SQL夯實基礎(五):索引的資料結構
資料量達到十萬級别以上的時候,索引的設定就顯得異常重要,而如何才能更好的建立索引,需要了解索引的結構等基礎知識。本文我們就來讨論索引的結構。
二叉搜尋樹:binary search tree
1.所有非葉子結點至多擁有兩個兒子(Left和Right);
2.所有結點存儲一個關鍵字;
3.非葉子結點的左指針指向小于其關鍵字的子樹,右指針指向大于其關鍵字的子樹;
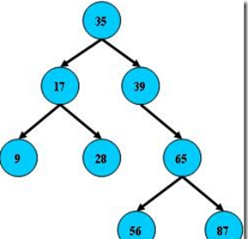
B樹的搜尋,從根結點開始,如果查詢的關鍵字與結點的關鍵字相等,那麼就命中;否則,如果查詢關鍵字比結點關鍵字小,就進入左兒子;如果比結點關鍵字大,就進入右兒子;如果左兒子或右兒子的指針為空,則報告找不到相應的關鍵字;
如果B樹的所有非葉子結點的左右子樹的結點數目均保持差不多(平衡),那麼B樹的搜尋性能逼近二分查找;但它比連續記憶體空間的二分查找的優點是,改變B樹結構(插入與删除結點)不需要移動大段的記憶體資料,甚至通常是常數開銷;

但B樹在經過多次插入與删除後,有可能導緻不同的結構:
右邊也是一個B樹,但它的搜尋性能已經是線性的了;同樣的關鍵字集合有可能導緻不同的樹結構索引;是以,使用B樹還要考慮盡可能讓B樹保持左圖的結構,和避免右圖的結構,也就是所謂的“平衡”問題;
實際使用的B樹都是在原B樹的基礎上加上平衡算法,即“平衡二叉樹”;如何保持B樹結點分布均勻的平衡算法是平衡二叉樹的關鍵;平衡算法是一種在B樹中插入和删除結點的政策;
B-樹
B-tree,即B樹,而不要讀成B減樹,它是一種多路搜尋樹(并不是二叉的):
1.定義任意非葉子結點最多隻有M個兒子;且M>2;
2.根結點的兒子數為[2, M];
3.除根結點以外的非葉子結點的兒子數為[M/2, M];
4.每個結點存放至少M/2-1(取上整)和至多M-1個關鍵字;(至少2個關鍵字)
5.非葉子結點的關鍵字個數=指向兒子的指針個數-1;
6.非葉子結點的關鍵字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非葉子結點的指針:P[1], P[2], …, P[M];其中P[1]指向關鍵字小于K[1]的子樹,P[M]指向關鍵字大于K[M-1]的子樹,其它P[i]指向關鍵字屬于(K[i-1], K[i])的子樹;
8.所有葉子結點位于同一層;
如:(M=3)
B-樹的搜尋,從根結點開始,對結點内的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢關鍵字所屬範圍的兒子結點;重複,直到所對應的兒子指針為空,或已經是葉子結點;
B-樹的特性:
1.關鍵字集合分布在整顆樹中;
2.任何一個關鍵字出現且隻出現在一個結點中;
3.搜尋有可能在非葉子結點結束;
4.其搜尋性能等價于在關鍵字全集内做一次二分查找;
5.自動層次控制;
由于限制了除根結點以外的非葉子結點,至少含有M/2個兒子,確定了結點的至少使用率,其最底搜尋性能為:
其中,M為設定的非葉子結點最多子樹個數,N為關鍵字總數;
是以B-樹的性能總是等價于二分查找(與M值無關),也就沒有B樹平衡的問題;
由于M/2的限制,在插入結點時,如果結點已滿,需要将結點分裂為兩個各占M/2的結點;删除結點時,需将兩個不足M/2的兄弟結點合并;
B+樹
B+樹是B-樹的變體,也是一種多路搜尋樹:
其定義基本與B-樹同,
除了:
1.非葉子結點的子樹指針與關鍵字個數相同;
2.非葉子結點的子樹指針P[i],指向關鍵字值屬于[K[i], K[i+1])的子樹(B-樹是開區間);(B+是閉區間,也就是包含區間的兩端值)
3.為所有葉子結點增加一個鍊指針;
4.所有關鍵字都在葉子結點出現;
B+的搜尋與B-樹也基本相同,差別是B+樹隻有達到葉子結點才命中(B-樹可以在非葉子結點命中),其性能也等價于在關鍵字全集做一次二分查找;
B+的特性:
1.所有關鍵字都出現在葉子結點的連結清單中(稠密索引),且連結清單中的關鍵字恰好是有序的;
2.不可能在非葉子結點命中;
3.非葉子結點相當于是葉子結點的索引(稀疏索引),葉子結點相當于是存儲(關鍵字)資料的資料層;
4.更适合檔案索引系統;
原因:相對于B樹,(1)B+樹空間使用率更高,因為B+樹的内部節點隻是作為索引使用,而不像B-樹那樣每個節點都需要存儲硬碟指針。
(2)增删檔案(節點)時,效率更高,因為B+樹的葉子節點包含所有關鍵字,并以有序的連結清單結構存儲,這樣可很好提高增删效率。
聚集索引和非聚集索引
聚集索引和非聚集索引都采用了B+樹的結構,但非聚集索引的葉子層并不與實際的資料頁相重疊,而采用葉子層包含一個指向表中的記錄在資料頁中的指針的方式。
聚集索引和非聚集索引的根本差別是表記錄的排列順序和與索引的排列順序是否一緻,聚集索引表記錄的排列順序與索引的排列順序一緻,優點是查詢速度快,因為一旦具有第一個索引值的紀錄被找到,具有連續索引值的記錄也一定實體的緊跟其後。
聚集索引的缺點是對表進行修改速度較慢,這是為了保持表中的記錄的實體順序與索引的順序一緻,而把記錄插入到資料頁的相應位置,必須在資料頁中進行資料重排,降低了執行速度。
非聚集索引指定了表中記錄的邏輯順序,但記錄的實體順序和索引的順序不一緻,聚集索引和非聚集索引都采用了B+樹的結構,但非聚集索引的葉子層并不與實際的資料頁相重疊,而采用葉子層包含一個指向表中的記錄在資料頁中的指針的方式。非聚集索引比聚集索引層次多,添加記錄不會引起資料順序的重組。
簡單的了解:聚集索引..就像我們新華字典中的按拼音排序..即你查.."愛"字..可以在前面看到"癌"字,而非聚集索引就是新華字典中的按部首筆劃排序。
聚集索引确定表中資料的實體順序。聚集索引類似于電話簿,後者按姓氏排列資料。由于聚集索引規定資料在表中的實體存儲順序,是以一個表隻能包含一個聚集索引。但該索引可以包含多個列(組合索引),就像電話簿按姓氏和名字進行組織一樣。
非聚集索引與課本中的索引類似。資料存儲在一個地方,索引存儲在另一個地方,索引帶有指針指向資料的存儲位置。索引中的項目按索引鍵值的順序存儲,而表中的資訊按另一種順序存儲(這可以由聚集索引規定)。
索引的建立原則
避免添加不必要的列。
每頁上能容納更多的行。
維護索引
由于索引是采用 B 樹結構存儲的,是以對應的索引項并不會被删除,經過一段時間的增删改操作後,資料庫中就會出現大量的存儲碎片,這和磁盤碎片、記憶體碎片産生原理是類似的,這些存儲碎片不僅占用了存儲空間,而且降低了資料庫運作的速度。如果發現索引中存在過多的存儲碎片的話就要進行“碎片整理”了,最友善的“碎片整理” 手段就是重建索引, 重建索引會将先前建立的索引删除然後重新建立索引,主流資料庫管理系統都提供了重建索引的功能,比如 REINDEX、REBUILD 等,如果使用的資料庫管理系統沒有提供重建索引的功能,可以首先用DROP INDEX語句删除索引,然後用ALTER TABLE 語句重新建立索引。