參考文章:
Cyc2018-資料庫系統原理
mysql索引的新手入門詳解
多個單列索引和聯合索引的差別詳解
MySQL體系架構
MySQL體系結構
【MySQL】漫談MySQL體系結構
MySQL面試題(六)資料庫的分庫分表原理詳解
MySQL資料庫之網際網路常用分庫分表方案
事務
1、什麼是資料庫事務?事務的屬性?
事務指單個邏輯單元執行的一系列操作,要麼都執行,要麼都不執行。
一個邏輯單元要成為事務,必須滿足ACID的屬性,即原子性、一緻性、隔離性、持久性
原子性:
一件事情會有多個動作,必須都執行或都不執行。事務是最小的執行機關,不可分割
一緻性:
資料庫的資料要在事務前後保持一緻。
隔離性:
對同一個表并發進行多個事務,事務間互相隔離。
持久性:
一旦事情commit,不可更改,持久生效。
AUTOCOMMIT
MySQL 預設采用自動送出模式。也就是說,如果不顯式使用 START TRANSACTION 語句來開始一個事務,那麼每個查詢都會被當做一個事務自動送出。
2、并發事務帶來哪些問題?
髒讀:
一個事務讀取到被另一個事務修改當還未送出的資料,依據“髒資料”所做的操作可能是不正确的。
丢失修改:
一個事務修改了被另一個事務修改當還未送出的資料,先送出的事務的修改就會丢失
不可重複讀:
指在一個事務内多次讀同一資料。在這個事務還沒有結束時,另一個事務修改了該資料。這就發生了在一個事務内兩次讀到的資料是不一樣的情況,是以稱為不可重複讀。
幻讀:
一個事務讀取一個範圍内的資料,另一個事務向這個範圍内插入了一些資料,在随後的查詢中,第一個事務(T1)就會發現多了一些原本不存在的記錄,就好像發生了幻覺一樣,是以稱為幻讀。
不可重複讀和幻讀差別:
不可重複讀的重點是對單條記錄的修改,比如多次讀取一條記錄發現其中某些列的值被修改;幻讀的重點在于對多條記錄的新增或者删除,比如多次讀取一個範圍的記錄發現記錄增多或減少了。
産生并發不一緻性問題主要原因是破壞了事務的隔離性,解決方法是通過并發控制來保證隔離性。并發控制可以通過加鎖來實作,但是加鎖操作需要使用者自己控制,相當複雜。資料庫管理系統提供了事務的隔離級别,讓使用者以一種更輕松的方式處理并發一緻性問題。
3、事務隔離級别有哪些? MySQL的預設隔離級别是?
SQL 标準定義了四個隔離級别:
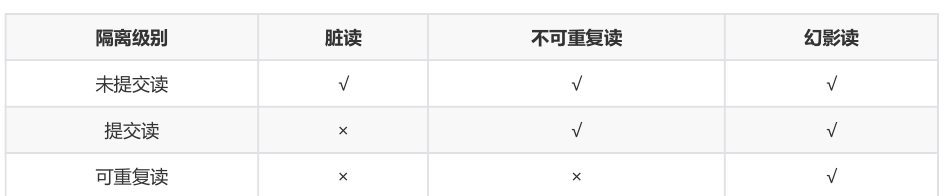
READ-UNCOMMITTED(未送出讀):
最低的隔離級别,允許讀取尚未送出的資料變更,可能會導緻髒讀、幻讀或不可重複讀。
READ-COMMITTED(送出讀):
允許讀取并發事務已經送出的資料,可以阻止髒讀,但是幻讀或不可重複讀仍有可能發生。
REPEATABLE-READ(可重複讀):
對同一字段的多次讀取結果都是一緻的,除非資料是被本身事務自己所修改,可以阻止髒讀和不可重複讀,但幻讀仍有可能發生。
SERIALIZABLE(可串行化):
最高的隔離級别,完全服從ACID的隔離級别。所有的事務依次逐個執行,這樣事務之間就完全不可能産生幹擾,也就是說,該級别可以防止髒讀、不可重複讀以及幻讀。
4、事務隔離級别的RR和RC是怎麼實作的
《MySQL MVCC 和 鎖機制》
相關文法
1、建表的原則(三大範式)
第一範式(1NF)
屬性不可分
第二範式
符合第一範式,且非主屬性完全依賴于碼,消除了部分依賴 --> 非主屬性不能完全依賴于碼的一部分,如(A, B)是碼,非主屬性 C 依賴于 (A, B), 但是如果同時 A -> C, 即 C 又依賴于 A ,那麼就存在部分依賴,這時 C 屬性應該從表中脫離出來,與 A共同 成為一張表
第三範式
符合第二範式,且消除傳遞依賴,也就是每個非主屬性都不傳遞依賴于候選鍵,即如果存在 A -> B -> C, 這時就存在傳遞依賴,C 應該從表中脫離出來 與 B 共同形成一張表。
BC範式
符合3NF,并且,消除每一個屬性對候選鍵的傳遞依賴
2、MySQL外連接配接知道嗎?左外連接配接和右外連接配接是什麼,有什麼差別?什麼是内連接配接,完全連接配接
外連接配接分為左外連接配接和右外連接配接
左(外)連接配接,左表(a_table)的記錄将會全部表示出來,而右表(b_table)隻會顯示符合搜尋條件的記錄。右表記錄不足的地方均為NULL
與左(外)連接配接相反,右(外)連接配接,左表(a_table)隻會顯示符合搜尋條件的記錄,而右表(b_table)的記錄将會全部表示出來。左表記錄不足的地方均為NULL。
完全連接配接就是左表和右表都是展示所有記錄
内連接配接是左右表都隻顯示符合搜尋條件的記錄
性能優化
1、mysql性能優化
Mysql高性能優化規範建議
MySQL 索引
索引是在存儲引擎層實作的,而不是在伺服器層實作的,是以不同存儲引擎具有不同的索引類型和實作。
索引的優點
1. 通過建立索引樹,從上往下搜尋索引樹大大減少了伺服器需要掃描的資料行數。
2. 幫助伺服器避免進行排序和分組,以及避免建立臨時表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。臨時表主要是在排序和分組過程中建立,不需要排序和分組,也就不需要建立臨時表)。
3. 将随機 I/O 變為順序 I/O(B+Tree 索引是有序的,會将相鄰的資料都存儲在一起)。
為什麼不對表的每個列建立一個索引
1. 索引會占記憶體空間
2. 維護索引和修改索引有一定的開銷
索引選取類型
1、越小的資料類型通常更好:越小的資料類型通常在磁盤、記憶體和CPU緩存中都需要更少的空間,處理起來更快。
2、簡單的資料類型更好:整型資料比起字元,處理開銷更小,因為字元串的比較更複雜。
3、盡量避免NULL:應該指定列為NOT nuLL,在MySQL中, 含有空值的列很難進行查詢優化,因為它們使得索引、索引的統計資訊以及比較運算更加複雜
什麼場景不适合建立索引
第一,對于那些在查詢中很少使用或者參考的列不應該建立索引。這是因 為,既然這些列很少使用到,是以有索引或者無索引,并不能提高查詢速度。相反,由于增加了索引,反而降低了系統的維護速度和增大了空間需求。
第二,對于那 些隻有很少資料值的列也不應該增加索引。因為本來結果集合就是相當于全表查詢了,是以沒有必要。這是因為,由于這些列的取值很少,例如人事表的性别列,在查詢的結果中,結果集的資料行占了表中資料行的很大比 例,即需要在表中搜尋的資料行的比例很大。增加索引,并不能明顯加快檢索速度。
第三,對于那些定義為text, image和bit資料類型的列不應該增加索引。這是因為,這些列的資料量要麼相當大,要麼取值很少。
第四,當修改開銷遠遠大于檢索開銷時,不應該建立索 引。這是因為,修改性能和檢索性能是互相沖突的。當增加索引時,會提高檢索性能,但是會降低修改性能。當減少索引時,會提高修改性能,降低檢索性能。因 此,當修改性能遠遠大于檢索性能時,不應該建立索引。
第五,不會出現在where條件中的字段不該建立索引。
什麼樣的字段适合建立索引
1、表的主鍵、外鍵必須有索引;外鍵是唯一的,而且經常會用來查詢
2、資料量超過300的表應該有索引;
3、經常與其他表進行連接配接的表,在連接配接字段上應該建立索引;經常連接配接查詢,需要有索引
4、經常出現在Where子句中的字段,加快判斷速度,特别是大表的字段,應該建立索引,建立索引,一般用在select ……where f1 and f2 ,我們在f1或者f2上建立索引是沒用的。隻有兩個使用聯合索引才能有用
5、經常用到排序的列上,因為索引已經排序。
6、經常用在範圍内搜尋的列上建立索引,因為索引已經排序了,其指定的範圍是連續的
索引失效:
所謂的索引失效指的是:假如or連接配接的倆個查詢條件字段中有一個沒有單列索引的話,引擎會放棄索引而産生全表掃描。
索引實體分類
聚簇索引和非聚簇索引
所謂聚集和非聚集:非聚集索引葉子頁包含一個指向表中的記錄的指針位址,記錄的實體順序和索引的順序不一緻;聚集索引則資料行和鍵值一起儲存在葉子頁 而且記錄的排列順序與索引的排列順序一緻。
由于InnoDB正式按照 聚集索引的結構來存儲表的,聚簇索引的索引是主鍵,是以隻能故一張表隻能有一個聚簇索引。輔助索引的存在不影響聚簇索引中資料的組織,是以一張表可以有多個輔助索引
InnoDB 的主鍵索引是 聚簇索引, 輔助索引是 非聚簇索引,葉子結點存儲的的是主鍵和關鍵字。
MyISAM 的主鍵索引和輔助索引都是 非聚簇索引。
聚簇索引的優缺點
優點:
1.資料通路更快,因為聚簇索引将索引和資料儲存在同一個B+樹中,是以從聚簇索引中擷取資料比非聚簇索引更快,
2. 聚簇索引對于主鍵的排序查找和範圍查找速度非常快
缺點:
1. 插入速度嚴重依賴于插入順序,按照主鍵的順序插入是最快的方式,否則将會出現頁分裂,嚴重影響性能。是以,對于InnoDB表,我們一般都會定義一個自增的ID列為主鍵
2. 更新主鍵的代價很高,因為将會導緻被更新的行移動。是以,對于InnoDB表,我們一般定義主鍵為不可更新。
3.二級索引通路需要兩次索引查找,第一次找到主鍵值,第二次根據主鍵值找到行資料。
索引邏輯分類
mysql的索引分為單列索引(主鍵索引,唯一索引,普通索引)群組合索引。
單列索引:一個索引隻包含一個列,一個表可以有多個單列索引。
組合索引:一個組合索引包含兩個或兩個以上的列,
字首索引
對于列的值較長,比如BLOB、TEXT、VARCHAR,就必須建立字首索引,即将值的前一部分作為索引。這樣既可以節約空間,又可以提高查詢效率。但無法使用字首索引做 ORDER BY 和 GROUP BY,也無法使用字首索引做覆寫掃描。
覆寫索引
索引的字段正好是覆寫查詢語句[select子句]與查詢條件[Where子句]中所涉及的字段。能通過檢索索引就可以讀取想要的資料,那就不需要再到資料表中讀取行了
覆寫索引的優化及限制
覆寫索引是一種非常強大的工具,能大大提高查詢性能,隻需要讀取索引而不需要讀取資料,有以下優點:
1、索引項通常比記錄要小,是以MySQL通路更少的資料。
2、索引都按值得大小存儲,相對于随機通路記錄,需要更少的I/O。
3、資料引擎能更好的緩存索引,比如MyISAM隻緩存索引。
4、覆寫索引對InnoDB尤其有用,因為InnoDB使用聚集索引組織資料,如果二級索引包含查詢所需的資料,就不再需要在聚集索引中查找了。
限制:
1、覆寫索引也并不适用于任意的索引類型,索引必須存儲列的值。
2、Hash和full-text索引不存儲值,是以MySQL隻能使用BTree。
3、不同的存儲引擎實作覆寫索引都是不同的,并不是所有的存儲引擎都支援覆寫索引。
4、如果要使用覆寫索引,一定要注意SELECT清單值取出需要的列,不可以SELECT * ,因為如果将所有字段一起做索引會導緻索引檔案過大,查詢性能下降。
最左字首原則:
顧名思義是最左優先,以最左邊的為起點任何連續的索引都能比對上,
注:如果第一個字段是範圍查詢需要單獨建一個索引
注:在建立聯合索引時,要根據業務需求,where子句中使用最頻繁的一列放在最左邊。這樣的話擴充性較好,比如
userid
經常需要作為查詢條件,而
mobile
不常常用,則需要把
userid
放在聯合索引的第一位置,即最左邊
同時存在聯合索引和單列索引(字段有重複的),這個時候查詢mysql會怎麼用索引呢?
這個涉及到mysql本身的查詢優化器政策了,當一個表有多條索引可走時, Mysql 根據查詢語句的成本來選擇走哪條索引;
聯合索引本質:
當建立(a,b,c)聯合索引時,相當于建立了(a)單列索引,(a,b)聯合索引以及 (a,b,c)聯合索引,想要索引生效的話,隻能使用 a和a,b和a,b,c三種組合;當然,我們上面測試過,a,c組合也可以,但實際上隻用到了a的索引,c并沒有用到!
通俗了解:
利用索引中的附加列,您可以縮小搜尋的範圍,但使用一個具有兩列的索引 不同于使用兩個單獨的索引。複合索引的結構與電話簿類似,人名由姓和名構成,電話簿首先按姓氏對進行排序,然後按名字對有相同姓氏的人進行排序。如果您知道姓,電話簿将非常有用;如果您知道姓和名,電話簿則更為有用,但如果您隻知道名不姓,電話簿将沒有用處。
是以說建立複合索引時,應該仔細考慮列的順序。對索引中的所有列執行搜尋或僅對前幾列執行搜尋時,複合索引非常有用;僅對後面的任意列執行搜尋時,複合索引則沒有用處。
複合索引與單列索引的比較:
1. 如果表中大多數都是單條件查詢,那用單列索引更劃得來
2. 有多條件聯合查詢時最好建聯合索引,多個單列索引在多條件查詢時優化器會選擇最優索引政策,可能隻用一個索引,也可能将多個索引全用上! 但多個單列索引底層會建立多個B+索引樹,比較占用空間,也會浪費一定搜尋效率,
其他知識點:
1、需要加索引的字段,要在where條件中
2、資料量少的字段不需要加索引;因為建索引有一定開銷,如果資料量小則沒必要建索引(速度反而慢)
3、避免在where子句中使用or來連接配接條件,因為如果倆個字段中有一個沒有索引的話,引擎會放棄索引而産生全表掃描
4、聯合索引比對每個列分别建索引更有優勢,因為索引建立得越多就越占磁盤空間,在更新資料的時候速度會更慢。另外建立多列索引時,順序也是需要注意的,應該将嚴格的索引放在前面,這樣篩選的力度會更大,效率更高。
索引的底層實作
btree、b+tree
1. B+Tree 索引
是大多數 MySQL 存儲引擎的預設索引類型。
因為不再需要進行全表掃描,隻需要對樹進行搜尋即可,是以查找速度快很多。
因為 B+ Tree 的有序性,是以除了用于查找,還可以用于排序和分組。
可以指定多個列作為索引列,多個索引列共同組成鍵。
适用于全鍵值、鍵值範圍和鍵字首查找,其中鍵字首查找隻适用于最左字首查找。如果不是按照索引列的順序進行查找,則無法使用索引。
InnoDB 的 B+Tree 索引分為主索引和輔助索引。主索引的葉子節點 data 域記錄着完整的資料記錄,這種索引方式被稱為聚簇索引。因為無法把資料行存放在兩個不同的地方,是以一個表隻能有一個聚簇索引。
輔助索引的葉子節點的 data 域記錄着主鍵的值,是以在使用輔助索引進行查找時,需要先查找到主鍵值,然後再到
主索引中進行查找。
2. 哈希索引
哈希索引能以 O(1) 時間進行查找,但是失去了有序性:
無法用于排序與分組;
隻支援精确查找,無法用于部分查找和範圍查找。
InnoDB 存儲引擎有一個特殊的功能叫“自适應哈希索引”,當某個索引值被使用的非常頻繁時,會在 B+Tree 索引之
上再建立一個哈希索引,這樣就讓 B+Tree 索引具有哈希索引的一些優點,比如快速的哈希查找。
3、BST(二叉查找樹)
1.vs二分查找,BST在左右子樹節點個數差不多時,查找性能逼近二分查找,但在增删節點時,BST需要的記憶體比二分查找少。2.缺點:平衡性差,動态增删節點可能導緻退化為連結清單,查找效率降低。
3.4AVL樹vsRBtree: avl樹是嚴格平衡樹,而rbtree是弱平衡樹,都是通過旋轉來保持平衡,而在增删節點時,嚴格平衡樹旋轉的次數比弱平衡旋轉的次數多,當搜尋節點的次數遠遠大于增删節點的次數時,旋轉AVL樹,當搜尋節點的次數與增删節點的次數差不多時選擇RBtree效率高。
4、磁盤讀取及預讀的過程及時間消耗?
定位柱面時間(最長)、旋轉至扇區時間、讀寫扇區時間
5、btree定義?
1.每個節點最多有 m 個子樹
2.若根不是葉子結點,則根節點至少有兩個子樹
3.分支節點至少擁有m/2棵子樹(除根和葉子)
4.所有葉子節點都在同一層,這些葉子結點不存儲有效的資訊
5. 每個節點最多可以有m-1個 key 并且升序排列,相同數量的 key 在btree中生成的節點要遠遠小于二叉搜尋樹節點,相差的節點數目正比于樹的高度正比與磁盤io的次數,達到一定數量時,性能差異明顯。
6、為什麼btree查找效率高?
多路查找-->降低樹的高度-->減少磁盤io的次數-->節省磁盤通路的時間-->更快定位到資料庫檔案
查找效率高有兩個原因,一是多路性,每個結點有若幹個關鍵字,相同數量的 key 在btree中生成的節點要遠遠小于二叉搜尋樹節點,相差的節點數目正比于樹的高度正比與磁盤io的次數,達到一定數量時,性能差異明顯。二是平衡性,是以他效率穩定,不像二叉查找樹那樣會退化成連結清單。
7、btree節點如何定義?vs二叉搜尋樹
二叉搜尋樹:key、value、left指針、right指針
btree節點:多個key key1 key2..多個value value1 value2..多個pointer指針 pointer1、pointer2..
8、 b+tree 與B樹的差別
1. 葉子節點包含了所有關鍵字資訊以及指向這些關鍵字記錄的指針,并且葉子節點大小本身就是從小到大的順序連結。
2. 所有的非終端結點可以看成是索引部分,不含有效資訊 (而B 樹的非終節點也包含需要查找的有效資訊)
9、 為什麼b+tree比btree更适合做檔案的索引、資料庫索引?
1.btree在提高磁盤 io 性能同時并沒有解決元素周遊效率低下的問題,b+tree隻要周遊葉子節點就可周遊整棵樹。
2.在資料庫中基于範圍的查找很頻繁,btree每次都要從根節點查,效率低。b+tree隻要找到範圍左邊界的葉子結點,可以順着葉子結點,找到相應範圍的所有元素。
3. B+-tree的查詢效率更加穩定
由于非終結點并不是最終指向檔案内容的結點,而隻是葉子結點中關鍵字的索引。是以任何關鍵字的查找必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導緻每一個資料的查詢效率相當
補充
真實資料庫中的B+樹應該是非常扁平的,也就是說高度非常小,也就說叉數非常多,每個結點的字樹非常多,而且B+樹的索引節點是非常小的,一次性可以加載到記憶體,這樣就可以用少量的記憶體換取隻需一次訪存即可擷取到資料的恐怖效率。
B+樹的叉數可以達到1000多叉,存儲 22G 容量的表高度也才3層,一次訪存即可擷取資料。
10、b+樹和b樹分别有什麼應用
B樹和B+樹大量應用在資料庫和檔案系統當中。但是多采用B+樹,檔案系統和資料庫的索引都是存在硬碟上的,并且如果資料量大的話,不一定能一次性加載到記憶體中。
mongoDB資料庫用的是B樹
11、hashmap為什麼用紅黑樹不用b樹
因為如果采用b樹的話,在資料量不是很多的情況下,資料都會“擠在”一個結點裡面。這個時候周遊效率就退化成了連結清單。
4. 解釋一下什麼是池化設計思想。什麼是資料庫連接配接池?為什麼需要資料庫連接配接池?
池話設計應該不是一個新名詞。我們常見的如java線程池、jdbc連接配接池、redis連接配接池等就是這類設計的代表實作。這種設計會初始預設資源,解決的問題就是抵消每次擷取資源的消耗,如建立線程的開銷,擷取遠端連接配接的開銷等。就好比你去食堂打飯,打飯的大媽會先把飯盛好幾份放那裡,你來了就直接拿着飯盒加菜即可,不用再臨時又盛飯又打菜,效率就高了。除了初始化資源,池化設計還包括如下這些特征:池子的初始值、池子的活躍值、池子的最大值等,這些特征可以直接映射到java線程池和資料庫連接配接池的成員屬性中。——這篇文章對池化設計思想介紹的還不錯,直接複制過來,避免重複造輪子了。
資料庫連接配接本質就是一個
socket 的連接配接。資料庫服務端還要維護一些緩存和使用者權限資訊之類的
是以占用了一些記憶體。我們可以把資料庫連接配接池是看做是維護的資料庫連接配接的緩存,以便将來需要對資料庫的請求時可以重用這些連接配接。為每個使用者打開和維護資料庫連接配接,尤其是對動态資料庫驅動的網站應用程式的請求,既昂貴又浪費資源。在連接配接池中,建立連接配接後,将其放置在池中,并再次使用它,是以不必建立新的連接配接。如果使用了所有連接配接,則會建立一個新連接配接并将其添加到池中。連接配接池還減少了使用者必須等待建立與資料庫的連接配接的時間。
這種設計會初始預設資源,解決的問題就是抵消每次擷取資源和釋放資源造成的開銷。連接配接池也是這樣,預先建立好一個連接配接池,在池中建立一定數量的連接配接,每當使用者需要連接配接資料庫,就從池中取出一個連接配接,使用完畢之後放回池中,這既可以減少連接配接建立和釋放的開銷,便于連接配接的管理,也可以降低使用者等待資料庫的延遲。
攻擊
sql注入攻擊
簡介:
SQL注入是普通常見的網絡攻擊方式之一,它的原理是通過在參數中輸入特殊符号,來篡改并通過程式SQL語句的條件判斷。
比如:
使用者名:1
密 碼:1' OR '1'='1
那麼程式接收到參數後,SQL語句就變成了:SELECT * FROM user WHERE name = '1' and password= '1' OR '1'='1 '; 或者
使用者名:1'; DROP DATABASE root;--
密碼:1
那麼程式接收到參數後,SQL語句就變成了:SELECT * FROM user WHERE name = '1'; DROP DATABASE root;--and password= '1'; 解決辦法:
1. 不允許帶有特殊字元
2. 對單引号或雙引号進行轉義
3. 對 sql 語句進行預編譯,因為SQL注入攻擊隻對SQL語句的編譯過程有破壞作用,進行預編譯後,傳入的參數隻作為字元串,不會再進行一次編譯,SQL注入攻擊也就失效了
MySQL 的體系結構

MySQL是由連接配接池、管理工具和服務、SQL接口、解析器、優化器、緩存、存儲引擎、檔案系統組成。
連接配接池:
由于每次建立連接配接需要消耗很多時間,連接配接池的作用就是将這些連接配接緩存下來,下次可以直接用已經建立好的連接配接,提升伺服器性能。
管理工具和服務:
系統管理和控制工具,例如備份恢複、Mysql複制、叢集等
SQL接口:
接受使用者的SQL指令,并且傳回使用者需要查詢的結果。比如select from就是調用SQL Interface
解析器:
SQL指令傳遞到解析器的時候會被解析器驗證和解析。比如驗證是否符合文法樹等
解析器是由Lex和YACC實作的,是一個很長的腳本, 主要功能:
a . 将SQL語句分解成資料結構,并将這個結構傳遞到後續步驟,以後SQL語句的傳遞和處理就是基于這個結構的
b. 如果在分解構成中遇到錯誤,那麼就說明這個sql語句是不合理的
優化器:
查詢優化器,SQL語句在查詢之前會使用查詢優化器對查詢進行優化。他使用的是“選取-投影-聯接”政策進行查詢。
用一個例子就可以了解: select uid,name from user where gender = 1;
這個select 查詢先根據where 語句進行選取,而不是先将表全部查詢出來以後再進行gender過濾
這個select查詢先根據uid和name進行屬性投影,而不是将屬性全部取出以後再進行過濾
将這兩個查詢條件聯接起來生成最終查詢結果
緩存器:
查詢緩存,如果查詢緩存有命中的查詢結果,查詢語句就可以直接去查詢緩存中取資料。
通過LRU算法将資料的冷端溢出,未來得及時重新整理到磁盤的資料頁,叫髒頁。
這個緩存機制是由一系列小緩存組成的。比如表緩存,記錄緩存,key緩存,權限緩存等
存儲引擎
通過 show engines; 可以檢視資料庫的存儲引擎插件
負責MySQL中資料的存儲與提取。 伺服器中的查詢執行引擎通過API與存儲引擎進行通信,通過接口屏蔽了不同存儲引擎之間的差異。關系資料庫中資料的存儲是以表的形式存儲的,是以說存儲的一張張的表,而不是一個個的資料庫。MySQL采用插件式的存儲引擎,是以隻要給資料庫提供插件,就可以增加存儲引擎,MySql資料庫提供了多種存儲引擎。使用者可以根據不同的需求為資料表選擇不同的存儲引擎,使用者也可以根據自己的需要編寫自己的存儲引擎。甚至一個庫中不同的表使用不同的存儲引擎,這些都是允許的。
MyISAM存儲引擎
由于該存儲引擎不支援事務、也不支援外鍵,是以通路速度較快。是以當對事務完整性沒有要求并以通路為主的應用适合使用該存儲引擎。
檔案:
.frm檔案:與表相關的中繼資料資訊都存放在frm檔案,包括表結構的定義資訊等。
.MYD檔案:MyISAM存儲引擎專用,用于存儲MyISAM表的資料
.MYI檔案:MyISAM存儲引擎專用,用于存儲MyISAM表的索引相關資訊
InnoDB存儲引擎
mysql 5.5版本以後預設的存儲引擎
由于該存儲引擎在事務上具有優勢,即支援具有送出、復原及崩潰恢複能力等事務特性,他在運作時會在記憶體中建立緩沖池,用于緩沖資料和索引。支援行鎖,并發度高。主鍵索引為聚簇索引,是以比MyISAM存儲引擎占用更多的磁盤空間。是以當需要頻繁的更新、删除操作,同時還對事務的完整性要求較高,需要實作并發控制,建議選擇。
.ibd檔案:存放innodb表的資料檔案。
MEMORY
MEMORY存儲引擎存儲資料的位置是記憶體,是以通路速度最快,但是安全上沒有保障。适合于需要快速的通路或臨時表。
BLACKHOLE
黑洞存儲引擎,寫入的任何資料都會消失,可以應用于主備複制中的分發主庫。
存儲引擎的另一個知識總結
InnoDB 和 MyISAM 的差別:
目前比較普及的存儲引擎是MyISAM和InnoDB。MyISAM與InnoDB的主要的不同點在于性能和事務控制上。MyISAM是早期ISAM(Indexed Sequential Access Method 索引順序存取法,MySQL5.0之後已經不支援ISAM了)的擴充實作
ISAM被設計為适合處理讀頻率遠大于寫頻率這樣的情況,是以ISAM以及後來的MyISAM都沒有考慮對事物的支援,排除了TPM,不需要事務記錄,ISAM的查詢效率相當可觀,而且記憶體占用很少。
MyISAM在繼承了這類優點的同時,與時俱進地提供了大量實用的新特性和相關工具。例如考慮到并發控制,提供了表級鎖
InnoDB被設計成适用于高并發讀寫的情況,支援相容ACID的事務(類似于PostgreSQL),以及參數 完整性(即對外鍵的支援)。一般來說,如果需要事務支援,并且有較高的并發讀寫頻率,InnoDB是不錯的選擇。
InnoDB引擎
InnoDB是一個事務型的存儲引擎,支援復原,設計目标是處理大量資料時提供高性能的服務,它在運作時會在記憶體中建立緩沖池,用于緩沖資料和索引
InnoDB引擎優點
1、支援事務處理、ACID事務特性;
2、實作了SQL标準的四種隔離級别;
3、支援行級鎖和外鍵限制,行鎖優點是粒度小,适用于高并發的頻繁表修改,高并發使性能優于 MyISAM。缺點是系統消耗較大。4、可以利用事務日志進行資料恢複。 InnoDB引擎缺點
1.
因為它沒有儲存表的行數,當使用COUNT統計時會掃描全表。
2、索引不僅緩存自身,也緩存資料,相比 MyISAM 需要更大的記憶體。 MyISAM引擎
MyISAM引擎優點
1.高性能讀取;
2.因為它儲存了表的行數,當使用COUNT統計時不會掃描全表; MyISAM引擎缺點
1、鎖級别為表鎖,表鎖優點是開銷小,加鎖快;缺點是鎖粒度大,發生鎖沖動機率較高,容納并發能力低,這個引擎适合查詢為主的業務。
2、此引擎不支援事務,也不支援外鍵。
3、INSERT和UPDATE操作需要鎖定整個表; 适用場景
MyISAM适合:(1)做很多count 的計算;(2)插入不頻繁,查詢非常頻繁;(3)沒有事務。
InnoDB适合:(1)可靠性要求比較高,或者要求事務;(2)表更新和查詢都相當的頻繁,并且表鎖定的機會比較大的情況。 補充:
OLTP(聯機事務處理)和OLAP(聯機分析處理)