作業要求來自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
爬蟲綜合大作業
- 選擇一個熱點或者你感興趣的主題。
- 選擇爬取的對象與範圍。
- 了解爬取對象的限制與限制。
- 爬取相應内容。
- 做資料分析與文本分析。
- 形成一篇文章,有說明、技術要點、有資料、有資料分析圖形化展示與說明、文本分析圖形化展示與說明。
- 文章公開釋出。
1. 資料爬取
我們本次爬取的對象是一首名為《five hours》的經典電音流行歌曲,Five Hours是Erick Orrosquieta于2014年4月發行的單曲,當年這首單曲就出現在奧地利,比利時,法國,荷蘭,挪威,瑞典和瑞士的榜單中。
作者Erick Orrosquieta,一般為人熟知的是他的藝名Deorro,2014年世界百大DJ排名十九位。1991年8月29日生于美國洛杉矶,墨西哥血統的音樂制作人,簽約Ultra Records,2014年他創立了唱片公司Panda Funk。Deorro以前用過TON!C這個名字。Deorro的音樂傾向Melbourne Bounce風格,融合Dutch、 moombah, progressive、 house、貝斯等多種元素和風格,幾分鐘就可以點炸現場氣氛。他的這首單曲“Five Hours”登頂Most Played on Dance Radio和Most Played on Top 40 radio Mixshows。
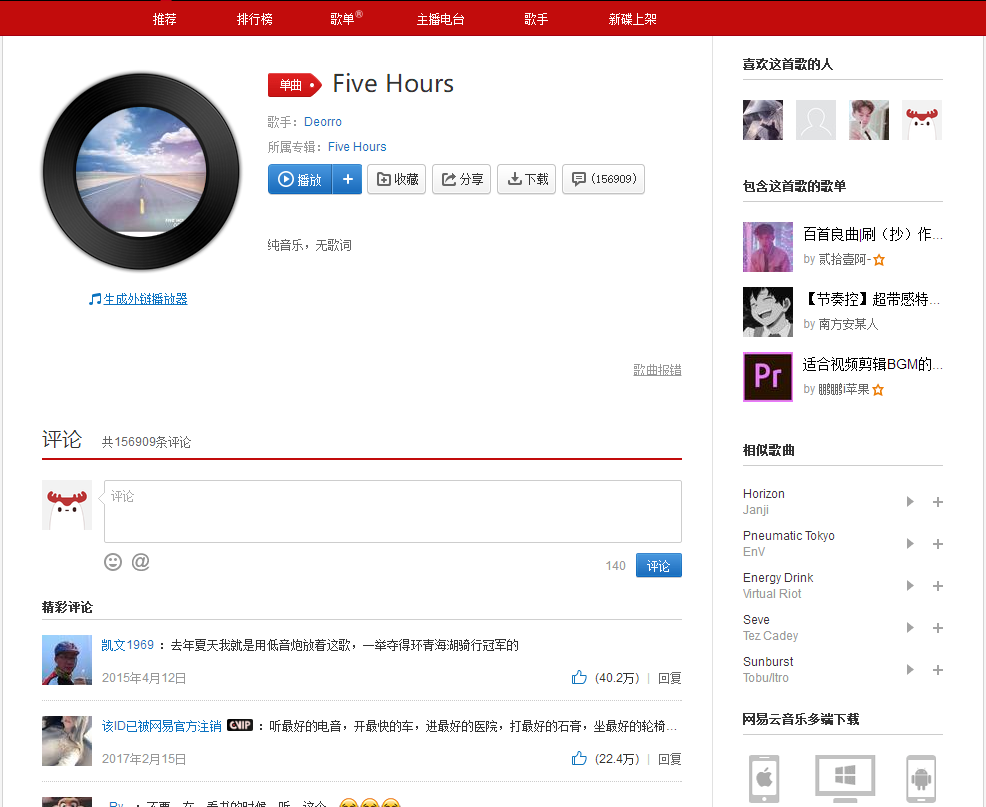
而在爬蟲部分主要是調用官方API,本次用到的API主要有兩個:
①擷取評論:
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit={每頁限制數量}&offset={評論數總偏移}
②擷取評論對應使用者的資訊:
https://music.163.com/api/v1/user/detail/{使用者ID}
完成後的項目檔案圖如下:

1.1 評論爬取
具體代碼如下:
1 from urllib import request
2 import json
3 import pymysql
4 from datetime import datetime
5 import re
6
7 ROOT_URL = 'http://music.163.com/api/v1/resource/comments/R_SO_4_%s?limit=%s&offset=%s'
8 LIMIT_NUMS = 50 # 每頁限制爬取數
9 DATABASE = 'emp' # 資料庫名
10 TABLE = 'temp1' # 資料庫表名
11 # 資料表設計如下:
12 '''
13 commentId(varchar)
14 content(text) likedCount(int)
15 userId(varchar) time(datetime)
16 '''
17 PATTERN = re.compile(r'[\n\t\r\/]') # 替換掉評論中的特殊字元以防插入資料庫時報錯
18
19 def getData(url):
20 if not url:
21 return None, None
22 headers = {
23 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36',
24 "Host": "music.163.com",
25 }
26 print('Crawling>>> ' + url)
27 try:
28 req = request.Request(url, headers=headers)
29 content = request.urlopen(req).read().decode("utf-8")
30 js = json.loads(content)
31 total = int(js['total'])
32 datas = []
33 for c in js['comments']:
34 data = dict()
35 data['commentId'] = c['commentId']
36 data['content'] = PATTERN.sub('', c['content'])
37 data['time'] = datetime.fromtimestamp(c['time']//1000)
38 data['likedCount'] = c['likedCount']
39 data['userId'] = c['user']['userId']
40 datas.append(data)
41 return total, datas
42 except Exception as e:
43 print('Down err>>> ', e)
44 pass
45
46 def saveData(data):
47 if not data:
48 return None
49 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4') # 注意字元集要設為utf8mb4,以支援存儲評論中的emoji表情
50 cursor = conn.cursor()
51 sql = 'insert into ' + TABLE + ' (commentId,content,likedCount,time,userId) VALUES (%s,%s,%s,%s,%s)'
52
53 for d in data:
54
55 try:
56 #cursor.execute('SELECT max(c) FROM '+TABLE)
57 #id_ = cursor.fetchone()[0]
58
59 cursor.execute(sql, (d['commentId'], d['content'], d['likedCount'], d['time'], d['userId']))
60 conn.commit()
61 except Exception as e:
62 print('mysql err>>> ',d['commentId'],e)
63 pass
64
65 cursor.close()
66 conn.close()
67
68 if __name__ == '__main__':
69 songId = input('歌曲ID:').strip()
70 total,data = getData(ROOT_URL%(songId, LIMIT_NUMS, 0))
71 saveData(data)
72 if total:
73 for i in range(1, total//50+1):
74 _, data = getData(ROOT_URL%(songId, LIMIT_NUMS, i*(LIMIT_NUMS)))
75 saveData(data) 實際操作過程中,網易雲官方對于API的請求是有限制的,有條件的可以采用更換代理IP來防反爬,而這一次作業在爬取資料的時候由于前期操作過度,導緻被BAN IP,資料無法擷取,之後是通過挂載虛拟IP才實作資料爬取的。
本次采用的是單線程爬取,是以IP封的并不太頻繁,後面會對代碼進行重構,實作多線程+更換IP來加快爬取速度。
根據擷取評論的API,請求URL有3個可變部分:每頁限制數limit和評論總偏移量offset,通過API分析得知:當offeset=0時,傳回json資料中包含有評論總數量total。
本次共爬取5394條資料(避免盲目多爬被封ID)
1.2 使用者資訊爬取
1 from urllib import request
2 import json
3 import pymysql
4 import re
5
6 ROOT_URL = 'https://music.163.com/api/v1/user/detail/'
7 DATABASE = 'emp'
8 TABLE_USERS = 'temp2'
9 TABLE_COMMENTS = 'temp1'
10 # 資料表設計如下:
11 '''
12 id(int) userId(varchar)
13 gender(char) userName(varchar)
14 age(int) level(int)
15 city(varchar) sign(text)
16 eventCount(int) followedCount(int)
17 followsCount(int) recordCount(int)
18 avatar(varchar)
19 '''
20 PATTERN = re.compile(r'[\n\t\r\/]') # 替換掉簽名中的特殊字元以防插入資料庫時報錯
21 headers = {
22 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36',
23 "Host": "music.163.com",
24 }
25 def getData(url):
26 if not url:
27 return None
28 print('Crawling>>> ' + url)
29 try:
30 req = request.Request(url, headers=headers)
31 content = request.urlopen(req).read().decode("utf-8")
32 js = json.loads(content)
33 data = {}
34 if js['code'] == 200:
35 data['userId'] = js['profile']['userId']
36 data['userName'] = js['profile']['nickname']
37 data['avatar'] = js['profile']['avatarUrl']
38 data['gender'] = js['profile']['gender']
39 if int(js['profile']['birthday'])<0:
40 data['age'] = 0
41 else:
42 data['age'] =(2018-1970)-(int(js['profile']['birthday'])//(1000*365*24*3600))
43 if int(data['age'])<0:
44 data['age'] = 0
45 data['level'] = js['level']
46 data['sign'] = PATTERN.sub(' ', js['profile']['signature'])
47 data['eventCount'] = js['profile']['eventCount']
48 data['followsCount'] = js['profile']['follows']
49 data['followedCount'] = js['profile']['followeds']
50 data['city'] = js['profile']['city']
51 data['recordCount'] = js['listenSongs']
52
53 saveData(data)
54 except Exception as e:
55 print('Down err>>> ', e)
56 pass
57 return None
58
59 def saveData(data):
60 if not data:
61 return None
62 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4') # 注意字元集要設為utf8mb4,以支援存儲簽名中的emoji表情
63 cursor = conn.cursor()
64 sql = 'insert into ' + TABLE_USERS + ' (userName,gender,age,level,city,sign,eventCount,followsCount,followedCount,recordCount,avatar,userId) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
65 try:
66
67
68 cursor.execute(sql, (data['userName'],data['gender'],data['age'],data['level'],data['city'],data['sign'],data['eventCount'],data['followsCount'],data['followedCount'],data['recordCount'],data['avatar'],data['userId']))
69 conn.commit()
70 except Exception as e:
71 print('mysql err>>> ',data['userId'],e)
72 pass
73 finally:
74 cursor.close()
75 conn.close()
76
77 def getID():
78 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4')
79 cursor = conn.cursor()
80 sql = 'SELECT userId FROM '+TABLE_COMMENTS
81 try:
82 cursor.execute(sql)
83 res = cursor.fetchall()
84 return res
85 except Exception as e:
86 print('get err>>> ', e)
87 pass
88 finally:
89 cursor.close()
90 conn.close()
91 return None
92
93 if __name__ == '__main__':
94 usersID = getID()
95 for i in usersID:
96 getData(ROOT_URL+i[0].strip())
97 根據擷取使用者資訊的API,請求URL有1個可變部分:使用者ID,前一部分已經将每條評論對應的使用者ID也存儲下來,這裡隻需要從資料庫取使用者ID并抓取資訊即可(對應以上的5394條資料)。
至此,已經完成了歌曲評論和對應使用者資訊的抓取。接下來,對抓取到的資料進行清洗及可視化分析。
2 資料清洗 & 可視化
處理代碼如下:
1 import pandas as pd
2 import pymysql
3 from pyecharts import Bar,Pie,Line,Scatter,Map
4
5 TABLE_COMMENTS = 'temp1'
6 TABLE_USERS = 'temp2'
7 DATABASE = 'emp'
8
9 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4')
10 sql_users = 'SELECT id,gender,age,city FROM '+TABLE_USERS
11 sql_comments = 'SELECT id,time FROM '+TABLE_COMMENTS
12 comments = pd.read_sql(sql_comments, con=conn)
13 users = pd.read_sql(sql_users, con=conn)
14
15 # 評論時間(按天)分布分析
16 comments_day = comments['time'].dt.date
17 data = comments_day.id.groupby(comments_day['time']).count()
18 line = Line('評論時間(按天)分布')
19 line.use_theme('dark')
20 line.add(
21 '',
22 data.index.values,
23 data.values,
24 is_fill=True,
25 )
26 line.render(r'./評論時間(按天)分布.html')
27 # 評論時間(按小時)分布分析
28 comments_hour = comments['time'].dt.hour
29 data = comments_hour.id.groupby(comments_hour['time']).count()
30 line = Line('評論時間(按小時)分布')
31 line.use_theme('dark')
32 line.add(
33 '',
34 data.index.values,
35 data.values,
36 is_fill=True,
37 )
38 line.render(r'./評論時間(按小時)分布.html')
39 # 評論時間(按周)分布分析
40 comments_week = comments['time'].dt.dayofweek
41 data = comments_week.id.groupby(comments_week['time']).count()
42 line = Line('評論時間(按周)分布')
43 line.use_theme('dark')
44 line.add(
45 '',
46 data.index.values,
47 data.values,
48 is_fill=True,
49 )
50 line.render(r'./評論時間(按周)分布.html')
51
52 # 使用者年齡分布分析
53 age = users[users['age']>0] # 清洗掉年齡小于1的資料
54 age = age.id.groupby(age['age']).count() # 以年齡值對資料分組
55 Bar = Bar('使用者年齡分布')
56 Bar.use_theme('dark')
57 Bar.add(
58 '',
59 age.index.values,
60 age.values,
61 is_fill=True,
62 )
63 Bar.render(r'./使用者年齡分布圖.html') # 生成渲染的html檔案
64
65 # 使用者地區分布分析
66 # 城市code編碼轉換
67 def city_group(cityCode):
68 city_map = {
69 '11': '北京',
70 '12': '天津',
71 '31': '上海',
72 '50': '重慶',
73 '5e': '重慶',
74 '81': '香港',
75 '82': '澳門',
76 '13': '河北',
77 '14': '山西',
78 '15': '内蒙古',
79 '21': '遼甯',
80 '22': '吉林',
81 '23': '黑龍江',
82 '32': '江蘇',
83 '33': '浙江',
84 '34': '安徽',
85 '35': '福建',
86 '36': '江西',
87 '37': '山東',
88 '41': '河南',
89 '42': '湖北',
90 '43': '湖南',
91 '44': '廣東',
92 '45': '廣西',
93 '46': '海南',
94 '51': '四川',
95 '52': '貴州',
96 '53': '雲南',
97 '54': '西藏',
98 '61': '陝西',
99 '62': '甘肅',
100 '63': '青海',
101 '64': '甯夏',
102 '65': '新疆',
103 '71': '台灣',
104 '10': '其他',
105 }
106 return city_map[cityCode[:2]]
107
108 city = users['city'].apply(city_group)
109 city = city.id.groupby(city['city']).count()
110 map_ = Map('使用者地區分布圖')
111 map_.add(
112 '',
113 city.index.values,
114 city.values,
115 maptype='china',
116 is_visualmap=True,
117 visual_text_color='#000',
118 is_label_show=True,
119 )
120 map_.render(r'./使用者地區分布圖.html') 關于資料的清洗,實際上在上一部分抓取資料的過程中已經做了一部分,包括:背景傳回的空使用者資訊、重複資料的去重等。除此之外,還要進行一些清洗:使用者年齡錯誤、使用者城市編碼轉換等。
關于資料的去重,評論部分可以以sommentId為資料庫索引,利用資料庫來自動去重;使用者資訊部分以使用者ID為資料庫索引實作自動去重。
①API傳回的使用者年齡一般是時間戳的形式(以毫秒計)、有時候也會傳回一個負值或者一個大于目前時間的值,暫時沒有找到這兩種值代表的含義,故而一律按0來處理。
②API傳回的使用者資訊中,城市分為province和city兩個字段,本此分析中隻儲存了city字段。實際上字段值是一個城市code碼
③在這部分,利用Python的資料處理庫pandas進行資料處理,利用可視化庫pyecharts進行資料可視化。
以上,是對抓取到的資料采用可視化庫pyecharts進行可視化分析,得到的結果如下:
結論一:評論時間按周分布圖可以看出,評論數在一周當中前面較少,後面逐漸增多,這可以解釋為往後接近周末,大家有更多時間來聽聽歌、刷刷歌評,而一旦周末過完,評論量馬上下降(周日到周一的下降過渡),大家又回歸到工作當中。
結論二:評論時間按小時分布圖可以看出,評論數在一天當中有兩個小高峰:11點-13點和22點-0點。這可以解釋為使用者在中午午飯時間和晚上下班(課)在家時間有更多的時間來聽歌刷評論,符合使用者的日常。至于為什麼早上沒有出現一個小高峰,大概是早上大家都在搶時間上班(學),沒有多少時間去刷評論。
結論三:使用者年齡分布圖可以看出,使用者大多集中在14-30歲之間,以20歲左右居多,除去虛假年齡之外,這個年齡分布也符合網易雲使用者的年齡段。圖中可以看出28歲有個高峰,猜測可能是包含了一些異常資料,有興趣的化可以做進一步分析。
結論四:使用者地區分布圖可以看出,使用者涵蓋了全國各大省份,因為中間資料(坑)的缺失,并沒有展現出哪個省份特别突出的情況。對别的歌評(完全資料)的可視化分析,可以看出明顯的地區分布差異。使用者地區分布圖可以看出,使用者涵蓋了全國各大省份,因為中間資料的缺失,并沒有展現出哪個省份特别突出的情況。對别的歌評(完全資料)的可視化分析,可以看出明顯的地區分布差異。
細心觀察評論數(按天)分布那張圖,發現2017年到2018年間有很大一部分資料缺失,這實際上是因為在資料抓取過程中出現的問題。研究了一下發現,根據擷取歌曲評論的API,實際上每首歌最多隻能獲得2w條左右(去重後)的評論,對于評論數超過2w的歌曲,隻能獲得前後(日期)各1w條評論,而且這個限制對于網易雲官網也是存在的,具體表現為:對一首評論數超過2w的歌,如果一直往後浏覽評論,會發現從第500頁(網頁端網易雲每頁20條評論)往後,背景傳回的内容和第500頁完全一樣,從後往前同理。這應該是官方背景做了限制,連自家也不放過。。。
此次分析隻是對某一首歌曲評論時間、使用者年齡/地區分布進行的,實際上抓取到的資訊不僅僅在于此,可以做進一步分析(比如利用評論内容進行文本内容分析等),這部分,未來會進一步分析。當然也可以根據自己情況對不同歌曲進行分析。
3.歌評文本分析
評論的文本分析做了兩部分:情感分析和詞雲生成。
情感分析采用Python的文本分析庫snownlp。具體代碼如下:
1 import numpy as np
2 import pymysql
3 from snownlp import SnowNLP
4 from pyecharts import Bar
5
6 TABLE_COMMENTS = 'temp1'
7 DATABASE = 'emp'
8 SONGNAME = 'five hours'
9
10 def getText():
11 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db=DATABASE, charset='utf8')
12 sql = 'SELECT id,content FROM '+TABLE_COMMENTS
13 text = pd.read_sql(sql%(SONGNAME), con=conn)
14 return text
15
16 def getSemi(text):
17 text['content'] = text['content'].apply(lambda x:round(SnowNLP(x).sentiments, 2))
18 semiscore = text.id.groupby(text['content']).count()
19 bar = Bar('評論情感得分')
20 bar.use_theme('dark')
21 bar.add(
22 '',
23 y_axis = semiscore.values,
24 x_axis = semiscore.index.values,
25 is_fill=True,
26 )
27 bar.render(r'情感得分分析.html')
28
29 text['content'] = text['content'].apply(lambda x:1 if x>0.5 else -1)
30 semilabel = text.id.groupby(text['content']).count()
31 bar = Bar('評論情感标簽')
32 bar.use_theme('dark')
33 bar.add(
34 '',
35 y_axis = semilabel.values,
36 x_axis = semilabel.index.values,
37 is_fill=True,
38 )
39 bar.render(r'情感标簽分析.html') 結果:
詞雲生成采用jieba分詞庫分詞,wordcloud生成詞雲,具體代碼如下:
1 from wordcloud import WordCloud
2 import matplotlib.pyplot as plt
3 plt.style.use('ggplot')
4 plt.rcParams['axes.unicode_minus'] = False
5
6 def getWordcloud(text):
7 text = ''.join(str(s) for s in text['content'] if s)
8 word_list = jieba.cut(text, cut_all=False)
9 stopwords = [line.strip() for line in open(r'./StopWords.txt', 'r').readlines()] # 導入停用詞
10 clean_list = [seg for seg in word_list if seg not in stopwords] #去除停用詞
11 clean_text = ''.join(clean_list)
12 # 生成詞雲
13 cloud = WordCloud(
14 font_path = r'C:/Windows/Fonts/msyh.ttc',
15 background_color = 'white',
16 max_words = 800,
17 max_font_size = 64
18 )
19 word_cloud = cloud.generate(clean_text)
20 # 繪制詞雲
21 plt.figure(figsize=(12, 12))
22 plt.imshow(word_cloud)
23 plt.axis('off')
24 plt.show()
25
26 if __name__ == '__main__':
27 text = getText()
28 getSemi(text)
29 getWordcloud(text) 詞雲: