由于最近要做一些自然語言處理的分享,但是我又不是科班出身,是以隻能臨時抱佛腳的學習以下基本的原理。但是由于底子很薄,是以隻能憑借google和baidu有限的資料進行總結。這裡不會看到太複雜的公式,因為公式層面我也了解不了....就當做是從0學習自然語言處理的過程的記錄吧!
如果有哪裡說的不對的,還請嚴厲指正,小部落客一定虛心領教,仔細研究!以免誤導大衆...
下面就步入正題吧!
這個方向在幾個大廠應該都比較成熟了,比如有道翻譯、百度翻譯、Google翻譯等等。我平時用的有道比較多,一般都是去翻譯個英文文檔之類的。因為有道做的詞典比較專業,是以在英譯漢或者漢譯英的時候認可度能高點。
我們先來看看機器翻譯是怎麼被玩壞的吧!
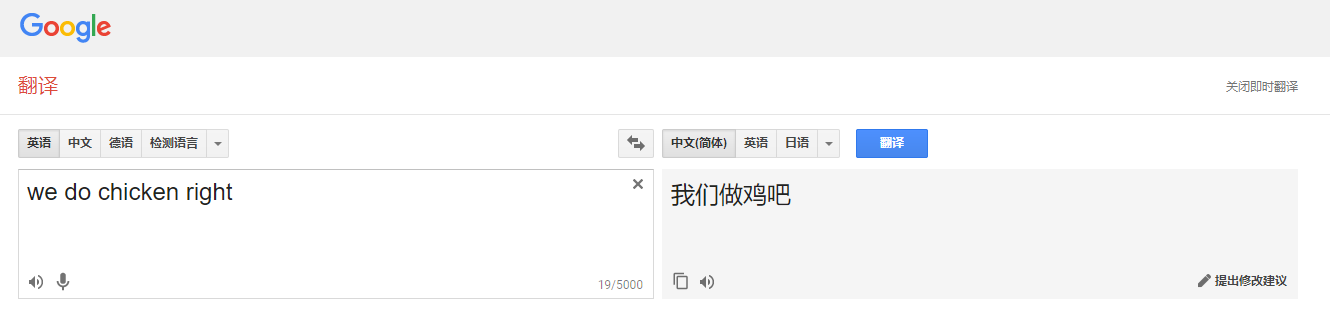

PS: 這個梗真的不是我黑誰!我也是從PPT上面看到的,覺得這個例子很不錯.....
話說回來,在機器翻譯的領域,有很多難點。比如,語言的複雜程度,上下文的關聯等等。想想看,同樣是漢語,山東大漢和陝西小哥以及東北姑娘說出來的都是不一樣的;再想想漢語中的博大精深,同樣一段話,上下文不同表達的含義也是不一樣的;再複雜點,涉及到兩種語言的切換,就更恐怖了。
目前業内主要的實作手段有基于規則的、基于執行個體的、基于統計的以及基于神經網絡的,看着感覺蒙蒙哒,我們來具體的了解下吧:
基于規則的機器翻譯
基于規則的機器翻譯,是最古老也是見效最快的一種翻譯方式。
根據翻譯的方式可以分為:
- 直接基于詞的翻譯
- 結構轉換的翻譯
- 中間語的翻譯
從字面上了解,基于詞的翻譯就是直接把詞進行翻譯,但是也不是這麼簡單,會通過一些詞性的變換、專業詞彙的變換、位置的調整等一些規則,進行修飾。
可以看到翻譯的品質很差,但是基于這種詞規則的翻譯,基本上可以輔助我們做一些翻譯的工作;而且這種翻譯也帶來了機器翻譯的0到1的飛躍
那麼基于結構轉換 其實就是不僅僅考慮單個詞,而是考慮到短語的級别。比如根據端與
do chicken
有可能被翻譯成
烹饪雞
,那麼整句話就好多了
我們烹饪雞好嗎
最後一種就是基于中間語的翻譯,比如過去在金本位的年代,各國都有自己的貨币。中國使用中國的貨币,美國使用美國的貨币,那麼貨币之間怎麼等價呢?就可以兌換成黃金來衡量價值。這樣就可以進行跨币種的買賣了..翻譯也是如此,倘若由兩種語言無法直譯,那麼也可以先翻譯成中間語,然後通過中間語進行兩種語言的翻譯。
基于統計的機器翻譯
基于統計的機器翻譯明顯要比基于規則的進階的多,因為引入了一些數學的方法,總體上顯得更加專業。那麼我們看看它是怎麼做的吧!
首先,我們有一段英文想要把它翻譯成漢語:
we do chicken right
會根據每個詞或者短語,羅列它可能出現的翻譯結果:
我們/做/雞/右
我們/做/雞/好嗎
我們/幹/雞/怎麼樣
...
這樣的結果有很多種...
然後我們需要一個大量的語料庫,即有大量的文章...這些文章會提供 每一種翻譯結果出現的機率,機率的計算方式可能是使用隐馬爾可夫模型,即自己算相鄰詞的機率,這個原理在《數學之美》中有介紹,感興趣的可以去看看。
最終挑選機率最高的翻譯結果作為最終的輸出。
總結來說大緻的流程是:
是以可以看到,這種翻譯方式依賴大量的語料庫,是以大多數使用這種方式而且效果比較好的都是那種搜尋引擎公司,比如Google和Baidu,他們依賴爬蟲技術有網際網路中大量的文本資料,基于這些文本資料可以擷取大量的語料來源,進而為自己的翻譯提供大量的依據資料。
基于執行個體的機器翻譯
這種翻譯也比較常見,通俗點說就是抽取句子的模式,當你輸入一句話想要翻譯的時候,會搜尋相類似的語句,然後替換不一樣的詞彙翻譯。舉個例子:
I gave zhangsan a pen
I gave lisi an apple
就可以抽取他們相似的部分,直接替換不一樣的地方的詞彙就行。這種翻譯其實效果不太好,而且太偏領域背景...
基于神經網絡的機器翻譯
在深度學習火起來後,這種方式越來越受關注。我們先來了解下什麼是神經網絡:
基本的意思就是我們會有很多的輸入,這些輸入經過一些中間處理,得到輸出。得到的輸出又可以作為下一個計算過程的輸入...這樣就組成了神經網絡。
在機器翻譯中主要使用的是循環神經網絡,即上一次的輸出可以作為這次的輸入繼續參與計算。這樣有什麼目的呢?
就是在翻譯的過程中,雖然是以句子為機關進行翻譯的,但是每一句話都會對下一句話的翻譯産生影響,這樣就做出了上下文的感覺....比如
do chicken
單純的翻譯有很多中翻譯的結果。但是如果前面出現過廚師等這類的詞句,那麼這個單詞就可以更傾向翻譯成
烹饪雞
。
這種操作模式,在問答系統中也會遇到...之後會有所介紹.
總結
總結的來說,如果想要快速搭建一個機器翻譯的系統,可以先從基于規則開始,添加一些領域背景的知識,就能達到一個比較快速的效果。而基于統計的方法從資料擷取的成本和模型的訓練來說,成本都很高...
針對機器翻譯是否能代替人工翻譯,知乎上面也有不少讨論,我這個門外漢也覺得,暫時不太可能,不過機器翻譯作為人工翻譯的一種輔助手段還是很必要的。比如那些非專業的翻譯人士,如寫論文的研究所學生、看前沿技術的程式員小朋友,這種機器翻譯可以作為一種很有效的閱讀輔助的手段,因為大部分的時候,都是直接把某一段英文粘貼到翻譯的輸入框,然後按照翻譯出來的結果,自己再組織了解...(我想大部分人都是這麼用的吧~ 原諒我英語差)
那麼機器翻譯的掃盲就暫時介紹到這裡了,之後會再研究下情感分析相關的内容...