上一篇專欄文章我們介紹了基于視訊的人臉表情識别的相關概念,了解了目前基于視訊的人臉表情識别領域最常用的幾個資料集以及經典的實作方法。本文将延續上一篇的内容,分享近幾年該領域一些主流的基于深度學習的方法實作。
作者&編輯 | Menpinland
1. 峰值幀引導的深度網絡
Zhao等人[1]嘗試僅用兩幀的人臉圖像解決序列問題的方法。網絡的輸入是一張表情峰值幀和非峰值幀,在訓練過程中,使用正則化的方式建立非峰值表情到峰值表情的映射(類似之後提出的對抗學習思想)。類似地,Kim等人[2]用3、5幀的人臉圖像實作基于視訊序列的表情識别和微表情識别任務。用這類方法的最大優點就是不需要用到序列的全部資料,訓練更簡單,推理所需要的參數也更少。但最大的問題是需要提前知道哪一幀是峰值幀哪一幀是非峰值幀,在實際應用中這一點很難做到。
推薦指數:✦✦✧✧✧
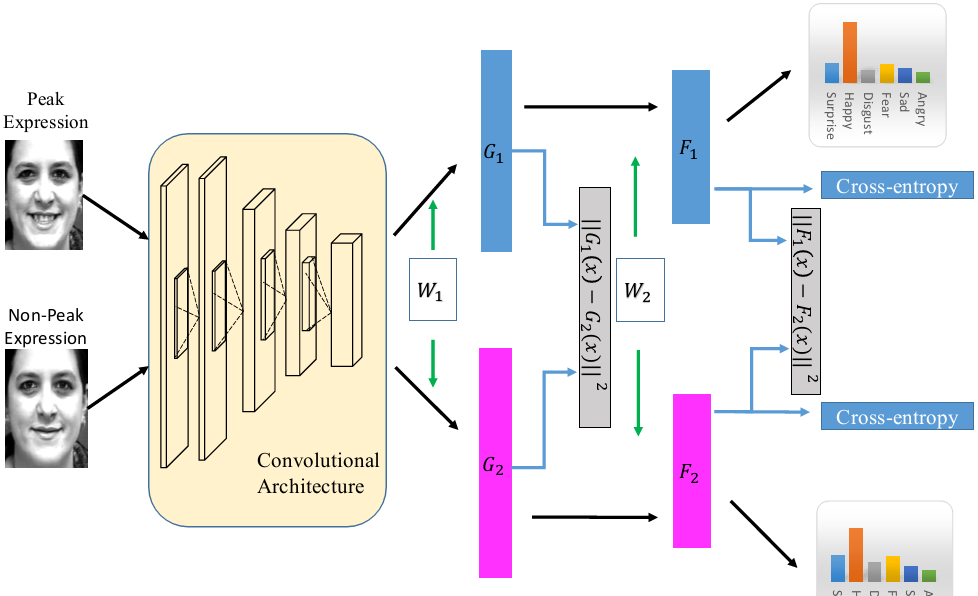
圖1|[1]中提出方法示意圖
[1] Zhao X, Liang X, Liu L, et al. Peak-piloted deep network for facial expression recognition[C]//European conference on computer vision. Springer, Cham, 2016: 425-442.
[2] Kim D H, Baddar W J, Jang J, et al. Multi-objective based spatio-temporal feature representation learning robust to expression intensity variations for facial expression recognition[J]. IEEE Transactions on Affective Computing, 2017, 10(2): 223-236.
2. 解決時序問題經典網絡的應用
解決時序問題有兩種經典的深度學習方法:基于3DCNN和基于CNN-RNN的方法(卷積層用于特征提取)。Fan等人[3]基于上述兩種網絡分别得到預測結果,再結合基于語音特征預測得到的結果,進行決策級的融合進而得到了最終的識别結果。Vielzeuf等人[4]基于相似的思路做了細微的改進,在公開資料集上取得了更好的識别效果。
推薦指數:✦✦✦✧✧

圖2|[3]中提出的方法示意圖
[3] Fan Y, Lu X, Li D, et al. Video-based emotion recognition using CNN-RNN and C3D hybrid networks[C]//Proceedings of the 18th ACM International Conference on Multimodal Interaction. 2016: 445-450.
[4] Vielzeuf V, Pateux S, Jurie F. Temporal multimodal fusion for video emotion classification in the wild[C]//Proceedings of the 19th ACM International Conference on Multimodal Interaction. 2017: 569-576.
3. 單張圖像融合時序資料
在基于視訊的人臉表情識别任務中,深度時空網絡(deep spatial-temporal networks)由于其能融合時間和空間特征深受研究者的青睐。通常,3DCNN用于提取圖檔序列的空間特征,RNN用于提取時序特征。然而這類方法在兩個分支網絡都需要用到序列中所有的資料,計算量較大。是以,一些研究者考慮在盡可能保留表情特征的基礎上減少網絡輸入的大小。Zhang等人[5]用單張圖檔取代人臉圖檔序列以提取空間特征,用人臉特征點序列取代人臉圖檔序列以提取時間特征,同樣實作了較好的識别效果。
圖3|[5]中提出方法示意圖
[5] Zhang K, Huang Y, Du Y, et al. Facial expression recognition based on deep evolutional spatial-temporal networks[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4193-4203.
4. 對各種人臉表情變化模式魯棒的LSTM
在之前專欄讨論基于圖檔的人臉表情識别時,我們了解到人的身份、姿态、光照等模式的變化會對識别效果造成較大的影響。在基于視訊的人臉表情識别中,這種情況同樣存在。Baddar等人還發現,解決時序問題常用的LSTM對于人臉各種模式的變化并不魯棒。如圖4所示,他們挑選了一組表情相同但是光照不同的圖檔,同時對每張圖檔進行複制,得到兩組序列,每個序列中的每張圖檔相同。理論上,序列每張圖檔一樣,兩組序列除了光照條件不同,其他都相同,那麼經過LSTM提取出的特征,單個序列特征值應該固定的,兩個序列特征值應該相同或相似。但從可視化的結果可觀察到,兩組特征差異較大。針對上述問題,Baddar等人[6]嘗試直接修改LSTM核内部結構,引入可編碼偏差的單元(如圖5(b)所示),進而提高對各種變化模式的魯棒性。同年,在IEEE Transactions On Affective Computing的一篇論文中,Baddar等人[7]同樣針對LSTM存在的問題,建構一種時序編碼結構以提升基于視訊的表情識别中實時預測的效果。
推薦指數:✦✦✦✦✧
圖4|LSTM對人臉表情變化模式并不魯棒
圖5|LSTM核原始結構(a)和[6]中修改後的LSTM核結構(b)
[6] Baddar W J, Ro Y M. Mode variational lstm robust to unseen modes of variation: Application to facial expression recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 3215-3223.
[7] Baddar W J, Lee S, Ro Y M. On-the-Fly Facial Expression Prediction using LSTM Encoded Appearance-Suppressed Dynamics[J]. IEEE Transactions on Affective Computing, 2019.
5. 含注意力機制的基于視訊人臉表情識别
前面提到,如果能夠提前獲得人臉序列的表情峰值幀,将有利于提升基于視訊的人臉表情識别的準确率,但實作這樣的算法并不容易。針對這一點,Meng等人[8]引入注意力機制,在訓練過程中區分出更具代表性的幀進而提升後續表情識别效果。Zhou等人[9]則利用注意力機制和雙線性池化(bilinear pooling)建構多模态表情特征融合方法;Chen等人[10]則在時空注意力的基礎上增加了3D通道注意力以生成更具代表性的特征。
代碼:https://github.com/MengDebin18/Emotion-FAN
圖6|[8]中提出的注意力機制
圖7|[9]中提出方法的示意圖
[8] Meng D, Peng X, Wang K, et al. Frame attention networks for facial expression recognition in videos[C]//2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019: 38663870.
[9] Zhou H, Meng D, Zhang Y, et al. Exploring emotion features and fusion strategies for audio-video emotion recognition[C]//2019 International Conference on Multimodal Interaction. 2019: 562-566.
[10] Chen W, Zhang D, Li M, et al. STCAM: Spatial-Temporal and Channel Attention Module for Dynamic Facial Expression Recognition[J]. IEEE Transactions on Affective Computing, 2020.
6. 利用背景資訊輔助表情識别
在基于視訊的人臉表情識别中,研究者往往會将研究的重點放在如何捕獲臉部的動态變化上。Lee等人[11]認為在自然狀态下,人的臉部表情變化并沒有那麼明顯、規律,單純利用人臉的變化并不能非常準确反正一段時間内人的真實情緒。而且與實驗室條件下拍攝得到的表情序列不同的是,自然狀态下的視訊除了人臉外還包含豐富的肢體動作、人物互動等資訊,如果能充分利用這些額外的資訊,将同樣有助于提升識别的效果。是以他們提出融合背景資訊的雙流法,一個分支用于提取人臉臉部變化特征,另一個網絡分支則編碼其餘的背景資訊以輔助表情識别。
圖8|[11]中提出的方法架構示意圖
[11] Lee J, Kim S, Kim S, et al. Context-aware emotion recognition networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 10143-10152.
總結
由于3DCNN和LSTM等網絡在處理時序問題的優越性,近幾年基于視訊的人臉表情識别任務主要圍繞這兩類方法進行有針對性的修改。同時,較大規模的人臉表情識别視訊資料集CAER(2019)和DFEW(2020)都是近兩年才開源,上文提到的方法大部分還隻是在小規模資料集上進行驗證,方法的有效性和魯棒性仍待商榷,是以該領域還有很大的空間值得研究者們去探索。
有三AI秋季劃-人臉圖像組
人臉圖像小組需要掌握與人臉相關的内容,學習的東西包括8大方向:人臉檢測,人臉關鍵點檢測,人臉識别,人臉屬性分析,人臉美顔,人臉編輯與風格化,三維人臉重建。。