動态規劃
動态規劃(Dynamic Programming,簡稱DP)是一種通過把原問題分解為相對簡單的子問題的方式求解複雜問題的方法。
動态規劃常常适用于具有如下性質的問題:
- 具有最優子結構(Optimal substructure)
- Principle of optimality applies
- Optimal solution can be decomposed into subproblems
- 重疊子問題(Overlapping subproblems)
- Subproblems recur many times
- Solutions can be cached and reused
動态規劃方法所耗時間往往遠少于樸素解法。
馬爾可夫決策過程MDP滿足上述兩個性質:
- 貝爾曼方程提供了遞歸分解的結構;
- 價值函數可以儲存和重複使用遞歸時的結果。
使用動态規劃解決MDP/MRP
動态規劃需要滿足MDP過程是已知的(model-based)。
- For Predict:
- Input:MDP \(<S, A, P, R, \gamma>\) 和政策 $\pi $ 或者是 MRP \(<S, P, R, \gamma>\)
- Output:價值函數 \(v_{\pi}\)
- For Control:
- Input:MDP \(<S, A, P, R, \gamma>\)
- Output:最優價值函數 \(v_{*}\) 或者最優政策 \(\pi_{*}\)
政策評估
政策評估(Policy Evaluation)指的是計算給定政策的價值,解決的問題是 "How to evaluate a policy"。
政策評估的思路:疊代使用貝爾曼期望方程(關于 MDP 的貝爾曼期望方程形式見《馬爾可夫決策過程》)。
政策評估過程如下圖所示:
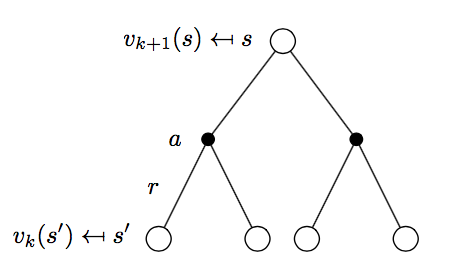
\[v_{k+1} = \sum_{a\in A}\pi(a|s) \Bigl( R_{s}^a + \gamma\sum_{s'\in S}P_{ss'}^a v_{k}(s') \Bigr)
\]
使用向量形式表示:
\[\mathbf{v^{k+1}} = \mathbf{R^{\pi}} + \gamma \mathbf{P^{\pi}v^{k}}
政策疊代
政策疊代(Policy Iteration,簡稱PI)解決的問題是 "How to improve a policy"。
給定一個政策 \(\pi\):
- 評估政策 \(\pi\):
\[v_{\pi}(s) = E[R_{t+1} + \gamma R_{t+2} + ...| S_t = s]
- 提升政策:通過采用貪婪方法來提升政策:
\[\pi ' = \text{greedy}(v_{\pi})
可以證明,政策疊代不斷進行總是能收斂到最優政策,即 \(\pi ' = \pi^{*}\)。
政策疊代可以使用下圖來形式化的描述:
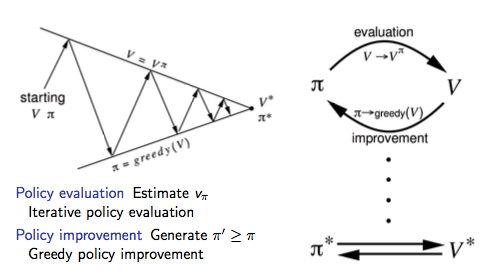
廣義政策疊代
通過上述提到的政策評估我們不難發現,政策評估是一個不斷疊代的過程:
那麼問題來了,Does policy evaluation need to converge to \(v_{\pi}\)?
我們是不是可以引入一個停止規則或者規定在疊代 \(k\) 次後停止政策評估?
再進一步想,我們為什麼不在每次政策評估的疊代過程中進行政策提升(等同于政策評估疊代1次後停止)?
注:這和後續要介紹的值疊代等價。
是以我們可以把上述政策疊代的過程一般化,即廣義政策疊代(Generalised Policy Iteration,簡稱GPI)架構:
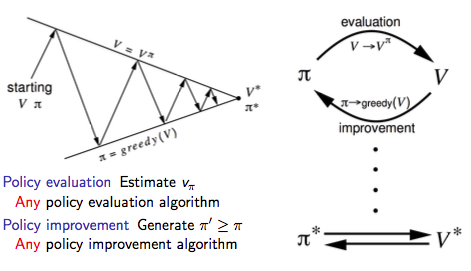
值疊代
介紹值疊代之前,我們先介紹下最優化原理。
最優化原理
最優化原理(Principle of Optimality)定義:
一個過程的最優決策具有這樣的性質:即無論其初始狀态和初始決策如何,其今後諸政策對以第一個決策所形成的狀态作為初始狀态的過程而言,必須構成最優政策。
最優化原理如果用數學化一點的語言來描述的話就是:
以狀态 \(s\) 為起始點,政策 \(\pi(a|s)\) 可以得到最優值 \(v_{\pi}(s) = v_*(s)\) 當且僅當:
- 任意狀态 \(s'\) 對于狀态 \(s\) 均可達;
- 以狀态 \(s'\) 為起始點,政策 \(\pi\) 可以得到最優值 \(v_{\pi}(s') = v_*(s')\)。
根據最優化原理可知,如果我們得到了子問題的解 $ v_*(s')$,那麼以狀态 \(s\) 為起始點的最優解 \(v_*(s)\) 可以通過一步回退(one-step lookahead)就能擷取:
\[v_*(s) ← \max_{a\in A}\Bigl(R_s^a + \gamma \sum_{s'\in S}P_{ss'}^{a}v_*(s') \Bigr)
也就是說,我們可以從最後開始向前回退進而得到最優解,值疊代就是基于上述思想進行疊代更新的。
MDP值疊代
值疊代(Value Iteration,簡稱VI)解決的問題也是 "Find optimal policy $\pi $"。
但是不同于政策疊代使用貝爾曼期望方程的是,值疊代使用貝爾曼最優方程進行疊代提升。
值疊代與政策疊代不同的地方在于:
- Use Bellman optimal function, rather than Bellman expectation function
- Unlike policy iteration, there is no explicit policy
- Intermediate value functions may not correspond to any policy
如下圖所示:
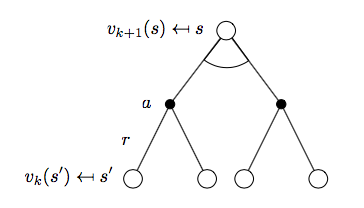
$$v_{k+1}(s) = \max_{a\in A}\Bigl(R_s^a + \gamma\sum_{s'\in S}P_{ss'}^a v_k(s') \Bigr)$$
對應的向量表示為:
\[\mathbf{v}_{k+1} = \max_{a\in A}\mathbf{R}^a + \gamma \mathbf{P^av}^k
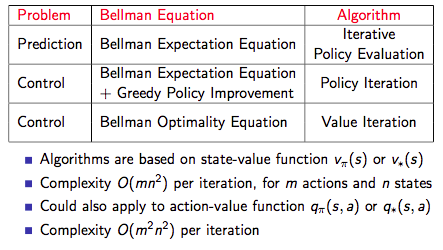
下圖為三種方法的總結:
動态規劃擴充
異步動态規劃(Asynchronous Dynamic Programming)
- In-place dynamic programming
- Prioritised sweeping
- Real-time dynamic programming
Full-Width Backups vs. Sample Backups
Full-Width Backups
- DP uses full-width backups(DP is model-based)
- Every successor state and action is considered
- Using knowledge of the MDP transitions and reward function
- DP is effective for medium-sized problems (millions of states)
- For large problems, DP suffers Bellman’s curse of dimensionality(次元災難)
次元災難:Number of states \(n = |S|\) grows exponentially with number of state variables
- Even one backup can be too expensive
Sample Backups
後續将要讨論的時序差分方法
- Using sample rewards and sample transitions \(⟨S, A, R, S′⟩\)
- Instead of reward function R and transition dynamics P
- Advantages:
- Model-free: no advance knowledge of MDP required
- Breaks the curse of dimensionality through sampling
- Cost of backup is constant, independent of \(n = |S|\)
Reference
[1] 智庫百科-最優化原理
[2] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[3] David Silver's Homepage
作者:Poll的筆記
部落格出處:http://www.cnblogs.com/maybe2030/
本文版權歸作者和部落格園所有,歡迎轉載,轉載請标明出處。
<如果你覺得本文還不錯,對你的學習帶來了些許幫助,請幫忙點選右下角的推薦>
![繩索資料結構(字元串快速拼接)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)