1. 概述
本文主要分享 JDBC 與 讀寫分離 的實作。為什麼會把這兩個東西放在一起講呢?用戶端直連資料庫的讀寫分離主要通過擷取讀庫和寫庫的不同連接配接來實作,和 JDBC Connection 剛好放在一塊。
OK,我們先來看一段 Sharding-JDBC 官方對自己的定義和定位
Sharding-JDBC定位為輕量級java架構,使用用戶端直連資料庫,以jar包形式提供服務,未使用中間層,無需額外部署,無其他依賴,DBA也無需改變原有的運維方式,可了解為增強版的JDBC驅動,舊代碼遷移成本幾乎為零。
可以看出,Sharding-JDBC 通過實作 JDBC規範,對上層提供透明化資料庫分庫分表的通路。
黑科技?實際我們使用的資料庫連接配接池也是通過這種方式實作對上層無感覺的提供連接配接池。甚至還可以通過這種方式實作對 Lucene、MongoDB 等等的通路。
扯遠了,下面來看看 Sharding-JDBC
jdbc
包的結構:
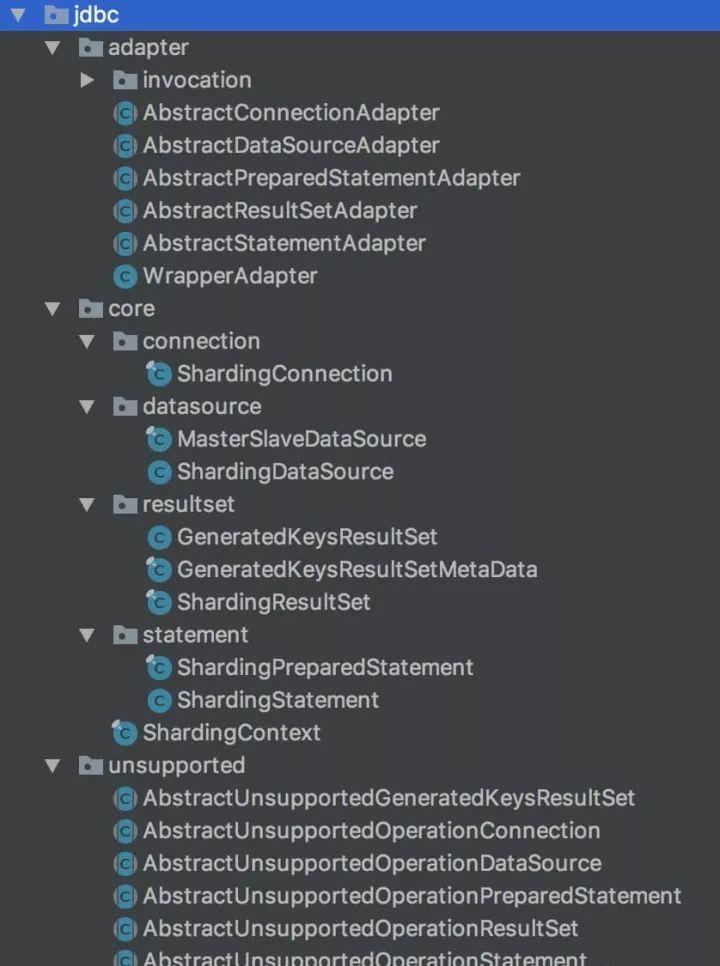
-
unsupported
-
adapter
-
core
根據
core
包,可以看出分到四種我們超級熟悉的對象
- Datasource

資料庫中間件 Sharding-JDBC 源碼分析 —— JDBC實作與讀寫分離 - Connection
資料庫中間件 Sharding-JDBC 源碼分析 —— JDBC實作與讀寫分離 - Statement
資料庫中間件 Sharding-JDBC 源碼分析 —— JDBC實作與讀寫分離 - ResultSet
資料庫中間件 Sharding-JDBC 源碼分析 —— JDBC實作與讀寫分離
實作層級如下:JDBC 接口 <=(繼承)==
unsupported
抽象類 <=(繼承)==
unsupported
core
類。
本文内容順序
-
unspported
-
adapter
- 插入流程,分析的類:
- ShardingDataSource
- ShardingConnection
- ShardingPreparedStatement(ShardingStatement 類似,不重複分析)
- GeneratedKeysResultSet、GeneratedKeysResultSetMetaData
查詢流程,分析的類:
- ShardingPreparedStatement
- ShardingResultSet