Hadoop的各個元件是通過XML配置的。
2.0以後,配置檔案的位置發生了小變化。我安裝的Hadoop 2.4.1,配置檔案的位置在$HADOOP_INSTALL/etc/hadoop/
在初期執行MapReduce DEMO時,我們僅僅需關注三個基本配置就好:
core-site.xml
hdfs-site.xml
yarn-site.xml(2.0後的版本号,MapReduce執行在yarn上)
Hadoop有三種執行模式:本地模式(Standalone or local mode)。僞分布式模式(Pseudodistributed mode)和分布式模式(Fully distributed mode)。
Standalone mode不須要配置。也不須要啟動Daemon程序,學習時能夠使用這個模式,Pseudodistributed mode和Fully distributed mode本質是一樣的,僅僅隻是Pseudodistributed mode是僅僅有一台機器的Fully distributed mode.
以下說一下Pseudodistributed mode怎樣配置:
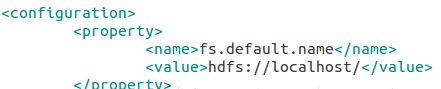
core-site.xml中配置:fs.default.name = hdfs://localhost/
hdfs-site.xml中配置:dfs.replication = 1

yarn-site.xml中配置:yarn.resourcemanager.address = localhost:8032, yarn.nodemanager.aux-services = mapreduce.shuffle
接下來,我們須要配置SSH。由于Pseudodistributed mode和Fully distributed mode沒有差别,僅僅隻是是僅僅有一個節點的分布式而已。而Hadoop通過SSH來啟動各個節點的Daemon,是以我們須要讓SSH可以不須要輸入password而登入目前localhost。詳細做法例如以下:
先安裝SSH,假設是在Ubuntu下,能夠使用指令:
安裝:sudo apt-get install openssh-server
服務:
sudo service ssh start/stop/restart/status
生成key
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将key存入~/.ssh/authorized_keys。這樣下次登入時就不須要輸入password了。
這時,我們輸入:ssh localhost,假設不須要輸入password,直接登入成功。就能夠了。
以下插一段,我用的是64位的Ubuntu,而hadoop官網提供的版本号是基于32位環境編譯的,必須下載下傳源代碼,在64位系統下又一次編譯才幹正确執行以下指令。編譯的方法我是參考這篇文章的:http://blog.csdn.net/tianfei_1984/article/details/20030383
事實上就是要編譯完之後生成的$HADOOP_INSTALL/lib/native/眼下下的那個動态庫。
接下來是format hdfs,就像使用一塊新硬碟一樣,要對其進行格式化。
運作指令:hadoop namenode -format
啟動daemon程序:
start-dfs.sh
start-yarn.sh
結束daemon程序:
stop-dfs.sh
stop-yarn.sh
這四個指令腳本位于$HADOOP_INSTALL/sbin/檔案夾下。由于之前我們配置環境變量時把這個檔案夾加到PATH下了。是以能夠直接執行。
有可能遇到JAVA_HOME找不到的問題,不了解原因。我配置JAVA_HOME環境變量。但還是找不到,不知道為什麼。最後在$HADOOP_INSTALL/etc/hadoop/下找到hadoop-env.sh腳本。打開看裡面有
export JAVA_HOME=${JAVA_HOME}
按理說這就應該能夠呀,可是把它凝視掉,改成JAVA_HOME的真實路徑
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_67
問題就攻克了。
用jps指令能夠确認hadoop daemon程序啟動是否成功。
jps是jdk提供的工具,類似于Linux裡的ps指令,檢視虛拟機程序。