Hive作為大資料平台舉足輕重的架構,以其穩定性和簡單易用性也成為目前建構企業級資料倉庫時使用最多的架構之一。
但是如果我們隻局限于會使用Hive,而不考慮性能問題,就難搭建出一個完美的數倉,是以Hive性能調優是我們大資料從業者必須掌握的技能。本文将給大家講解Hive性能調優的一些方法及技巧。
本文首發于公衆号:五分鐘學大資料
Hive性能問題排查的方式
當我們發現一條SQL語句執行時間過長或者不合理時,我們就要考慮對SQL進行優化,優化首先得進行問題排查,那麼我們可以通過哪些方式進行排查呢。
經常使用關系型資料庫的同學可能知道關系型資料庫的優化的訣竅-看執行計劃。 如Oracle資料庫,它有多種類型的執行計劃,通過多種執行計劃的配合使用,可以看到根據統計資訊推演的執行計劃,即Oracle推斷出來的未真正運作的執行計劃;還可以看到實際執行任務的執行計劃;能夠觀察到從資料讀取到最終呈現的主要過程和中間的量化資料。可以說,在Oracle開發領域,掌握合适的環節,選用不同的執行計劃,SQL調優就不是一件難事。
Hive中也有執行計劃,但是Hive的執行計劃都是預測的,這點不像Oracle和SQL Server有真實的計劃,可以看到每個階段的處理資料、消耗的資源和處理的時間等量化資料。Hive提供的執行計劃沒有這些資料,這意味着雖然Hive的使用者知道整個SQL的執行邏輯,但是各階段耗用的資源狀況和整個SQL的執行瓶頸在哪裡是不清楚的。
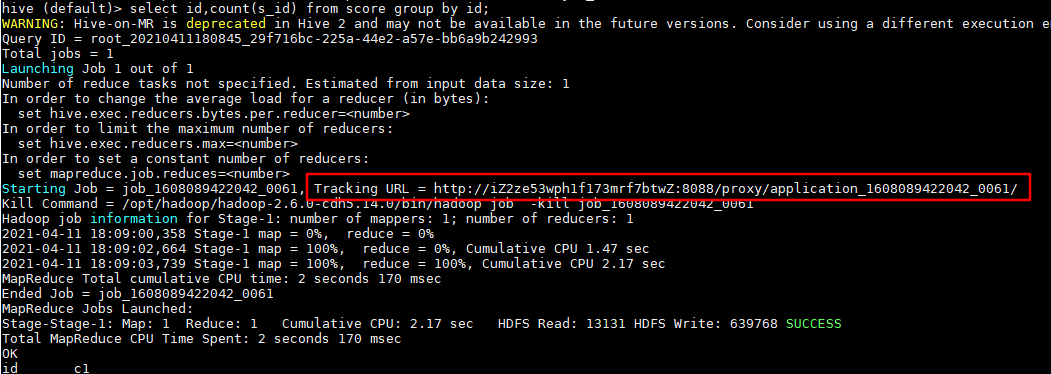
想要知道HiveSQL所有階段的運作資訊,可以檢視YARN提供的日志。檢視日志的連結,可以在每個作業執行後,在控制台列印的資訊中找到。如下圖所示:
Hive提供的執行計劃目前可以檢視的資訊有以下幾種:
- 檢視執行計劃的基本資訊,即explain;
- 檢視執行計劃的擴充資訊,即explain extended;
- 檢視SQL資料輸入依賴的資訊,即explain dependency;
- 檢視SQL操作相關權限的資訊,即explain authorization;
- 檢視SQL的向量化描述資訊,即explain vectorization。
在查詢語句的SQL前面加上關鍵字explain是檢視執行計劃的基本方法。 用explain打開的執行計劃包含以下兩部分:
- 作業的依賴關系圖,即STAGE DEPENDENCIES;
- 每個作業的詳細資訊,即STAGE PLANS。
Hive中的explain執行計劃詳解可看我之前寫的這篇文章:
Hive底層原理:explain執行計劃詳解
注:使用explain檢視執行計劃是Hive性能調優中非常重要的一種方式,請務必掌握!
總結:Hive對SQL語句性能問題排查的方式:
- 使用explain檢視執行計劃;
- 檢視YARN提供的日志。
Hive性能調優的方式
為什麼都說性能優化這項工作是比較難的,因為一項技術的優化,必然是一項綜合性的工作,它是多門技術的結合。我們如果隻局限于一種技術,那麼肯定做不好優化的。
下面将從多個完全不同的角度來介紹Hive優化的多樣性,我們先來一起感受下。
1. SQL語句優化
SQL語句優化涉及到的内容太多,因篇幅有限,不能一一介紹到,是以就拿幾個典型舉例,讓大家學到這種思想,以後遇到類似調優問題可以往這幾個方面多思考下。
1. union all
insert into table stu partition(tp)
select s_age,max(s_birth) stat,'max' tp
from stu_ori
group by s_age
union all
insert into table stu partition(tp)
select s_age,min(s_birth) stat,'min' tp
from stu_ori
group by s_age;
我們簡單分析上面的SQl語句,就是将每個年齡的最大和最小的生日擷取出來放到同一張表中,union all 前後的兩個語句都是對同一張表按照s_age進行分組,然後分别取最大值和最小值。對同一張表相同的字段進行兩次分組,這造成了極大浪費,我們能不能改造下呢,當然是可以的,為大家介紹一個文法:
from ... insert into ...
,這個文法将from前置,作用就是使用一張表,可以進行多次插入操作:
--開啟動态分區
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
from stu_ori
insert into table stu partition(tp)
select s_age,max(s_birth) stat,'max' tp
group by s_age
insert into table stu partition(tp)
select s_age,min(s_birth) stat,'min' tp
group by s_age;
上面的SQL就可以對stu_ori表的s_age字段分組一次而進行兩次不同的插入操作。
這個例子告訴我們一定要多了解SQL語句,如果我們不知道這種文法,一定不會想到這種方式的。
2. distinct
先看一個SQL,去重計數:
select count(1)
from(
select s_age
from stu
group by s_age
) b;
這是簡單統計年齡的枚舉值個數,為什麼不用distinct?
select count(distinct s_age)
from stu;
有人說因為在資料量特别大的情況下使用第一種方式能夠有效避免Reduce端的資料傾斜,但是事實如此嗎?
我們先不管資料量特别大這個問題,就目前的業務和環境下使用distinct一定會比上面那種子查詢的方式效率高。原因有以下幾點:
- 上面進行去重的字段是年齡字段,要知道年齡的枚舉值是非常有限的,就算計算1歲到100歲之間的年齡,s_age的最大枚舉值才是100,如果轉化成MapReduce來解釋的話,在Map階段,每個Map會對s_age去重。由于s_age枚舉值有限,因而每個Map得到的s_age也有限,最終得到reduce的資料量也就是map數量*s_age枚舉值的個數。
- distinct的指令會在記憶體中建構一個hashtable,查找去重的時間複雜度是O(1);group by在不同版本間變動比較大,有的版本會用建構hashtable的形式去重,有的版本會通過排序的方式, 排序最優時間複雜度無法到O(1)。另外,第一種方式(group by)去重會轉化為兩個任務,會消耗更多的磁盤網絡I/O資源。
- 最新的Hive 3.0中新增了 count(distinct ) 優化,通過配置
hive.optimize.countdistinct
- 第二種方式(distinct)比第一種方式(group by)代碼簡潔,表達的意思簡單明了,如果沒有特殊的問題,代碼簡潔就是優!
這個例子告訴我們,有時候我們不要過度優化,調優講究适時調優,過早進行調優有可能做的是無用功甚至産生負效應,在調優上投入的工作成本和回報不成正比。調優需要遵循一定的原則。
2. 資料格式優化
Hive提供了多種資料存儲組織格式,不同格式對程式的運作效率也會有極大的影響。
Hive提供的格式有TEXT、SequenceFile、RCFile、ORC和Parquet等。
SequenceFile是一個二進制key/value對結構的平面檔案,在早期的Hadoop平台上被廣泛用于MapReduce輸出/輸出格式,以及作為資料存儲格式。
Parquet是一種列式資料存儲格式,可以相容多種計算引擎,如MapRedcue和Spark等,對多層嵌套的資料結構提供了良好的性能支援,是目前Hive生産環境中資料存儲的主流選擇之一。
ORC優化是對RCFile的一種優化,它提供了一種高效的方式來存儲Hive資料,同時也能夠提高Hive的讀取、寫入和處理資料的性能,能夠相容多種計算引擎。事實上,在實際的生産環境中,ORC已經成為了Hive在資料存儲上的主流選擇之一。
我們使用同樣資料及SQL語句,隻是資料存儲格式不同,得到如下執行時長:
| 資料格式 | CPU時間 | 使用者等待耗時 |
|---|---|---|
| TextFile | 33分 | 171秒 |
| SequenceFile | 38分 | 162秒 |
| Parquet | 2分22秒 | 50秒 |
| ORC | 1分52秒 | 56秒 |
注:CPU時間:表示運作程式所占用伺服器CPU資源的時間。
使用者等待耗時:記錄的是使用者從送出作業到傳回結果期間使用者等待的所有時間。
查詢TextFile類型的資料表耗時33分鐘, 查詢ORC類型的表耗時1分52秒,時間得以極大縮短,可見不同的資料存儲格式也能給HiveSQL性能帶來極大的影響。
3. 小檔案過多優化
小檔案如果過多,對 hive 來說,在進行查詢時,每個小檔案都會當成一個塊,啟動一個Map任務來完成,而一個Map任務啟動和初始化的時間遠遠大于邏輯處理的時間,就會造成很大的資源浪費。而且,同時可執行的Map數量是受限的。
是以我們有必要對小檔案過多進行優化,關于小檔案過多的解決的辦法,我之前專門寫了一篇文章講解,具體可檢視:
解決hive小檔案過多問題
4. 并行執行優化
Hive會将一個查詢轉化成一個或者多個階段。這樣的階段可以是MapReduce階段、抽樣階段、合并階段、limit階段。或者Hive執行過程中可能需要的其他階段。預設情況下,Hive一次隻會執行一個階段。不過,某個特定的job可能包含衆多的階段,而這些階段可能并非完全互相依賴的,也就是說有些階段是可以并行執行的,這樣可能使得整個job的執行時間縮短。如果有更多的階段可以并行執行,那麼job可能就越快完成。
通過設定參數hive.exec.parallel值為true,就可以開啟并發執行。在共享叢集中,需要注意下,如果job中并行階段增多,那麼叢集使用率就會增加。
set hive.exec.parallel=true; //打開任務并行執行
set hive.exec.parallel.thread.number=16; //同一個sql允許最大并行度,預設為8。
當然得是在系統資源比較空閑的時候才有優勢,否則沒資源,并行也起不來。
5. JVM優化
JVM重用是Hadoop調優參數的内容,其對Hive的性能具有非常大的影響,特别是對于很難避免小檔案的場景或task特别多的場景,這類場景大多數執行時間都很短。
Hadoop的預設配置通常是使用派生JVM來執行map和Reduce任務的。這時JVM的啟動過程可能會造成相當大的開銷,尤其是執行的job包含有成百上千task任務的情況。JVM重用可以使得JVM執行個體在同一個job中重新使用N次。N的值可以在Hadoop的
mapred-site.xml
檔案中進行配置。通常在10-20之間,具體多少需要根據具體業務場景測試得出。
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value>
<description>How many tasks to run per jvm. If set to -1, there is
no limit.
</description>
</property>
我們也可以在hive中設定
set mapred.job.reuse.jvm.num.tasks=10; //這個設定來設定我們的jvm重用
這個功能的缺點是,開啟JVM重用将一直占用使用到的task插槽,以便進行重用,直到任務完成後才能釋放。如果某個“不平衡的”job中有某幾個reduce task執行的時間要比其他Reduce task消耗的時間多的多的話,那麼保留的插槽就會一直空閑着卻無法被其他的job使用,直到所有的task都結束了才會釋放。
6. 推測執行優化
在分布式叢集環境下,因為程式Bug(包括Hadoop本身的bug),負載不均衡或者資源分布不均等原因,會造成同一個作業的多個任務之間運作速度不一緻,有些任務的運作速度可能明顯慢于其他任務(比如一個作業的某個任務進度隻有50%,而其他所有任務已經運作完畢),則這些任務會拖慢作業的整體執行進度。為了避免這種情況發生,Hadoop采用了推測執行(Speculative Execution)機制,它根據一定的法則推測出“拖後腿”的任務,并為這樣的任務啟動一個備份任務,讓該任務與原始任務同時處理同一份資料,并最終選用最先成功運作完成任務的計算結果作為最終結果。
設定開啟推測執行參數:Hadoop的
mapred-site.xml
檔案中進行配置:
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks
may be executed in parallel.</description>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks
may be executed in parallel.</description>
</property>
hive本身也提供了配置項來控制reduce-side的推測執行:
set hive.mapred.reduce.tasks.speculative.execution=true
關于調優這些推測執行變量,還很難給一個具體的建議。如果使用者對于運作時的偏差非常敏感的話,那麼可以将這些功能關閉掉。如果使用者因為輸入資料量很大而需要執行長時間的map或者Reduce task的話,那麼啟動推測執行造成的浪費是非常巨大大。
公衆号【五分鐘學大資料】,大資料領域原創技術号
最後
代碼優化原則:
- 理透需求原則,這是優化的根本;
- 把握資料全鍊路原則,這是優化的脈絡;
- 堅持代碼的簡潔原則,這讓優化更加簡單;
- 沒有瓶頸時談論優化,這是自尋煩惱。
本文來自微信公衆号:五分鐘學大資料,轉載請在公衆号背景擷取作者微信進行授權
![jdk1.7+Eclipse+Maven3.5+Hadoop2.7.3建構hadoop項目[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)