spark的standlone模式安裝
安裝一個standlone模式的spark叢集,這裡是最基本的安裝,并測試一下如何進行任務送出。
require:提前安裝好jdk 1.7.0_80 ;scala 2.11.8
可以參考官網的說明:http://spark.apache.org/docs/latest/spark-standalone.html
1. 到spark的官網下載下傳spark的安裝包
http://spark.apache.org/downloads.html
spark-2.0.2-bin-hadoop2.7.tgz.tar
2. 解壓縮
cd /home/hadoop/soft
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz.tar
ln -s /home/hadoop/soft/spark-2.0.2-bin-hadoop2.7 /usr/local/spark
3.配置環境變量
su - hadoop
vi ~/.bashrc
export SPARK_HOME="/usr/local/spark"
export PATH="$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH"
source ~/.bashrc
which spark-shell
4.修改spark的配置
進入spark配置目錄進行配置:
cd /usr/local/spark/conf
cp log4j.properties.template log4j.properties ##修改 log4j.rootCategory=WARN, console
cp spark-env.sh.template spark-env.sh
vi spark-env.sh ##設定spark的環境變量,進入spark-env.sh檔案添加:
export SPARK_HOME=/usr/local/spark
export SCALA_HOME=/usr/local/scala
至此,Spark就已經安裝好了
5. 運作spark:
Spark-Shell指令可以進入spark,可以使用Ctrl D組合鍵退出Shell:
Spark-Shell
hadoop@ubuntuServer01:~$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/12/08 16:44:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/08 16:44:44 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.17.50:4040
Spark context available as 'sc' (master = local[*], app id = local-1481186684381).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_80)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
啟動spark服務:
start-master.sh ##
hadoop@ubuntuServer01:~$ start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-ubuntuServer01.out
hadoop@ubuntuServer01:~$ jps
2630 Master
2683 Jps
這裡我們啟動了主結點,jps多了一個Master的spark程序。
如果主節點啟動成功,master預設可以通過web通路:http://ubuntuServer01:8080,檢視sparkMaster的UI。
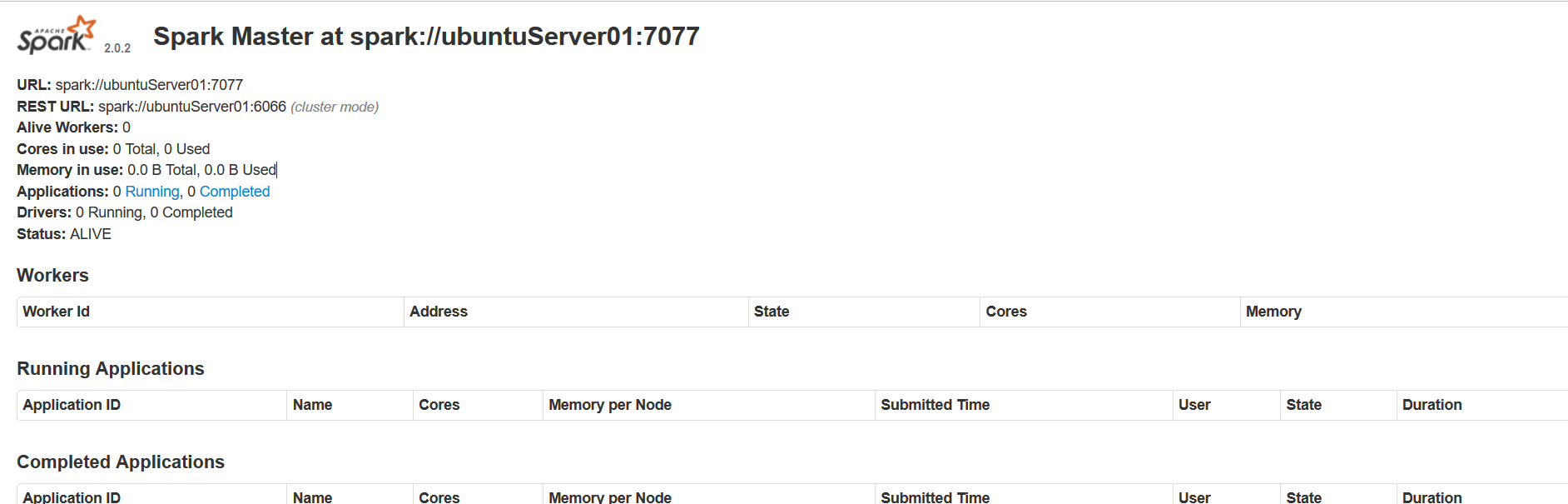
圖中所述的spark://ubuntuServer01:7077 就是從結點啟動的參數。
spark的master節點HA可以通過zookeeper和Local File System兩種方法實作,具體可以參考官方的文檔 http://spark.apache.org/docs/latest/spark-standalone.html#high-availability。
啟動spark的slave從節點
start-slave.sh spark://ubuntuServer01:7077
hadoop@ubuntuServer01:~$ start-slave.sh spark://ubuntuServer01:7077
starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-ubuntuServer01.out
hadoop@ubuntuServer01:~$ jps
2716 Worker
2765 Jps
2630 Master
hadoop@ubuntuServer01:~$
運作jps指令,發現多了一個spark的worker程序。UI頁面上的workers清單中也多了一條記錄。

6. 運作一個Application在spark叢集上。
運作一個互動式的spark shell在spark叢集中:通過如下指令行:
spark-shell --master spark://ubuntuServer01:7077
hadoop@ubuntuServer01:~$ spark-shell --master spark://ubuntuServer01:7077
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/12/08 17:51:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/08 17:51:05 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.17.50:4040
Spark context available as 'sc' (master = spark://ubuntuServer01:7077, app id = app-20161208175104-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_80)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
從運作日志中可以看到job的UI(Spark web UI)頁面位址:http://192.168.17.50:4040
和application id "app-20161208175104-0000",任務運作結束後,Spark web UI頁面也會随之關閉。
使用spark-submit腳本執行一個spark任務:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://ubuntuServer01:7077 \
--executor-memory 1G \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.0.2.jar \
10
使用spark-submit 送出 application可以參考spark的官方文檔。
http://spark.apache.org/docs/latest/submitting-applications.html
作者:
丹江湖畔養蜂子的趙大爹
出處:http://www.cnblogs.com/honeybee/
關于作者:丹江湖畔養蜂子的趙大爹
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連結