復原是指當程式或資料出錯時,将程式或資料恢複到最近一個正确版本的行為。最常見的如事務復原、代碼庫復原、部署版本復原、資料版本復原、靜态資源版本復原等。通過復原機制保證系統某些場景下的高可用。
事務復原
在執行資料庫SQL時,如果我們檢測到事務送出沖突,那麼事務中的所有已執行的SQL要進行復原,目的是防止資料庫出現資料不一緻。對于單庫事務復原直接使用相關SQL即可。如果涉及到分布式資料庫,則要考慮使用分布式事務,最常見的如兩階段送出、三階段送出協定,這種方式實作事務難度較低,但是,對性能影響比較大,因為我們大多數場景需要的是最終一緻性,而不是強一緻性。是以,可以考慮如事務表、消息隊列、補償機制(執行/復原)、TCC模式(預占/确認/取消)、Sagas模式(拆分事務+補償機制)等實作最終一緻性。比如,電商下單場景,會進行扣減優惠券、預占庫存等操作,這涉及到非常多的子系統,是以,很難使用分布式事務保證強一緻性,我們隻要能保證最終一緻性即可,來看下結算下單序列圖。
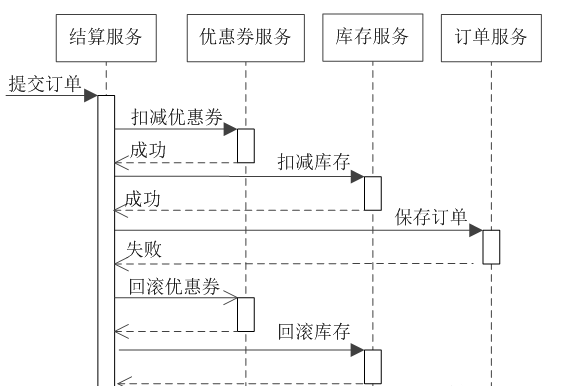
一種情況是當訂單出錯後,要把之前扣減的優惠券和庫存復原。但是,當儲存訂單出錯時,JVM執行個體挂掉了,那麼之前扣減的優惠券和庫存就沒有復原,這種情況可以考慮在本地記錄事務日志,當JVM執行個體重新開機後,分析事務日志重新復原,當然也可以記錄事務日志表,或者通過補償機制,定期掃描優惠券和庫存使用表,復原沒有關聯訂單的或者已取消訂單的記錄。還有一種情況是下單後一直沒有支付,比如6小時,沒有支付訂單要取消訂單,此時就要定期掃描訂單表,然後取消訂單并復原優惠券和庫存。不管用什麼方式,隻要保證最終一緻性即可。
代碼庫復原
在開發項目時,一定要将代碼維護到代碼倉庫,進而能進行版本管理。常見的有SVN、GIT等,SVN是一款集中版本控制系統,而GIT是一款分布式版本控制系統。有了版本控制系統後就可以記錄代碼的曆史版本,進而出問題後可以友善復原。當某個代碼檔案部署出現問題時,可以通過曆史版本檢視是誰修改的、修改了什麼,進而快速定位出BUG。另外,在實際開發過程中,可能存在多個版本并行開發,此時版本控制系統的分支功能就發揮大作用了,大家在各自分支上開發測試,互相不影響,開發完成後合并分支到主幹即可。
部署版本復原
代碼測試完成後,接下來就要進行系統的部署,在部署系統時,要考慮當代碼邏輯出現錯誤後如何快速恢複,總結為部署版本化,小版本增量釋出,大版本灰階釋出,架構更新并發釋出。
1.部署版本化
每次部署時,應該将上一版本的包記錄到部署系統中,在釋出時應該采用全量釋出,避免增量釋出(隻釋出修改過的類或檔案),全量版本後復原直接復原即可,不會受到一些限制或限制。
2.小版本增量發
比如修複BUG,添加一些簡單的業務邏輯,這些我們叫做小版本。增量發的意思是比如我們有100台伺服器,先發1台驗證,如果沒問題,則接着發10台,最後全量發。
3.大版本灰階發
比如頁面改版,添加新的功能此時需要灰階釋出,一般情況下是兩個版本并行跑一段時間,一些使用者通路老版本,一些使用者通路新版本,功能驗證成功後或者新版效果不錯再全量釋出。比如,我們可以通過類似于如下URL中帶有版本号來區分新版還是老版。
https://cd.jd.com/yanbao/v3?skuId=854073&cat=652,654,832&brandId=8983&area=1_2810_51081_0&callback=yanbao_jsonp_callback
不同版本其實就是不同的服務,在一套叢集部署即可,出問題時要能非常快速地切換回老版本。
4.架構更新并發釋出
架構更新後,我們不太清楚新版本是否功能正常,是以,新老版部署叢集會同時存在一段時間。然後,等所有流量遷移到新版本叢集後,老版本叢集就可以下線了。

一般前端應用我們會采用Nginx作為接入層,通過AB方式慢慢将流量引入到新版本叢集,比如1%、10%、50%、100%。如果新版本叢集處理出現問題,那麼要自動降級到老版本叢集繼續服務,當新版本出現大面積故障,要将所有流量引入到老版本叢集。是以,接入層要能靈活控制流量方向。
失敗降級我們可以借助Nginx的error_page。
proxy_intercept_errors on;
recursive_error_pages on;
location ~* "^/(d+).html$" {
proxy_pass http://new_version/$1.html;
error_page 500 502 503 504 =200 /fallback_version/$1.html;
}
失敗降級是很重要的特性,關鍵時候不至于使用者不能通路或者看到白屏,如果有CDN時,則切換版本時一定記得去掉CDN。
資料版本復原
有些特定行業業務資料中的商品/價格資料需要進行版本化處理,一方面為了審計需要,另一方面為了出現問題時能及時復原。版本化設計時可以基于下圖架構。
版本化資料結構設計時,有兩種思路:全量和增量。全量版本化是指即使隻變更了其中一個字段也将整體記錄進行曆史版本化,保持的資料量比較多,但是復原友善。而增量是指隻儲存變化的字段,儲存的資料量較少,但是復原起來很麻煩,需要回溯。是以,為了簡單化處理一般采用全量版本化機制。
另外,在設計消息隊列時,重要業務會對消息進行副本處理,以便萬一業務邏輯出現問題能進行曆史資料回放,進而修複問題。
靜态資源版本復原
在前端開發時,靜态資源版本也是會經常變更的,如JS/CSS,而每次内容變更時我們都會生成一個全量新版本放到項目的deploy目錄中,進而能保證版本可追溯,出現問題時能及時復原。
因為靜态資源一般放在CDN上緩存時間設定的比較長,比如1個月。這樣假設釋出的版本有問題,需要清理CDN緩存,并且也需要清理浏覽器緩存,而且因為存在版本覆寫的問題,即使覆寫了也不一定保證是操作正确了。
● 釋出新的靜态資源到源伺服器。
● 清理CDN緩存,進而可以回源取到最新的靜态資源。
● 在新的URL上添加随機數清理浏覽器緩存,如
< type="text/java"src="/js/index.js?time=201610231111"></ >。
而全量版本機制是最可靠的方式,我們先部署全量版本,然後通過如下方式引用。
------------------越是喧嚣的世界,越需要甯靜的思考------------------
合抱之木,生于毫末;九層之台,起于壘土;千裡之行,始于足下。
積土成山,風雨興焉;積水成淵,蛟龍生焉;積善成德,而神明自得,聖心備焉。故不積跬步,無以至千裡;不積小流,無以成江海。骐骥一躍,不能十步;驽馬十駕,功在不舍。锲而舍之,朽木不折;锲而不舍,金石可镂。蚓無爪牙之利,筋骨之強,上食埃土,下飲黃泉,用心一也。蟹六跪而二螯,非蛇鳝之穴無可寄托者,用心躁也。