作業要求來源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字元串操作:
解析身份證号:生日、性别、出生地等。
代碼如下: # # -*- coding: utf-8 -*-
import re
pattern = r"^[1-6]\d{5}[12]\d{3}(0[1-9]|1[12])(0[1-9]|1[0-9]|2[0-9]|3[01])\d{3}(\d|X|x)$"
ID = input("請輸入身份證号:")
res = re.match(pattern,ID)
if res == None :
print("身份證号輸入錯誤")4
else:
print("身份證号輸入正确")
print('身份證号是:{}'.format(ID))
year = ID[6:14]
print('出生年月為:{}'.format(year))
sex = ID[17]
if int(sex) % 2 == 1:
print("性别:男")
else:
print("性别:女")
運作之後顯示結果如下: 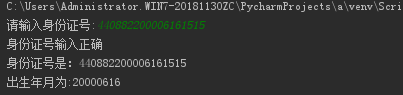
凱撒密碼編碼與解碼
def getTranslatedMessage(mode, message, key):
if mode[0] == 'd':
key = -key
translated = ''
for symbol in message:
if symbol.isalpha():
num = ord(symbol)
num += key
if symbol.isupper():
if num > ord('Z'):
num -= 26
elif num < ord('A'):
num += 26
elif symbol.islower():
if num > ord('z'):
num -= 26
elif num < ord('a'):
num += 26
translated += chr(num)
else:
translated += symbol
return translated
mode = getMode()
message = getMessage()
if mode[0] != 'b':
key = getKey()
print('根據你的輸入獲得到的資訊為:')
if mode[0] != 'b':
print(getTranslatedMessage(mode, message, key)) 運作之後顯示結果如下:
網址觀察與批量生成 代碼如下: import webbrowser as web # 引入第三方庫,并用as取别名web
url='http://news.gzcc.cn/html/xiaoyuanxinwen'
web.open_new_tab(url)
for i in range(1,4):
url1='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
print(url1)
web.open_new_tab('http://news.gzcc.cn/html/xiaoyuanxinwen/'+str(i)+'.html') 
2.英文詞頻統計預處理
- 下載下傳一首英文的歌詞或文章或小說,儲存為utf8檔案。
- 從檔案讀出字元串。
- 将所有大寫轉換為小寫
- 将所有其他做分隔符(,.?!)替換為空格
- 分隔出一個一個的單詞
- 并統計單詞出現的次數。
text="Mr. Johnson had never been up in an aerophane before and he had read a lot about air accidents," \
" so one day when a friend offered to take him for a ride in his own small phane, " \
"Mr. Johnson was very worried about accepting." \
" Finally, however, his friend persuaded him that it was very safe, and Mr. Johnson boarded the plane."
print(text.lower())
str=", . ! ? - ' :"
for s in str:
text=text.replace(s,'')
print(text.split())
print(text.count('you'),text.count('her'))
運作之後顯示結果如下: