Leaf是美團基礎研發平台推出的一個分布式ID生成服務,名字取自德國哲學家、數學家萊布尼茨的一句話:“There are no two identical leaves in the world.”Leaf具備高可靠、低延遲、全局唯一等特點。目前已經廣泛應用于美團金融、美團外賣、美團酒旅等多個部門。具體的技術細節,可參考此前美團技術部落格的一篇文章:《Leaf美團分布式ID生成服務》。近日,Leaf項目已經在Github上開源:https://github.com/Meituan-Dianping/Leaf,希望能和更多的技術同行一起交流、共建。
Leaf特性
Leaf在設計之初就秉承着幾點要求:
- 全局唯一,絕對不會出現重複的ID,且ID整體趨勢遞增。
- 高可用,服務完全基于分布式架構,即使MySQL當機,也能容忍一段時間的資料庫不可用。
- 高并發低延時,在CentOS 4C8G的虛拟機上,遠端調用QPS可達5W+,TP99在1ms内。
- 接入簡單,直接通過公司RPC服務或者HTTP調用即可接入。
Leaf誕生
Leaf第一個版本采用了預分發的方式生成ID,即可以在DB之上挂N個Server,每個Server啟動時,都會去DB拿固定長度的ID List。這樣就做到了完全基于分布式的架構,同時因為ID是由記憶體分發,是以也可以做到很高效。接下來是資料持久化問題,Leaf每次去DB拿固定長度的ID List,然後把最大的ID持久化下來,也就是并非每個ID都做持久化,僅僅持久化一批ID中最大的那一個。這個方式有點像遊戲裡的定期存檔功能,隻不過存檔的是未來某個時間下發給使用者的ID,這樣極大地減輕了DB持久化的壓力。
整個服務的具體處理過程如下:
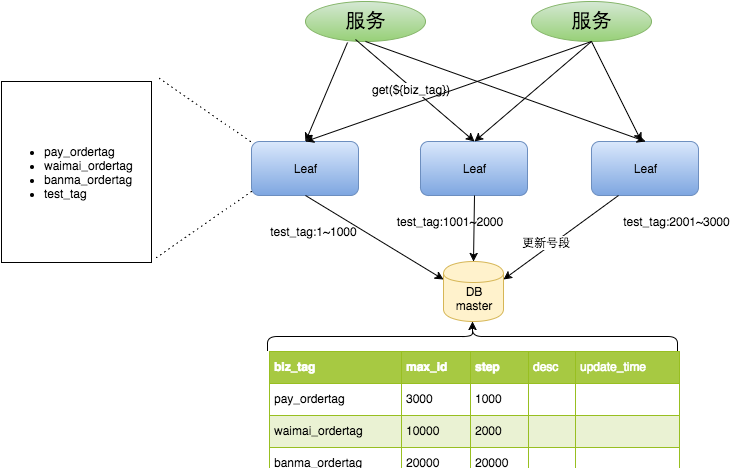
- Leaf Server 1:從DB加載号段[1,1000]。
- Leaf Server 2:從DB加載号段[1001,2000]。
- Leaf Server 3:從DB加載号段[2001,3000]。
使用者通過Round-robin的方式調用Leaf Server的各個服務,是以某一個Client擷取到的ID序列可能是:1,1001,2001,2,1002,2002……也可能是:1,2,1001,2001,2002,2003,3,4……當某個Leaf Server号段用完之後,下一次請求就會從DB中加載新的号段,這樣保證了每次加載的号段是遞增的。
Leaf資料庫中的号段表格式如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+
Leaf Server加載号段的SQL語句如下:
Begin
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx
SELECT tag, max_id, step FROM table WHERE biz_tag=xxx
Commit
整體上,V1版本實作比較簡單,主要是為了盡快解決業務層DB壓力的問題,而快速疊代出的一個版本。因而在生産環境中,也發現了些問題。比如:
- 在更新DB的時候會出現耗時尖刺,系統最大耗時取決于更新DB号段的時間。
- 當更新DB号段的時候,如果DB當機或者發生主從切換,會導緻一段時間的服務不可用。
Leaf雙Buffer優化
為了解決這兩個問題,Leaf采用了異步更新的政策,同時通過雙Buffer的方式,保證無論何時DB出現問題,都能有一個Buffer的号段可以正常對外提供服務,隻要DB在一個Buffer的下發的周期内恢複,就不會影響整個Leaf的可用性。

這個版本代碼線上上穩定運作了半年左右,Leaf又遇到了新的問題:
- 号段長度始終是固定的,假如Leaf本來能在DB不可用的情況下,維持10分鐘正常工作,那麼如果流量增加10倍就隻能維持1分鐘正常工作了。
- 号段長度設定的過長,導緻緩存中的号段遲遲消耗不完,進而導緻更新DB的新号段與前一次下發的号段ID跨度過大。
Leaf動态調整Step
假設服務QPS為Q,号段長度為L,号段更新周期為T,那麼Q * T = L。最開始L長度是固定的,導緻随着Q的增長,T會越來越小。但是Leaf本質的需求是希望T是固定的。那麼如果L可以和Q正相關的話,T就可以趨近一個定值了。是以Leaf每次更新号段的時候,根據上一次更新号段的周期T和号段長度step,來決定下一次的号段長度nextStep:
- T < 15min,nextStep = step * 2
- 15min < T < 30min,nextStep = step
- T > 30min,nextStep = step / 2
至此,滿足了号段消耗穩定趨于某個時間區間的需求。當然,面對瞬時流量幾十、幾百倍的暴增,該種方案仍不能滿足可以容忍資料庫在一段時間不可用、系統仍能穩定運作的需求。因為本質上來講,Leaf雖然在DB層做了些容錯方案,但是号段方式的ID下發,最終還是需要強依賴DB。
MySQL高可用
在MySQL這一層,Leaf目前采取了半同步的方式同步資料,通過公司DB中間件Zebra加MHA做的主從切換。未來追求完全的強一緻,會考慮切換到MySQL Group Replication。
現階段由于公司資料庫強一緻的特性還在演進中,Leaf采用了一個臨時方案來保證機房斷網場景下的資料一緻性:
- 多機房部署資料庫,每個機房一個執行個體,保證都是跨機房同步資料。
- 半同步逾時時間設定到無限大,防止半同步方式退化為異步複制。
Leaf監控
針對服務自身的監控,Leaf提供了Web層的記憶體資料映射界面,可以實時看到所有号段的下發狀态。比如每個号段雙buffer的使用情況,目前ID下發到了哪個位置等資訊都可以在Web界面上檢視。
Leaf Snowflake
Snowflake,Twitter開源的一種分布式ID生成算法。基于64位數實作,下圖為Snowflake算法的ID構成圖。
- 第1位置為0。
- 第2-42位是相對時間戳,通過目前時間戳減去一個固定的曆史時間戳生成。
- 第43-52位是機器号workerID,每個Server的機器ID不同。
- 第53-64位是自增ID。
這樣通過時間+機器号+自增ID的組合來實作了完全分布式的ID下發。
在這裡,Leaf提供了Java版本的實作,同時對Zookeeper生成機器号做了弱依賴處理,即使Zookeeper有問題,也不會影響服務。Leaf在第一次從Zookeeper拿取workerID後,會在本機檔案系統上緩存一個workerID檔案。即使ZooKeeper出現問題,同時恰好機器也在重新開機,也能保證服務的正常運作。這樣做到了對第三方元件的弱依賴,一定程度上提高了SLA。
未來規劃
- 号段加載優化:Leaf目前重新開機後的第一次請求還是會同步加載MySQL,之是以這麼做而非服務初始化加載号段的原因,主要是MySQL中的Leaf Key并非一定都被這個Leaf服務節點所加載,如果每個Leaf節點都在初始化加載所有的Leaf Key會導緻号段的大量浪費。是以,未來會在Leaf服務Shutdown時,備份這個服務節點近一天使用過的Leaf Key清單,這樣重新開機後會預先從MySQL加載Key List中的号段。
- 單調遞增:簡易的方式,是隻要保證同一時間、同一個Leaf Key都從一個Leaf服務節點擷取ID,即可保證遞增。需要注意的問題是Leaf服務節點切換時,舊Leaf 服務用過的号段需要廢棄。路由邏輯,可采用主備的模型或者每個Leaf Key 配置路由表的方式來實作。
關于開源
分布式ID生成的方案有很多種,Leaf開源版本提供了兩種ID的生成方式:
- 号段模式:低位趨勢增長,較少的ID号段浪費,能夠容忍MySQL的短時間不可用。
- Snowflake模式:完全分布式,ID有語義。
讀者可以按需選擇适合自身業務場景的ID下發方式。希望美團的方案能給予大家一些幫助,同時也希望各位能夠一起交流、共建。
Leaf項目Github位址:https://github.com/Meituan-Dianping/Leaf 。
如有任何疑問和問題,歡迎送出至Github issues。
原文位址:https://tech.meituan.com/2019/03/07/open-source-project-leaf.html