版權說明: 本文章版權歸本人及部落格園共同所有,轉載請标明原文出處( https://www.cnblogs.com/mikevictor07/p/10006553.html ),以下内容為個人了解,僅供參考。
一、前言
資料平台已疊代三個版本,從頭開始遇到很多常見的難題,終于有片段時間整理一些已完善的文檔,在此分享以供所需朋友的
實作參考,少走些彎路,在此篇幅中偏重于ES的優化,關于HBase,Hadoop的設計優化估計有很多文章可以參考,不再贅述。
二、需求說明
項目背景:
在一業務系統中,部分表每天的資料量過億,已按天分表,但業務上受限于按天查詢,并且DB中隻能保留3個月的資料(硬體高配),分庫代價較高。
改進版本目标:
1. 資料能跨月查詢,并且支援1年以上的曆史資料查詢與導出。
2. 按條件的資料查詢秒級傳回。
三、elasticsearch檢索原理
3.1 關于ES和Lucene基礎結構
談到優化必須能了解元件的基本原理,才容易找到瓶頸所在,以免走多種彎路,先從ES的基礎結構說起(如下圖):
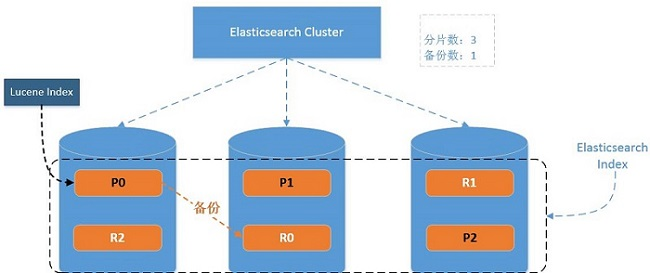
一些基本概念:
Cluster 包含多個Node的叢集
Node 叢集服務單元
Index 一個ES索引包含一個或多個實體分片,它隻是這些分片的邏輯命名空間
Type 一個index的不同分類,6.x後隻能配置一個type,以後将移除
Document 最基礎的可被索引的資料單元,如一個JSON串
Shards 一個分片是一個底層的工作單元,它僅儲存全部資料中的一部分,它是一個Lucence執行個體 (一個lucene索引最大包含2,147,483,519 (= Integer.MAX_VALUE - 128)個文檔數量)
Replicas 分片備份,用于保障資料安全與分擔檢索壓力
ES依賴一個重要的元件Lucene,關于資料結構的優化通常來說是對Lucene的優化,它是叢集的一個存儲于檢索工作單元,結構如下圖:

在Lucene中,分為索引(錄入)與檢索(查詢)兩部分,索引部分包含 分詞器、過濾器、字元映射器 等,檢索部分包含 查詢解析器 等。
一個Lucene索引包含多個segments,一個segment包含多個文檔,每個文檔包含多個字段,每個字段經過分詞後形成一個或多個term。
通過Luke工具檢視ES的lucene檔案如下,主要增加了_id和_source字段:
3.2 Lucene索引實作
Lucene 索引檔案結構主要的分為:詞典、倒排表、正向檔案、DocValues等,如下圖:
注:整理來源于lucene官方: http://lucene.apache.org/core/7_2_1/core/org/apache/lucene/codecs/lucene70/package-summary.html#package.description
Lucene 随機三次磁盤讀取比較耗時。其中.fdt檔案儲存資料值損耗空間大,.tim和.doc則需要SSD存儲提高随機讀寫性能。
另外一個比較消耗性能的是打分流程,不需要則可屏蔽。
關于DocValues:
反向索引解決從詞快速檢索到相應文檔ID, 但如果需要對結果進行排序、分組、聚合等操作的時候則需要根據文檔ID快速找到對應的值。
通過反向索引代價缺很高:需疊代索引裡的每個詞項并收集文檔的列裡面 token。這很慢而且難以擴充:随着詞項和文檔的數量增加,執行時間也會增加。Solr docs對此的解釋如下:
For other features that we now commonly associate with search, such as sorting, faceting, and highlighting, this approach is not very efficient. The faceting engine, for example, must look up each term that appears in each document that will make up the result set and pull the document IDs in order to build the facet list. In Solr, this is maintained in memory, and can be slow to load (depending on the number of documents, terms, etc.)
在lucene 4.0版本前通過FieldCache,原理是通過按列逆轉倒排表将(field value ->doc)映射變成(doc -> field value)映射,問題為逐漸建構時間長并且消耗大量記憶體,容易造成OOM。
DocValues是一種列存儲結構,能快速通過文檔ID找到相關需要排序的字段。在ES中,預設開啟所有(除了标記需analyzed的字元串字段)字段的doc values,如果不需要對此字段做任何排序等工作,則可關閉以減少資源消耗。
3.3 關于ES索引與檢索分片
ES中一個索引由一個或多個lucene索引構成,一個lucene索引由一個或多個segment構成,其中segment是最小的檢索域。
資料具體被存儲到哪個分片上: shard = hash(routing) % number_of_primary_shards
預設情況下 routing參數是文檔ID (murmurhash3),可通過 URL中的 _routing 參數指定資料分布在同一個分片中,index和search的時候都需要一緻才能找到資料,如果能明确根據_routing進行資料分區,則可減少分片的檢索工作,以提高性能。
四、優化案例
在我們的案例中,查詢字段都是固定的,不提供全文檢索功能,這也是幾十億資料能秒級傳回的一個大前提:
1、ES僅提供字段的檢索,僅存儲HBase的Rowkey不存儲實際資料。
2、實際資料存儲在HBase中,通過Rowkey查詢,如下圖。
3、提高索引與檢索的性能建議,可參考官方文檔(如 https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html)。
一些細節優化項官方與其他的一些文章都有描述,在此文章中僅提出一些本案例的重點優化項。
4.1 優化索引性能
1、批量寫入,看每條資料量的大小,一般都是幾百到幾千。
2、多線程寫入,寫入線程數一般和機器數相當,可以配多種情況,在測試環境通過Kibana觀察性能曲線。
3、增加segments的重新整理時間,通過上面的原理知道,segment作為一個最小的檢索單元,比如segment有50個,目的需要查10條資料,但需要從50個segment
分别查詢10條,共500條記錄,再進行排序或者分數比較後,截取最前面的10條,丢棄490條。在我們的案例中将此 "refresh_interval": "-1" ,程式批量寫入完成後
進行手工重新整理(調用相應的API即可)。
4、記憶體配置設定方面,很多文章已經提到,給系統50%的記憶體給Lucene做檔案緩存,它任務很繁重,是以ES節點的記憶體需要比較多(比如每個節點能配置64G以上最好)。
5、磁盤方面配置SSD,機械盤做陣列RAID5 RAID10雖然看上去很快,但是随機IO還是SSD好。
6、 使用自動生成的ID,在我們的案例中使用自定義的KEY,也就是與HBase的ROW KEY,是為了能根據rowkey删除和更新資料,性能下降不是很明顯。
7、關于段合并,合并在背景定期執行,比較大的segment需要很長時間才能完成,為了減少對其他操作的影響(如檢索),elasticsearch進行門檻值限制,預設是20MB/s,
可配置的參數:"indices.store.throttle.max_bytes_per_sec" : "200mb" (根據磁盤性能調整)
合并線程數預設是:Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)),如果是機械磁盤,可以考慮設定為1:index.merge.scheduler.max_thread_count: 1,
在我們的案例中使用SSD,配置了6個合并線程。
4.2 優化檢索性能
1、關閉不需要字段的doc values。
2、盡量使用keyword替代一些long或者int之類,term查詢總比range查詢好 (參考lucene說明 http://lucene.apache.org/core/7_4_0/core/org/apache/lucene/index/PointValues.html)。
3、關閉不需要查詢字段的_source功能,不将此存儲僅ES中,以節省磁盤空間。
4、評分消耗資源,如果不需要可使用filter過濾來達到關閉評分功能,score則為0,如果使用constantScoreQuery則score為1。
5、關于分頁:
(1)from + size:
每分片檢索結果數最大為 from + size,假設from = 20, size = 20,則每個分片需要擷取20 * 20 = 400條資料,多個分片的結果在協調節點合并(假設請求的配置設定數為5,則結果數最大為 400*5 = 2000條) 再在記憶體中排序後然後20條給使用者。這種機制導緻越往後分頁擷取的代價越高,達到50000條将面臨沉重的代價,預設from + size預設如下:
index.max_result_window : 10000
(2) search_after: 使用前一個分頁記錄的最後一條來檢索下一個分頁記錄,在我們的案例中,首先使用from+size,檢索出結果後再使用search_after,在頁面上我們限制了使用者隻能跳5頁,不能跳到最後一頁。
(3) scroll 用于大結果集查詢,缺陷是需要維護scroll_id
6、關于排序:我們增加一個long字段,它用于存儲時間和ID的組合(通過移位即可),正排與倒排性能相差不明顯。
7、關于CPU消耗,檢索時如果需要做排序則需要字段對比,消耗CPU比較大,如果有可能盡量配置設定16cores以上的CPU,具體看業務壓力。
8、關于合并被标記删除的記錄,我們設定為0表示在合并的時候一定删除被标記的記錄,預設應該是大于10%才删除: "merge.policy.expunge_deletes_allowed": "0"。
{
"mappings": {
"data": {
"dynamic": "false",
"_source": {
"includes": ["XXX"] -- 僅将查詢結果所需的資料存儲僅_source中
},
"properties": {
"state": {
"type": "keyword", -- 雖然state為int值,但如果不需要做範圍查詢,盡量使用keyword,因為int需要比keyword增加額外的消耗。
"doc_values": false -- 關閉不需要字段的doc values功能,僅對需要排序,彙聚功能的字段開啟。
},
"b": {
"type": "long" -- 使用了範圍查詢字段,則需要用long或者int之類 (建構類似KD-trees結構)
}
}
}
},
"settings": {......}
} 五、性能測試
優化效果評估基于基準測試,如果沒有基準測試無法了解是否有性能提升,在這所有的變動前做一次測試會比較好。在我們的案例中:
1、單節點5千萬到一億的資料量測試,檢查單點承受能力。
2、叢集測試1億-30億的數量,磁盤IO/記憶體/CPU/網絡IO消耗如何。
3、随機不同組合條件的檢索,在各個資料量情況下表現如何。
4、另外SSD與機械盤在測試中性能差距如何。
性能的測試組合有很多,通常也很花時間,不過作為評測标準時間上的投入有必要,否則生産出現性能問題很難定位或不好改善。對于ES的性能研究花了不少時間,最多的關注點就是lucene的優化,能深入了解lucene原理對優化有很大的幫助。
六、生産效果
目前平台穩定運作,幾十億的資料查詢100條都在3秒内傳回,前後翻頁很快,如果後續有性能瓶頸,可通過擴充節點分擔資料壓力。
原文位址:https://www.cnblogs.com/mikevictor07/p/10006553.html