期中總結
第一周、linux常用指令回顧
man -k:
- 使用者可以通過執行 man 指令調用手冊頁。示例:
你可以使用如下方式來獲得某個指令的說明和使用方式的詳細介紹:
$ man
比如你想檢視 man 指令本身的使用方式,你可以輸入:
man man
要檢視相應區段的内容,就在 man 後面加上相應區段的數字即可,如:
$ man 3 printf
cheat:
cheat是非常好用的“打小抄”搜尋工具,能夠友善的告訴你你想要的内容。
grep -nr
grep指令是很強大的,也是相當常用的一個指令,它結合正規表達式可以實作很複雜卻很高效的比對和查找.
第二周、linux常用工具
vim:
1.vim編輯器的三種模式
* 正常模式:(按Esc或Ctrl+[進入) 左下角顯示檔案名或為空
* 插入模式:(按i鍵進入) 左下角顯示--INSERT--
* 可視模式:左下角顯示—VISUAL
2、vim的一些基本操作
Ⅰ、遊标移動:
在進入vim後,按下i鍵進入插入模式。在該模式下您可以輸入文本資訊,下面請輸入如下三行資訊:
12345678
abcdefghijk
shiyanlou.com
按Esc進入普通模式,在該模式下使用方向鍵或者h,j,k,l鍵可以移動遊标。
Ⅱ.插入模式
在普通模式下使用下面的鍵将進入插入模式,并可以從相應的位置開始輸入
指令
說明
i
在目前光标處進行編輯
I
在行首插入
A
在行末插入
a
在光标後插入編輯
o
在目前行後插入一個新行
O
在目前行前插入一個新行
cw
替換從光标所在位置後到一個單詞結尾的字元
請嘗試不同的從普通模式進入插入模式的方法,在最後一行shiyanlou前面加上www.,注意每次要先回到普通模式才能切換成以不同的方式進入插入模式
vim的按鍵圖
gcc:
使用GCC的四個步驟
- 預處理:gcc –E hello.c –o hello.i;gcc –E調用cpp
- 編 譯:gcc –S hello.i –o hello.s;gcc –S調用ccl
- 彙 編:gcc –c hello.s –o hello.o;gcc -c 調用as
- 鍊 接:gcc hello.o –o hello ;gcc -o 調用ld
gdb:
$gdb
這樣可以和gdb進行互動了。
- 啟動gdb,并且分屏顯示源代碼:
$gdb -tui
這樣,使用了'-tui'選項,啟動可以直接将螢幕分成兩個部分,上面顯示源代碼,比用list友善多了。這時候使用上下方向鍵可以檢視源代碼,想要指令行使用上下鍵就用[Ctrl]n和[Ctrl]p.
啟動程式之後,再用gdb調試:
$gdb
這裡,是程式的可執行檔案名,是要調試程式的PID.如果你的程式是一個服務程式,那麼你可以指定這個服務程式運作時的程序ID。gdb會自動attach上去,并調試他。program應該在PATH環境變量中搜尋得到。
*啟動程式之後,再啟動gdb調試:
這裡,程式是一個服務程式,那麼你可以指定這個服務程式運作時的程序ID,是要調試程式的PID.這樣gdb就附加到程式上了,但是現在還沒法檢視源代碼,用file指令指明可執行檔案就可以顯示源代碼了。
*重新運作調試的程式:
(gdb) run
要想運作準備調試的程式,可使用run指令,在它後面可以跟随發給該程式的任何參數,包括标準輸入和标準輸出說明符(<和> )和shell通配符(*、?、[、])在内。
Make和Makefile
這是實作自動化編譯的好方法。
Makefile的一般寫法:
一個Makefile檔案主要含有一系列的規則,每條規則包含以下内容:
需要由make工具建立的目标體,通常是可執行檔案和目标檔案,也可以是要執行的動作,如‘clean’;
要建立的目标體所依賴的檔案,通常是編譯目标檔案所需要的其他檔案。
建立每個目标體時需要運作的指令,這一行必須以制表符TAB開頭
第三周、資訊的表示和處理
資訊存儲
計算機最小的可尋址的存儲器機關——位元組
資料大小
在不同字長的計算機中,相同的資料類型所占用的位元組數并不相同,32位和64位的差別參見教材26頁表格。
gcc -m32可以在64位機上生成32位的代碼
表示字元串和表示代碼
字元串
c語言中字元串被編碼成為一個以null(值為0)字元結尾的字元數組。多使用ASCII字元碼。
在使用ASCII字元碼的任何系統上都能得到相同的結果,與位元組順序和字大小規則無關,是以文本資料比二進制資料具有更強的平台獨立性。
代碼
二進制代碼在不同的作業系統上有不同的編碼規則。是以二進制代碼是不相容的。
位級運算
位運算:位向量按位進行邏輯運算,結果仍是位向量(差別于邏輯運算)
※常見用法:掩碼——用來選擇性的屏蔽信号
掩碼是一個位模式,表示從一個字中選出的位的集合。
用位向量給集合編碼,通過指定掩碼來有選擇的屏蔽或者不屏蔽一些信号,比如
某一位位置上為1時,表明信号i是有效的;0表示該信号被屏蔽。
邏輯運算
邏輯運算符
與:&&
或:||
非:!```
###邏輯運算的計算方法:
所有非零參數都代表TRUE,0參數代表FALSE
### 邏輯運算的結果:
1-代表TRUE,或者,0-代表FALSE
1c語言中的移位運算
右移分為邏輯右移和算術右移。(其實左移也區分,但是算術左移和邏輯左移沒有什麼差別)
邏輯右移:
在左端補k個0,多用于無符号數移位運算
算術右移:
在左端補k個最高有效位的值,多用于有符号數移位運算。
###整型資料類型
整型資料類型——表示有限範圍的整數,每種類型都能用關鍵字來指定大小,還可以指定是非負數(unsigned)還是負數(預設)。這些不同大小的配置設定的字數會根據機器的字長和編譯器有所不同。
整數運算
——實際上這是一種模運算。
###無符号運算
無符号運算本質上就是模運算,mod 2的w次幂。
###浮點數
浮點表示對形如V=x X (2^y)的有理數進行編碼,适用于:
非常大的數字
非常接近于0的數字
作為實數運算的近似值
##第四周、處理器體系結構
###一、概述
1、現代微處理器可以稱得上人類創造的最複雜的系統之一
2、一個處理器支援的指令和指令的位元組級編碼稱為它的指令級體系結構
###二、Y86指令集體系結構
簡易圖示
###三、邏輯設計和硬體控制語言HCL
#####1、邏輯門
AND:&&
OR:||
NOT:!
#####2、組合電路和布爾表達式
* 兩個或多個邏輯門的輸出不能連接配接在一起,否則可能會使線上的信号沖突,導緻一個不合法的電壓或電路故障
* 網必須無環
#####3、字級的組合電路和HCL整數表達式
`一些位級信号代表一個整數或一些控制模式。執行字級計算的組合電路根據輸入字的各個位,用邏輯門來計算輸出字的各個位。`
#####4、集合關系
判斷集合關系的通用格式:
Iexpr in {iexpr1,iexpr2,…,iexprk}
#####5、存儲器和時鐘
組合電路從本質上講,不存儲任何資訊。隻響應輸入産生輸出。
時序電路:有狀态并且在這個狀态上進行計算的系統。
時鐘寄存器:存儲單個位或者字。時鐘信号控制寄存器加載輸入值。
随機通路存儲器:存儲多個字,用位址選擇該讀寫哪個字:
(1) 處理器的虛拟存儲器系統
(2) 寄存器檔案
Y86處理器會用時鐘寄存器儲存程式計數器(PC),條件代碼(CC)和程式狀态(Stat)。
寄存器檔案有兩個讀端口和一個寫端口。
###四、Y86的順序實作
#####1、 将處理組織成階段
下面是關于各個階段以及各階段内執行操作的簡略描述:
· `取指:取指階段從存儲器讀取指令位元組,位址為程式計數器(PC)的值.`
· `譯碼:譯碼階段從寄存器檔案讀入最多兩個操作數,得到val A/val B.`
· `執行:執行階段,算術/邏輯單元要麼執行指令明确的操作(根據ifun的值),計算存儲器引用的有效位址,要麼增加或減少棧指針。得到的值稱為valE`
· `訪存:訪存階段可将資料寫入存儲器或從存儲器讀出資料`
· `寫回:最多可寫兩個結果到存儲器`。
· `更新PC:将PC設定成下一指令的位址`
·
##第五周、處理器體系結構
随機通路存儲器分為兩類:靜态和動态
####1、靜态RAM
靜态RAM 的基本存儲電路為觸發器,每個觸發器存放一位二進制資訊,由若幹個觸發器組成一個存儲單元,再由若幹存儲單元組成存儲器矩陣,加上位址譯碼器和讀/寫控制電路就組成靜态RAM。但由于靜态RAM 是通過有源電路來保持存儲器中的資料,是以,要消耗較多功率,價格也較高。
####2、動态RAM
每一個比特的資料都隻需一個電容跟一個半導體來處理,相比之下在SRAM上一個比特通常需要六個半導體。正因這緣故,DRAM擁有非常高的密度,機關體積的容量較高是以成本較低。但相反的,DRAM也有通路速度較慢,耗電量較大的缺點。
##局部性
1、局部性原理: CPU通路存儲器時,無論是存取指令還是存取資料,所通路的存儲單元都趨于聚集在一個較小的連續區域中。
2、三種不同類型的局部性:時間局部性(Temporal Locality):如果一個資訊項正在被通路,那麼在近期它很可能還會被再次通路。程式循環、堆棧等是産生時間局部性的原因。空間局部性(Spatial Locality):在最近的将來将用到的資訊很可能與現在正在使用的資訊在空間位址上是臨近的。順序局部性(Order Locality):在典型程式中,除轉移類指令外,大部分指令是順序進行的。順序執行和非順序執行的比例大緻是5:1。此外,對大型數組通路也是順序的。指令的順序執行、數組的連續存放等是産生順序局部性的原因
##第六周 存儲器層次結構
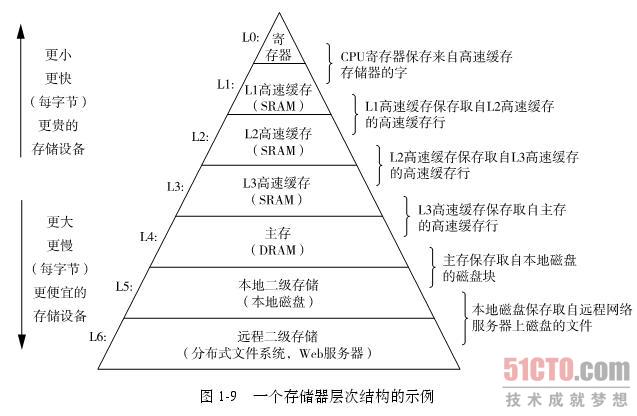
###1、緩存命中
若需要通路k+1層裡的資料塊d,如果d已經緩存在第k層,則稱緩存命中。這樣從第k層取塊d要比k+1層更塊。
###2、緩存不命中
`若d不在第k層,則是緩存不命中,此時将k+1層存儲中取出塊d,放入k層。可能需要替換掉k層中已有的塊。替換政策是:随機,最近最少使用等。需要有個東西對緩存進行管理,比如怎麼進行塊的劃分,各層次間怎麼傳送塊,判斷是否命中,不命中該如何處理,寫回資料的時候該如何處理。都是需要考慮的問題,可用硬體管理如cache,也可用軟體管理如虛拟記憶體。`
###3、緩存的管理
i)相關假定
假定存儲器的位址有m位,便有M=2m 不同位址。
一個緩存被分成S=2s個的高速緩存組(cache set),
每個組包含 E 個高速緩存行。
每個緩存行由一個B=2b位元組的資料塊,一個有效位,t=m-(b+s)個标記位組成。
一個高速緩沖區的大小C = S * E * B。
ii)如何通路緩存
當要通路存儲器中的一個位元組時,給出的通路位址的m位中,前t位表示标記位,中間s位為組索引,最後b位為塊偏移。
iii)緩存不命中時
當緩存不命中時,則若需要将存儲器中的塊放入緩存對應的組中。
若組中的行都有資料,則需要進行替換,替換政策是:LFU或這LRU(不想細說了)
iv)三種緩存方式的劃分
分為直接映射高速緩存,組相聯高速緩存,全相聯高速緩存
若指定了S,E,B的值,則緩存的劃分方式就已經确定了。
緩存塊與存儲塊之間也就建立了一種映射關系。
* 參考資料:
* 1、《深入了解計算機系統》課本第一章到第七章
* 2、本人之前的部落格
* 3、 闫佳歆同學的部落格http://www.cnblogs.com/20135202yjx/p/4926597.html
###收獲:這個學期學習的深入了解計算機系統這門課和之前我們上的課有着極大的不同,這門課主要的學習方式是課下自學然乎課上進行考試。這樣一來有助于調動我們課下學習的積極性,二來也可以檢測我們的學習狀況。也讓我們真正對計算機系統有了了解,包括存儲器結構,作業系統,資料的存儲,虛拟機的使用等等。而這門課真正的意義在于讓我們養成了一種下課學習的習慣,之前我們的學習模式大多是上課聽,下課不複習,期末熬夜看,這樣不僅沒有學到知識,而且還傷害身體。而現在,我了解了平時學習的重要性,不隻是這門課,其餘的課程我也進行了課後的複習,每節課知識量不大,不需要花費特别多時間,但是效果卻很好。希望在以後的學習中能夠延續這種方法。争取在大學期間真正學到知識。
###不足:由于之前學習方法的不正确,導緻基礎比較薄弱,是以在老師布置任務以後,覺得任務量太大,因為總是需要補充之前的知識。是以有的時候會産生厭煩的情緒,導緻學習效率有些低下。由于現在的學習,讓我的基礎有了提高,再加上自己适應了這種教學模式,是以以後應該不會再出現這種問題。還有就是對知識點沒有深入地了解,知識掌握同學和老師的講解,沒有深入到核心中,了解這個知識點的背景,和深刻的内涵。以後要繼續加強對知識點的深入了解,可以利用百度,部落格園提問等方式,弄清楚深層的問題,這樣也算是真正的了解。