伸縮存儲容量和IOPS。這種服務的一個獨特點在于,它不隻需要透明配置設定記憶體,還要透明的釋放記憶體。特别地,當應用終止或者失敗,存儲需要被自動釋放。這種管理類似于作業系統自動釋放程序完成(或崩潰)時由程序配置設定的資源。進一步,這樣的存儲必須提供應用間的通路保護和性能隔離。
RAMCloud和FaRM展示了提供微秒級的實驗并支援一個執行個體幾百幾千IOPS的記憶體存儲服務也是可能的。他們通過優化整個軟體棧并利用RDMA來最小化延遲來達到這個效果。然而他們需要應用指明配置存儲。他們也不為多租提供強隔離。另外一個最近的,Pocket,目标是提供短暫存儲的抽象,但是也缺少自動伸縮,要求應用預先配置設定存儲。
通過利用多路複用,臨時存儲比如今Serverless計算更高效的利用記憶體。使用Serverless,如果應用需要的記憶體少于配置設定的VM執行個體記憶體,那麼記憶體就會浪費,相反,使用共享記憶體服務,一個無伺服器應用未使用的任何記憶體都可以配置設定給另一個應用。實際上,即便一個應用也可以通過多路複用獲得收益:使用Serverless,VM不使用的記憶體不會被跑在其他VM上的程式使用,他們都屬于同一個應用。而共享記憶體服務可以。當然,即使使用Serverless計算如果雲函數不使用它全部的本地記憶體,也會造成内部的記憶體碎片。在某些情況下,在共享記憶體服務中存儲雲函數的應用狀态可以減輕記憶體碎片化。
持久存儲。就像個其他應用一樣,serverless資料庫應用的試驗受限于存儲系統内的延遲和IOPS,他也需要長期的資料存儲和檔案系統可變狀态語義。而資料庫的功能包括OLTP可能會越來越多的作為BaaS提供[t14] 。我們将此應用視為幾個應用程式的代表,這些應用需要比serverless提供給的臨時存儲更長的保留期和更高的持久性。為了實作高性能serverless持久化存儲。一種方法是利用基于SSD的分布式存儲對,配合分布式記憶體緩存。一個最近的系統認識到需要這些目标,那就是Anna Key value資料庫,他通過結合多個現有的雲存儲達成了成本效益和高性能。這個設計的一個關鍵挑戰是在重尾通路分布[t15] 中達成low tail latency[t16] ,基于這個事實,記憶體緩存容量可能會被SSD容量低很多很多[t17] 。利用新的存儲技術[t18] ,承諾微秒級通路時間,正在成為解決這一挑戰的一個有前途的辦法。
類似Serverless臨時存儲,服務必須是透明配置的,并且應該確定應用間隔離和租戶安全并且性能可預測。然而,當應用程式終止時,serverless的臨時存儲将回收資源,持久存儲必須隻是釋放資源(比如remove或者delete指令造成的終止),就像傳統存儲系統一樣。另外,它必須確定持久性,這樣寫入的資料才能被儲存下來。
協調器/ 信号服務: 在函數間分享狀态經常使用生産者消費者模式,這需要消費者在資料可用時就知道這件事。同樣地,當某個條件變化時,一個函數可能想要發信号給另一個函數或者多個函數共同協調,比如為了實作資料一緻性機制。這樣的信号系統可以從微秒延遲,可靠消息和廣播,組通信中受益。我們也注意到,既然雲函數執行個體不是獨立可尋址的,那麼他們就不能被用于實作标準的分布式系統算法,如共識或leader選舉
最小化啟動時間: 啟動時間由3部分組成
1. 排程和啟動資源使用者用于運作函數
2. 下載下傳應用環境(OS,庫)用于運作函數代碼
3. 應用啟動,比如加載,初始化資料結構,庫。
資源排程和初始化會引起明顯的延遲和負擔,因為他會建立隔離的執行環境,配置客戶的VPC和IAM政策。雲提供商最近已經專注于開發新的輕量化隔離機制來減少啟動時間。
一種減少2的方法是利用unikernal。Unikerna用兩種方法消除傳統作業系統帶來的開銷。第一,不像傳統OS動态探測硬體,應用使用者配置,配置設定資料結構,unikernal通過為運作它們的硬體預先配置并靜态配置設定資料結構,來壓縮這些成本。第二,unikernal隻包括應用需要的驅動和系統庫,這比傳統系統的占用低許多。值得注意的是,由于unikernels是為特定的應用程式定制的,當運作标準核心的許多執行個體時,可能無法實作高效。比如不同雲函數在同VM共享核心頁,或者通過預緩存減少啟動時間。另一種減少2的方法是當應用調用時動态并增量的加載庫,比如Azure Functions使用共享檔案系統。
特定應用初始化(3)是程式員的職責,但是雲提供商可以包含一個準備就緒信号在他們的API裡來避免雲函數在執行個體沒啟動前就收到工作。更寬泛的說,雲提供商可以尋求提前執行啟動任務的方法[t19] 。對于與客戶無關的任務,比如用流行的作業系統和一系列庫引導VM,這一功能尤其強大。如warm pool[t20] 可以在租戶間共享。
4.3 網絡挑戰
如第三章圖2所說,雲函數可以引起及明顯的通信負擔,這些通信原語都是非常流行的如廣播,聚合,shuffle。尤其是假設我們打包K個函數在同一個VM執行個體,雲函數版相對單執行個體版會發K倍的消息,在shuffle則是K平方。
有幾種方法可以解決這個挑戰:
- 提供給函數大量的cores,類似VM執行個體,這樣在網絡上發送消息前和接受後,多個任務可以在他們之間組合和共享資料。
- 允許開發者明确的把函數部署到同一個VM,提供分布式通信原語,應用可以開箱即用,這樣雲提供商可以配置設定函數到同一個VM執行個體。
- 讓應用提供計算圖,雲提供商對函數進行定位最小化通信負擔(參考抽象挑戰)
注意前兩個proposal可能減少雲提供商放置函數的靈活性,導緻減少資料中心使用率。争議地是,他們也通過逼迫開發者思考系統管理,違背了Serverless精神
4.4.安全挑戰
Serverless計算洗牌了安全職責,将他們從使用者轉嫁給了提供商,沒有從根本上改變他們。然而serverless計算還必須處理應用和多租戶資源共享中内在的風險。
随機排程和實體隔離: 實體共存是在雲内部硬體級别側信道或Rowhammer[t21] 攻擊的中心。攻擊的第一步,攻方租戶需要确認與受害人在同一實體主機上,而不是随機攻擊陌生人。雲函數的短暫性可能會限制攻擊者識别受害者(兩方的函數同時運作)的能力。一種随機化的敵方感覺排程算法可以減少攻擊方和受害者定位在一起的風險,使攻擊變得困難。然而,特意阻止實體上的共同放置,可能會與優化啟動時間、資源利用或通信的安排相沖突
細粒度安全上下文:雲函數需要細粒度配置,包括秘鑰通路,存儲對象,甚至本地臨時資源。需要翻譯已經存在的Serverful應用的安全政策,提供高表達能力的安全API給雲函數動态使用。比如函數可能委托安全權限給其他函數或雲服務。使用加密保護基于功能的通路控制機制的安全上下文天然适合這種分布式安全模型。最近的工作提議,使用資訊流在多方配置中控制跨函數通路控制。其他的提供安全原語的分布式管理,例如non-equivocation和revocation會使情況惡化,如果函數動态建立秘鑰和證書。
在系統級别,使用者需要每個函數有更細粒度的安全隔離,至少是可選的。提供函數級沙箱的挑戰是以一種方法在不緩存執行環境的情況下保持短啟動時間,在重複的函數調用之間共享狀态的,一種可能是對執行個體進行本地快照,以便每個函數都可以從幹淨狀态開始。或者輕量級虛拟化技術開始被serverless提供商采用:library OSes 包括gVisor,在使用者空間“shim layer”實作系統API,而unikernal和microVMs,包括AWS firecracker,優化guest核心并幫助最小化主機攻擊面。這些隔離技術減少了啟動時間到了幾十微秒,相對的,VM啟動時間是以秒度量。這些解決方案是否在安全性方面與傳統vm實作了對等,還有待證明。我們期望,尋找具有低啟動開銷的強隔離機制成為研究和開發的一個活躍領域。從積極的一面來看,提供商管理和短期執行個體可以更快地修補漏洞。
使用者系統避免共住攻擊,一種解決方案是要求實體隔離。最近的硬體攻擊也利用保留核心甚至整個機器來吸引使用者。提供商可以提供進階選項給客戶在實體主控端啟動函數,主控端完全歸屬于他們使用[t22] 。
不留意的Serverless計算:函數可能通過通信洩漏通路模式和時間資訊。對于serverful應用程式,資料通常是在批進行中檢索的,并在本地緩存。相反,因為雲函數是短暫的,分布廣泛在雲中,網絡傳輸模式可以向雲中的網絡攻擊者洩漏更敏感的資訊(比如員工就是攻擊者),即使payload是端到端加密的。将無伺服器應用程式分解為許多小函數的趨勢加劇了這種安全暴露。雖然主要的安全問題是來自外部攻擊者,但是可以通過采用不經意的算法[t23] 來保護網絡模式不受雇員的攻擊。不幸的是,這些往往有很高的開銷
4.5 計算架構挑戰
異構硬體,價格,易于管理:x86微處理器作為在雲計算中占主導地位的技術在性能上幾乎沒有提高。2017年一個程式的性能提升隻有3%。如果這種趨勢繼續下去,20年内性能不會翻番。同樣,每個晶片的DRAM容量也接近極限;現在在賣16gbit的DRAM,但是要制造一個32gbit的DRAM晶片似乎是不可行的。這種緩慢變化的一個好兆頭是,供應商可以将磨損的舊電腦不受幹擾[t24] 的投入到Serverless市場。
通用微處理器的性能問題并不能降低對更快計算的需求。有兩條路,對于用進階腳本語言(如JavaScript或Python)編寫的函數,軟硬體協同設計可以使特定于語言的運作速度快一到三個數量級的定制處理器,另一個前進的路徑是特定領域的體系結構[t25] 。DSA針對特定的問題領域進行了定制,并提供顯著的性能和效率提高,但該域以外的應用程式的性能較差。GPU一直被用來加速圖形,我們開始将DSAs用于機器學習,如TPU。TPU的性能可以超過CPU 30倍。這些示例是許多示例中的第一個,針對不同領域使用DSA增強的通用處理器将成為常态
如4.1提到的,我們看到serverless計算支援異構硬體2條路:
- Serverless擁抱多種執行個體類型,根據使用的硬體提供不同的計費方式。
- 提供商能夠基于語言自動選擇加速器和DSA。這種自動化可以隐式地基于在函數中使用的軟體庫或語言來實作,比如GPU硬體用于CUDA 代碼,TPU用于TensorFlow代碼。可選地,提供商監控函數的性能,下次運作時将他們遷移到個更适合的硬體。
Severless計算現在需要面對x86中的SIMD指令集的異構。AMD和Intel通過增加每個時鐘周期執行的操作數和添加新的指令,迅速發展了x86指令集的這一部分。對于使用SIMD指令的程式,在最新的Intel Skylake微處理器上運作512位寬的SIMD指令比在舊的Intel Broadwell微處理器上運作128位寬的SIMD指令要快得多。如今AWS Lambda以同樣的價格提供所有的微處理器,但是使用者目前沒辦法指定他們想要更快的SIMD。在我們看來,編譯器[t26] 應該建議使用哪種硬體會是最好的搭配。
當加速器變得更流行時,serverless提供商将不能夠忽視異構的兩難境地,尤其是因為存在合理的補償措施。
5.謬論和陷阱
**謬論 : **既然Lambda 雲函數執行個體有着和t3.nano 相等的記憶體容量,而價格是7.5 倍每分鐘,那麼severless 的價格更貴。
Severless計算的美妙之處在于價格中包含的所有系統管理功能,包括可用性備援、監視、日志記錄和伸縮。雲提供商報告說,當将應用遷移到Serverless時,客戶看到成本節約了4-10倍。功能要比一個t3.nano執行個體多很多,除了單點故障外,信用系統還将其限制為每小時最多6分鐘的CPU使用時間(兩個vCPUs中的5%),是以它可能在負載高峰期間拒絕服務,而Serverless卻可以輕松處理。Serverless在更細的邊界進行資源占用,包括伸縮,是以使用的計算資源可能更高效。因為沒有觸發函數調用的事件時就不會收費,serverless可能便宜許多。
陷阱 計算可能會産生不可預測的成本。
對有些使用者來說,一個用多少花多少的缺點是無法預測成本,這與許多組織管理預算的方式不一緻。在準許預算(通常每年進行一次)時,組織希望知道下一年serverless服務的成本是多少,這種期望是合理的,雲提供商可以通過提供基于bucket的定價來緩解,類似于電話公司為一定量的使用提供固定費率計劃的方式。我們還相信,随着組織越來越多地使用serverless,他們将能夠根據曆史預測其serverless計算成本,類似于他們今天對電力等其他公用事業服務的方式。
謬論 既然serverless 計算程式設計是進階别語言就像python ,那就很容易在不同serverless 提供商間移植。
不隻是函數的調用原語和打包方式不同,而且serverless應用還依賴于缺乏标準化的專有的BaaS産品生态系統。對象存儲,key value資料庫,認證,日志和監控這些是突出的例子。為了實作可移植性,使用者必須采用某種标準API,比如POSIX試圖為作業系統提供的API。來自Google的Knative項目是朝這個方向邁出的一步,旨在為應用開發人員跨部署環境使用統一的原語
陷阱 比起Serverful 計算,serverless 廠商鎖定可能非常強
這個陷阱是先前謬論的結果;如果移植很困難,那麼很可能會出現供應商鎖定。一些架構承諾通過跨雲支援來減輕這種鎖定
謬論 雲函數不能處理需要能預測性能的低延遲應用
serverful執行個體之是以能很好地處理這種低延遲的應用程式,是因為它們總是處于打開狀态,是以它們可以在收到請求時快速響應請求。我們注意到,如果雲功能的啟動延遲對于給定的應用程式來說不夠好,那麼可以使用類似的政策:通過定期運作來預熱雲函數,以確定在給定時間内有充足的運作執行個體來處理請求。
陷阱 幾乎沒有所謂“彈性”的服務能比得上無伺服器計算的真正的靈活性需求
如今彈性這個詞是個流行術語,但這個名字被應用在那些不如serverless計算服務的服務上。
我們對能迅速改變容量的服務感興趣,隻需最少的使用者幹預,就可以在不使用時“伸縮到零”。例如,盡管它的名字是AWS ElastiCache,但它隻允許你執行個體化固定的數量的Redis執行個體。其他“彈性”服務需要顯式的容量配置,有些服務需要花費數分鐘來響應需求的變化,或者隻能在一個限制的範圍伸縮。當使用者建構的應用将高度彈性的雲函數與隻有有限彈性的資料庫、搜尋索引或伺服器級應用程式結合起來時,他們将失去serverless計算的許多好處。
如果沒有一個量化的、被廣泛接受的技術定義或度量标準,用于幫助對比和構成系統,那麼彈性就還是一種不明确的描述。
6總結和預測
通過提供一種簡化的程式設計環境,serveless使雲更容易使用,是以吸引更多人可以和願意使用它。Serverless計算承諾FaaS和BaaS傳遞,是雲程式設計的重要成熟标志。它消除了當今serverful計算對應用開發人員的手動資源管理和優化的需要。類似于過去40年彙編語言向進階語言的演變。
我們預測serverless的使用将激增,我們還預計,随着時間的推移,混合雲中的本地應用程式将逐漸減少。盡管由于監管限制和資料治理規則,一些部署可能會持續保持現狀。[t27]
雖然已經取得了成功,但我們發現了一些挑戰,如果克服了這些挑戰,伺服器将在更廣泛的應用中變得受歡迎。第一步是Serverless臨時存儲,他必須提供低延遲,高IOPS,且價格合理,但是不需要提供實惠的長期儲存。第二類應用需要持久存儲,可按需長期存儲。新的非易失性記憶體技術可能有助于這樣的一種存儲系統。其他應用程式可以從低延遲信号服務和對流行通信原語的支援中獲益。
無伺服器計算未來面臨的兩個改進挑戰是安全性和成本效益優勢(成本效益可能來自于特殊用途的處理器)。在這兩種情況下,serverless計算的特性有可能有助于解決這些挑戰。實體共住是側信道攻擊的條件,但是在serverless計算中很難确定,而且可以很容易地随機放置雲函數。 雲函數進階語言程式設計如JavaScript, Python, TensorFlow提升了程式設計抽象層級,使創新變得容易,這樣可以傳遞具有成本效益的硬體。
伯克利對serverless計算的看法論文預測2009年雲計算面臨的挑戰将得到解決,并将蓬勃發展,這已經成真了。雲營業額年增長50%,已經被證明對提供商來說是高盈利的。
我們對serverless計算的下一個10年作了以下預測:
- 我們期望新的BaaS存儲服務,以擴充在serverless計算上運作良好的應用類型。這樣的存儲将比對本地塊的性能,有短暫和持久兩種。我們将看到用于serverless計算的異構硬體遠遠超過今天為其提供動力的傳統x86微處理器。
- 我們期望serverless計算比serverful計算更容易安全地程式設計,這得益于高層級程式設計抽象和雲函數的細粒度隔離。
- 我們看不出serverless計算的成本高于serverful計算的基礎,是以我們預測計費模型将會變化,任何規模的應用消耗的成本都會更少。
- serverful計算的未來将是促進BaaS的發展。在severless計算上很難編寫的應用程式,比如OLTP資料庫和通過信原語如隊列,可能會是這種服務的一部分。
- serverful計算不會消失,随着serverless計算克服了他的諸多局限性,他在雲的重要性将下降
- serverless計算将成為雲時代的預設計算模式,在很大程度上取代了serverful計算,進而結束了用戶端-服務端時代
[t1]譯者:隻要運作便是在滿速運轉的,跑在同一個資源池裡進行資源複用就行了
[t2]譯者:獨占資源池,平時閑置比較多,随時待用,資源難以複用
[t3]譯者:高效利用資源,而對于使用者來說,則是把資源管理等多種風險都給了雲提供商
[t4]譯者:新的收費形式
[t5]譯者:相對的,粗粒度指虛機級别的資源配置設定,而serverless卻使共享虛機成為可能
[t6]譯者:這也是為啥早期雲計算剛興起時,oracle等傳統伺服器廠商搶着做雲計算,VM的高效使得伺服器可以大賣
[t7]譯者:領域相關,比如安防領域
[t8]譯者:不是無狀态,但也不是像資料庫那樣的重依賴于狀态的應用
[t9]譯者:指的網絡延遲和高性能不适合
[t10]譯者:比如raft
[t11]譯者:是以java需要一種方案,否則Serverless在國内很難打動市場,比如Graal和Quarkus
[t12]譯者:這樣的話标準誰制定還是雲廠商主動适配?
[t13]譯者:Redis?
[t14]One recent example is Amazon Aurora Serverless (https://aws.amazon.com/rds/aurora/serverless/). Services such as Google’s BigQuery and AWS Athena are basically serverless query engines rather than fully fledged databases.
[t15]每種雲存儲的延遲,速度是完全不同的,呈重尾分布
[t16]比如P99 1ms,但是p99.9高達2s,說的是這部分延遲需要被降低
可能 [t17]如重尾分布所說,呈現2/8分布
[t18]An Chen. A review of emerging non-volatile memory (NVM) technologies and applications. Solid-State Electronics, 125:25–38, 2016.
[t19]Edward Oakes, Leon Yang, Dennis Zhou, Kevin Houck, Tyler Harter, Andrea Arpaci-Dusseau, and Remzi Arpaci-Dusseau. SOCK: Rapid task provisioning with serverless-optimized containers. In 2018 USENIX Annual Technical Conference (USENIX ATC 18), pages 57–70, 2018.
[t20]Timothy A. Wagner. Acquisition and maintenance of compute capacity, September 4 2018. US Patent 10067801B1.
[t21]Yoongu Kim, Ross Daly, Jeremie Kim, Chris Fallin, Ji Hye Lee, Donghyuk Lee, Chris Wilkerson, Konrad Lai, and Onur Mutlu. Flipping bits in memory without accessing them: An experimental study of dram disturbance errors. In ACM SIGARCH Computer Architecture News, volume 42, pages 361–372. IEEE Press, 2014.
[t22]譯者:非常不錯的收費模式和安全政策,雖然違背Serverless精神
[t23] An algorithm whose behavior, by design, is independent of some property that influences a typical algorithm for the same problem…
Elaine Shi, T-H Hubert Chan, Emil Stefanov, and Mingfei Li. Oblivious RAM with O((log N) 3 ) worst-case cost. In International Conference on The Theory and Application of Cryptology and Information Security, pages 197–214. Springer, 2011.
[t24]譯者:使用者感覺不到便是沒有幹擾?
[t26]譯者:Serverless平台中的編譯器
[t27]譯者:這也阻礙一些業務向service mesh的轉型
點選關注,第一時間了解華為雲新鮮技術~