分布式并行計算MapReduce
一、用自己的話闡明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作過程。
1.HDFS: Hadoop Distributed File System Hadoop分布式檔案系統
1.1功能:
1.相容廉價的硬體裝置。2.流資料的讀寫。3.大資料集。4.簡單的檔案模型。5.強大的誇平台相容性。
1.2工作原理:用戶端要向HDFS寫資料,首先要跟namenode通信以确認可以寫檔案并獲得接收檔案block的datanode,然後用戶端按順序将檔案逐個block傳遞給相應datanode,并由接收到block的datanode負責向其他datanode複制block的副本。
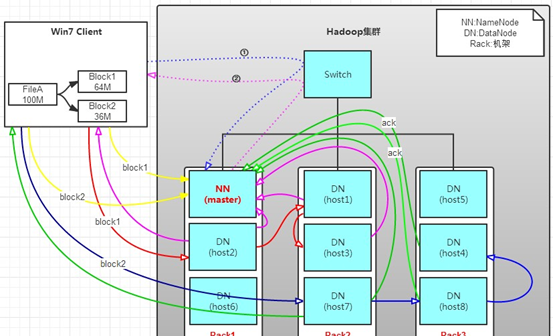
1.3工作過程:
l hdfs叢集分為兩大角色:NameNode,DataNode (Secondary NameNode)
l NameNode負責管理整個檔案的中繼資料(命名空間資訊,塊資訊) 相當于Master
l DataNode負責管理使用者的檔案資料塊 相當于Salve
l 檔案會按照固定的大小(block=128M)切成若幹塊後分布式存儲在若幹個datanode節點上
l 每一個檔案塊有多個副本(預設是三個),存在不同的datanode上
l DataNode會定期向NameNode彙報自身所儲存的檔案block資訊,而namenode則會負責保持檔案副本數量
l hdfs的内部工作機制會對客戶的保持透明,用戶端請求方法hdfs都是通過向namenode申請來進行通路
2.MapReduce
2.1功能:MapReduce是一種并行可擴充計算模型,并且有較好的容錯性,主要解決海量離線資料的批處理。實作下面目标
易于程式設計、良好的擴充性、高容錯性
2.2工作原理:MapReduce是一種可用于資料處理的程式設計架構。MapReduce采用"分而治之"的思想,把對大規模資料集的操作,分發給一個主節點管理下的各個分節點共同完成,然後通過整合各個節點的中間結果,得到最終結果。簡單地說,MapReduce就是"任務的分解與結果的彙總"。
在分布式計算中,MapReduce架構負責處理了并行程式設計中分布式存儲、工作排程、負載均衡、容錯均衡、容錯處理以及網絡通信等複雜問題,把處理過程高度抽象為兩個函數:map和reduce,map負責把任務分解成多個任務,reduce負責把分解後多任務處理的結果彙總起來。

2.3工作過程
1,大資料經split劃分成大小相等的資料塊(資料塊的大小一般等于HDFS一個塊的大小)以及使用者作業程式。
2,系統中有一個負責排程的Master節點和許多的Map工作節點,Reduce工作節點
3,使用者作業程式送出給Master節點,Master節點尋找合适的Map節點,并将資料傳給Map節點,并且Master也尋找合适的Reduce節點并将資料傳給Reduce節點
4,Master節點啟動Map節點執行程式,Map節點盡可能的讀取本地或本機架上的資料塊進行計算。(資料本地化是Mapreduce的核心特征)
5,每個Map節點處理讀取的資料塊,并做一些資料整理,并且将中間結果放在本地而非HDFS中,同時通知Master節點Map工作完成,并告知中間結果的存儲位置。
6,Master節點等所有Map工作完成後,開始啟動Reduce節點,Reduce節點通過Master節點掌握的中間結果的存儲位置來遠端讀取中間結果。
7,Reduce節點将中間結果處理後将結果輸出到一個檔案中。
從使用者作業程式角度來看:
一個作業執行過程中有一個Jobtracker和多個Tasktracker,分别對應于HDFS中的namenode和datanode。Jobclient在使用者端把已配置參數打包成jar檔案存儲在HDFS,并把存儲路徑送出給Jobtracker,然後Jobtracker建立每一個Task,并且分發到Tasktracker服務中去執行。
2.HDFS上運作MapReduce
1)準備文本檔案,放在本地/home/hadoop/wc
2)編寫map函數和reduce函數,在本地運作測試通過
嘗試運作:
3)啟動Hadoop:HDFS, JobTracker, TaskTracker
4)把文本檔案上傳到hdfs檔案系統上 user/hadoop/input
5)streaming的jar檔案的路徑寫入環境變量,讓環境變量生效
6)建立一個shell腳本檔案:streaming接口運作的腳本,名稱為run.sh
7)source run.sh來執行mapreduce
8)檢視運作結果