概述
在單機時代,雖然不需要分布式鎖,但也面臨過類似的問題,隻不過在單機的情況下,如果有多個線程要同時通路某個共享資源的時候,我們可以采用線程間加鎖的機制,即當某個線程擷取到這個資源後,就立即對這個資源進行加鎖,當使用完資源之後,再解鎖,其它線程就可以接着使用了。例如,在JAVA中,甚至專門提供了一些處理鎖機制的一些API(synchronize/Lock等)。
但是到了分布式系統的時代,這種線程之間的鎖機制,就沒作用了,系統可能會有多份并且部署在不同的機器上,這些資源已經不是線上程之間共享了,而是屬于程序之間共享的資源。
是以,為了解決這個問題,我們就必須引入分布式鎖。分布式鎖是指在分布式的部署環境下,通過鎖機制來讓多用戶端互斥的對共享資源進行通路。
目前比較常見的分布式鎖實作方案有以下幾種:
- 基于資料庫,如MySQL
- 基于緩存,如Redis
- 基于Zookeeper、etcd等
我們在讨論使用分布式鎖的時候往往首先排除掉基于資料庫的方案,本能的會覺得這個方案不夠“進階”。從性能的角度考慮,基于資料庫的方案性能确實不夠優異,整體性能對比:緩存 > Zookeeper、etcd > 資料庫。也有人提出基于資料庫的方案問題很多,不太可靠。筆者認為采用哪種方案是要基于使用場景來看的,選擇哪種方案,合适最重要。
我這裡引用一下之前文章中的一個應用場景——配置設定任務場景。在這個場景中,由于是公司的業務背景系統,主要是用于稽核人員的稽核工作,并發量并不是很高,而且任務的配置設定規則設計成了通過稽核人員每次主動的請求拉取,然後服務端從任務池中随機的選取任務進行配置設定。這個場景看到這裡你會覺得比較單一,但是實際的配置設定過程中,由于涉及到了按使用者聚類的問題,是以要比我描述的複雜,但是這裡為了說明問題,大家可以把問題簡單化了解。那麼在使用過程中,主要是為了避免同一個任務同時被兩個稽核人員擷取到的問題。在這個場景下使用基于資料庫的方案就比較合理。
再補充一下,比如某一個服務它下遊依賴資料庫來做一些資料的讀寫操作,模型如下圖所示:
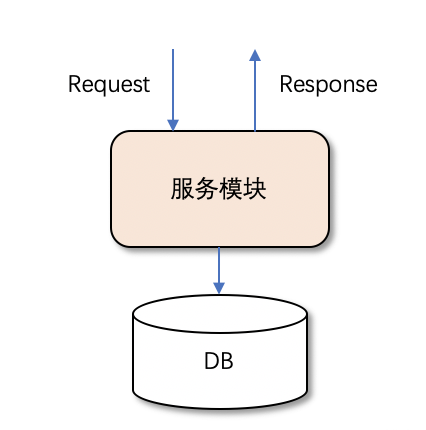
一般服務也是多執行個體部署,如果多個執行個體需要操作同一份資料的時候(比如前面所說的同一個任務同時被兩個稽核人員擷取到的問題),自然而然的引入了分布式鎖。不過此時,我們并沒有采用資料庫的方案,而是引入了Redis,模型如下圖所示:

引入Redis之後,正向的收益我就不贅述了,反向的收益是增加了系統的複雜度,對于整個服務而言,還需要多考慮1和2失效的情況。1失效是指服務子產品與Redis的互動出現了異常,這種異常不單是指無法通信的異常,也有可能是服務子產品發送請求隻Redis的過程中或者Redis響應服務子產品的過程中出現的異常,整體服務需要考慮這種情況:是重試、丢棄還是采取其他措施;2失效是指Redis本身出現了異常。資料鍊路一旦變長,系統複雜度一旦變大,在出現問題的時候會阻礙故障排查以及服務恢複,進而使得服務的整體可用性下調。
反觀,如果采用資料庫的方案,那麼就可以省去了這部分的複雜度,如果資料庫的方案能滿足當下場景以及可視範圍内的未來擴充,為什麼還要平白地增加系統複雜度呢?大家要根據具體業務場景選擇合适的技術方案,而不是随便找一個足夠複雜、足夠新潮的技術方案來解決業務問題。
下面我們來了解一下基于資料庫(MySQL)的方案,一般分為3類:基于表記錄、樂觀鎖和悲觀鎖。
基于表記錄
要實作分布式鎖,最簡單的方式可能就是直接建立一張鎖表,然後通過操作該表中的資料來實作了。當我們想要獲得鎖的時候,就可以在該表中增加一條記錄,想要釋放鎖的時候就删除這條記錄。
為了更好的示範,我們先建立一張資料庫表,參考如下:
CREATE TABLE `database_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '鎖定的資源',
`description` varchar(1024) NOT NULL DEFAULT "" COMMENT '描述',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='資料庫分布式鎖表';
當我們想要獲得鎖時,可以插入一條資料:
INSERT INTO database_lock(resource, description) VALUES (1, 'lock');
注意:在表database_lock中,resource字段做了唯一性限制,這樣如果有多個請求同時送出到資料庫的話,資料庫可以保證隻有一個操作可以成功(其它的會報錯:ERROR 1062 (23000): Duplicate entry ‘1’ for key ‘uiq_idx_resource’),那麼那麼我們就可以認為操作成功的那個請求獲得了鎖。
當需要釋放鎖的時,可以删除這條資料:
DELETE FROM database_lock WHERE resource=1;
這種實作方式非常的簡單,但是需要注意以下幾點:
- 這種鎖沒有失效時間,一旦釋放鎖的操作失敗就會導緻鎖記錄一直在資料庫中,其它線程無法獲得鎖。這個缺陷也很好解決,比如可以做一個定時任務去定時清理。
- 這種鎖的可靠性依賴于資料庫。建議設定備庫,避免單點,進一步提高可靠性。
- 這種鎖是非阻塞的,因為插入資料失敗之後會直接報錯,想要獲得鎖就需要再次操作。如果需要阻塞式的,可以弄個for循環、while循環之類的,直至INSERT成功再傳回。
- 這種鎖也是非可重入的,因為同一個線程在沒有釋放鎖之前無法再次獲得鎖,因為資料庫中已經存在同一份記錄了。想要實作可重入鎖,可以在資料庫中添加一些字段,比如獲得鎖的主機資訊、線程資訊等,那麼在再次獲得鎖的時候可以先查詢資料,如果目前的主機資訊和線程資訊等能被查到的話,可以直接把鎖配置設定給它。
樂觀鎖
顧名思義,系統認為資料的更新在大多數情況下是不會産生沖突的,隻在資料庫更新操作送出的時候才對資料作沖突檢測。如果檢測的結果出現了與預期資料不一緻的情況,則傳回失敗資訊。
樂觀鎖大多數是基于資料版本(version)的記錄機制實作的。何謂資料版本号?即為資料增加一個版本辨別,在基于資料庫表的版本解決方案中,一般是通過為資料庫表添加一個 “version”字段來實作讀取出資料時,将此版本号一同讀出,之後更新時,對此版本号加1。在更新過程中,會對版本号進行比較,如果是一緻的,沒有發生改變,則會成功執行本次操作;如果版本号不一緻,則會更新失敗。
為了更好的了解資料庫樂觀鎖在實際項目中的使用,這裡就列舉一個典型的電商庫存的例子。一個電商平台都會存在商品的庫存,當使用者進行購買的時候就會對庫存進行操作(庫存減1代表已經賣出了一件)。我們将這個庫存模型用下面的一張表optimistic_lock來表述,參考如下:
CREATE TABLE `optimistic_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '鎖定的資源',
`version` int NOT NULL COMMENT '版本資訊',
`created_at` datetime COMMENT '建立時間',
`updated_at` datetime COMMENT '更新時間',
`deleted_at` datetime COMMENT '删除時間',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='資料庫分布式鎖表';
其中:id表示主鍵;resource表示具體操作的資源,在這裡也就是特指庫存;version表示版本号。
在使用樂觀鎖之前要確定表中有相應的資料,比如:
INSERT INTO optimistic_lock(resource, version, created_at, updated_at) VALUES(20, 1, CURTIME(), CURTIME());
如果隻是一個線程進行操作,資料庫本身就能保證操作的正确性。主要步驟如下:
- STEP1 - 擷取資源:SELECT resource FROM optimistic_lock WHERE id = 1
- STEP2 - 執行業務邏輯
- STEP3 - 更新資源:UPDATE optimistic_lock SET resource = resource -1 WHERE id = 1
然而在并發的情況下就會産生一些意想不到的問題:比如兩個線程同時購買一件商品,在資料庫層面實際操作應該是庫存(resource)減2,但是由于是高并發的情況,第一個線程執行之後(執行了STEP1、STEP2但是還沒有完成STEP3),第二個線程在購買相同的商品(執行STEP1),此時查詢出的庫存并沒有完成減1的動作,那麼最終會導緻2個線程購買的商品卻出現庫存隻減1的情況。
在引入了version字段之後,那麼具體的操作就會演變成下面的内容:
- STEP1 - 擷取資源: SELECT resource, version FROM optimistic_lock WHERE id = 1
- STEP3 - 更新資源:UPDATE optimistic_lock SET resource = resource -1, version = version + 1 WHERE id = 1 AND version = oldVersion
其實,借助更新時間戳(updated_at)也可以實作樂觀鎖,和采用version字段的方式相似:更新操作執行前線擷取記錄目前的更新時間,在送出更新時,檢測目前更新時間是否與更新開始時擷取的更新時間戳相等。
樂觀鎖的優點比較明顯,由于在檢測資料沖突時并不依賴資料庫本身的鎖機制,不會影響請求的性能,當産生并發且并發量較小的時候隻有少部分請求會失敗。缺點是需要對表的設計增加額外的字段,增加了資料庫的備援,另外,當應用并發量高的時候,version值在頻繁變化,則會導緻大量請求失敗,影響系統的可用性。我們通過上述sql語句還可以看到,資料庫鎖都是作用于同一行資料記錄上,這就導緻一個明顯的缺點,在一些特殊場景,如大促、秒殺等活動開展的時候,大量的請求同時請求同一條記錄的行鎖,會對資料庫産生很大的寫壓力。是以綜合資料庫樂觀鎖的優缺點,樂觀鎖比較适合并發量不高,并且寫操作不頻繁的場景。
悲觀鎖
除了可以通過增删操作資料庫表中的記錄以外,我們還可以借助資料庫中自帶的鎖來實作分布式鎖。在查詢語句後面增加FOR UPDATE,資料庫會在查詢過程中給資料庫表增加悲觀鎖,也稱排他鎖。當某條記錄被加上悲觀鎖之後,其它線程也就無法再改行上增加悲觀鎖。
悲觀鎖,與樂觀鎖相反,總是假設最壞的情況,它認為資料的更新在大多數情況下是會産生沖突的。
在使用悲觀鎖的同時,我們需要注意一下鎖的級别。MySQL InnoDB引起在加鎖的時候,隻有明确地指定主鍵(或索引)的才會執行行鎖 (隻鎖住被選取的資料),否則MySQL 将會執行表鎖(将整個資料表單給鎖住)。
在使用悲觀鎖時,我們必須關閉MySQL資料庫的自動送出屬性(參考下面的示例),因為MySQL預設使用autocommit模式,也就是說,當你執行一個更新操作後,MySQL會立刻将結果進行送出。
mysql> SET AUTOCOMMIT = 0;
Query OK, 0 rows affected (0.00 sec)
這樣在使用FOR UPDATE獲得鎖之後可以執行相應的業務邏輯,執行完之後再使用COMMIT來釋放鎖。
我們不妨沿用前面的database_lock表來具體表述一下用法。假設有一線程A需要獲得鎖并執行相應的操作,那麼它的具體步驟如下:
- STEP1 - 擷取鎖:SELECT * FROM database_lock WHERE id = 1 FOR UPDATE;。
- STEP2 - 執行業務邏輯。
- STEP3 - 釋放鎖:COMMIT。
如果另一個線程B線上程A釋放鎖之前執行STEP1,那麼它會被阻塞,直至線程A釋放鎖之後才能繼續。注意,如果線程A長時間未釋放鎖,那麼線程B會報錯,參考如下(lock wait time可以通過innodb_lock_wait_timeout來進行配置):
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
上面的示例中示範了指定主鍵并且能查詢到資料的過程(觸發行鎖),如果查不到資料那麼也就無從“鎖”起了。
如果未指定主鍵(或者索引)且能查詢到資料,那麼就會觸發表鎖,比如STEP1改為執行(這裡的version隻是當做一個普通的字段來使用,與上面的樂觀鎖無關):
SELECT * FROM database_lock WHERE description='lock' FOR UPDATE;
或者主鍵不明确也會觸發表鎖,又比如STEP1改為執行:
SELECT * FROM database_lock WHERE id>0 FOR UPDATE;
注意,雖然我們可以顯示使用行級鎖(指定可查詢的主鍵或索引),但是MySQL會對查詢進行優化,即便在條件中使用了索引字段,但是否真的使用索引來檢索資料是由MySQL通過判斷不同執行計劃的代價來決定的,如果MySQL認為全表掃描效率更高,比如對一些很小的表,它有可能不會使用索引,在這種情況下InnoDB将使用表鎖,而不是行鎖。
在悲觀鎖中,每一次行資料的通路都是獨占的,隻有當正在通路該行資料的請求事務送出以後,其他請求才能依次通路該資料,否則将阻塞等待鎖的擷取。悲觀鎖可以嚴格保證資料通路的安全。但是缺點也明顯,即每次請求都會額外産生加鎖的開銷且未擷取到鎖的請求将會阻塞等待鎖的擷取,在高并發環境下,容易造成大量請求阻塞,影響系統可用性。另外,悲觀鎖使用不當還可能産生死鎖的情況。