大家好,歡迎回到性能調優教育訓練。在上2個星期,你已經學過了統計資訊,它們為什麼重要,還有在SQL Server裡它們是什麼樣的。在這期性能調優教育訓練裡我想談下目前基數預估含有的局限性,還有如何應用不同新技術來克服這些局限。
基數預估錯誤
上個星期你就看到,當執行計劃被編譯時,SQL Server使用直方圖和密度向量來作基數預估。SQL Server這裡使用的模型是個靜态的,它有很多的缺點和陷阱。在SQL Server 2014裡這些情況會改變——下個星期我會詳細講解這些提升。
為了給你基數預估哪裡有問題的具體例子,假設有下列2個表:Orders表和Country表。Orders表裡的每條記錄代表客戶下的訂單(像資料倉庫情景裡的事實表),那個表裡通過外鍵限制指向Country表(它就像緯度表)。現在我們對這2個表進行一個來自UK的銷售查詢:
1 SELECT SalesAmount FROM Country
2 INNER JOIN Orders ON Country.ID = Orders.ID
3 WHERE Name = 'UK' 當你檢視它的執行計劃時,會發現SQL Server在基數預估上有個大問題。
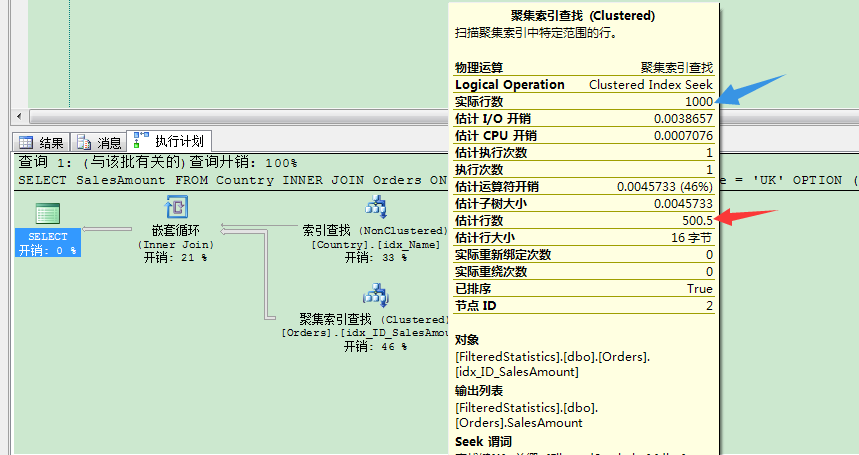
SQL Server估計行數是501,實際上聚集索引查找運算符的實際行數是1000。SQL Server這裡使用idx_ID_SalesAmount統計資訊對象的密度向量來做出那個預估:密度向量是0.5(在那列我們隻有2個不同值),是以估計行數是501(1001 * 0.5)。你可以通過增加過濾統計資訊對象來解決這個問題。這會給SQL Server更多關于資料分布本身的資訊,也會幫助基數預估。
1 CREATE STATISTICS Country_UK ON Country(ID)
2 WHERE Name = 'UK' 當你現在再次看執行計劃時,你會看到現在的估計行數和實際行數是一樣了。關于這個問題的更多資訊可以檢視這個文章:使用過濾統計資訊解決基數預估錯誤。
相關列(Correlated Columns)
在SQL Server裡對于目前的基數預估的另外一個問題出現在查詢謂語是彼此相關的。來看下面的SQL查詢:
1 SELECT * FROM Products
2 WHERE Company = 'Microsoft'
3 AND Product = 'iPhone' 當我們常人來看這個查詢時,你馬上知道會有多少行傳回:0!微軟公司不可能賣蘋果手機滴。當你對SQL Server執行這樣的查詢時,查詢優化器會獨立看每個查詢謂語:
在第1步裡,基數預估對謂語Company = 'Microsoft'完成。
在第2步裡,查詢優化器生成對另外謂語Product = 'iPhone'的基數預估。
最後2個預估相乘(multiplied by each other)生成最後的預估。當第1個謂語生成0.3的參數,第2個生成0.4的參數,最後的參數就是0.12(0.3 * 0.4)。查詢優化器對每個謂語各自處理,而不考慮彼此關聯。
對于這個特定問題,Paul White寫了一篇非常有趣的文章,還有你如何影響SQL Server的查詢優化器來生成更好性能的執行計劃。
小結
對于SQL Server裡執行計劃的準确性和高性能,統計資訊和基數預估非常重要。遺憾的是它們的使用率也是有限的,尤其在一些邊緣情況。通過這篇文章你看到你如何使用過濾統計資訊幫助查詢優化器生成更好的基數預估,還有如何處理SQL Server裡的相關列問題。
在下星期的性能調優教育訓練裡,我們會進一步讨論新基數預估,它是SQL Server 2014的一部分,還有在哪個情形下,新的實作方法會給你更好的執行計劃。請繼續關注。
圍觀PPT:
0831_15_基數預估問題.rar
注:此文章為
WoodyTu學習MS SQL技術,收集整理相關文檔撰寫,歡迎轉載,請在文章頁面明顯位置給出此文連結!
若您覺得這篇文章還不錯請點選下右下角的推薦,有了您的支援才能激發作者更大的寫作熱情,非常感謝!
![PostgreSQL開源圖書《PostgreSQL14技術内幕》(PostgreSQL14Internals)本書适合那[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)