作業要求來自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas讀出之前儲存的資料:
newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
newsdf = pd.read_csv(r'F:\gzccnews.csv')
一.把爬取的内容儲存到資料庫sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
儲存到MySQL資料庫
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
import pandas as pd
import pymysql
from sqlalchemy import create_engine
conInfo = "mysql+pymysql://user:@localhost:3306/gzccnews?charset=utf8"
engine = create_engine(conInfo,encoding='utf-8')
df = pd.DataFrame(allnews)
df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬蟲綜合大作業
- 選擇一個熱點或者你感興趣的主題。
- 選擇爬取的對象與範圍。
- 了解爬取對象的限制與限制。
- 爬取相應内容。
- 做資料分析與文本分析。
- 形成一篇文章,有說明、技術要點、有資料、有資料分析圖形化展示與說明、文本分析圖形化展示與說明。
- 文章公開釋出。
我要爬取的對象和範圍:李冰冰的微網誌内容
爬取對象來源:https://m.weibo.cn/u/1192515960?uid=1192515960&luicode=10000011&lfid=100103type%3D3%26q%3D%E6%9D%8E%E5%86%B0%E5%86%B0
第一步:分析網址
分析浏覽器發送請求的過程
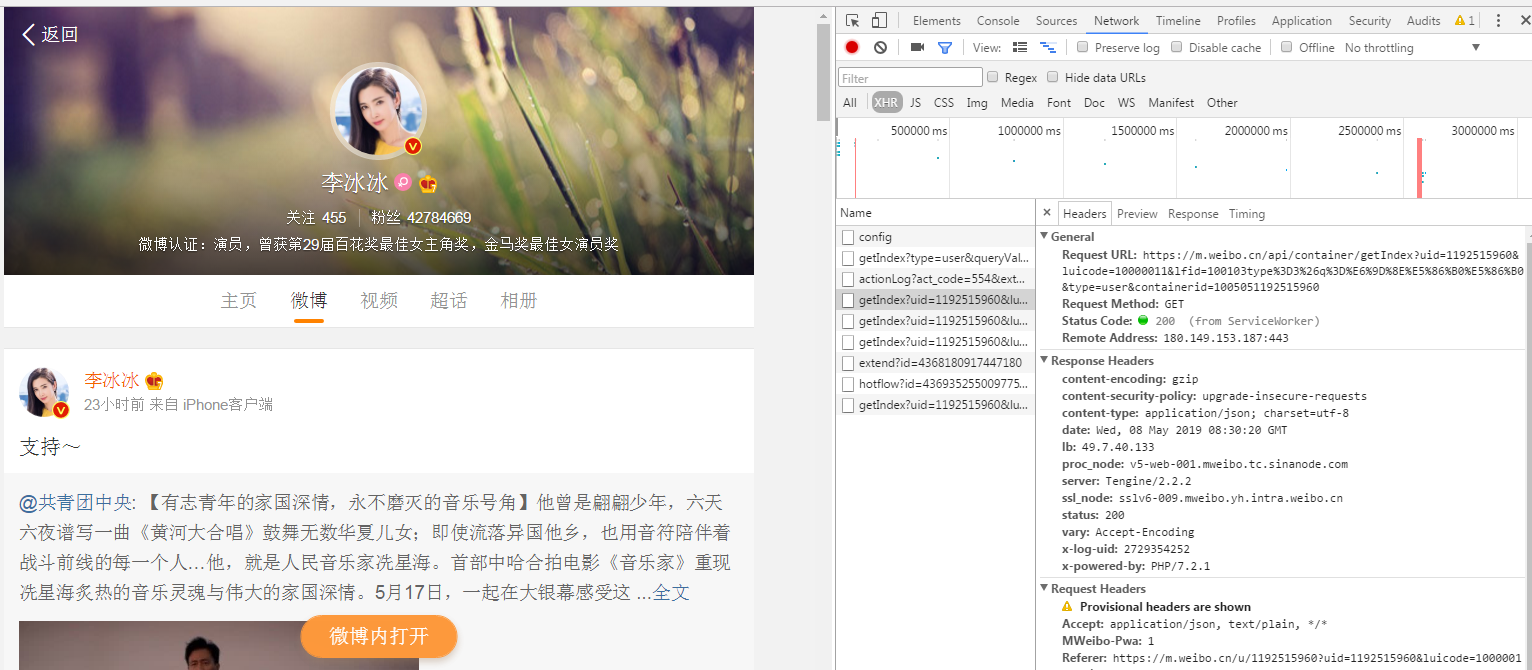
打開 Chrome 浏覽器的調試功能,選擇 Network 菜單,觀察到擷取微網誌資料的的接口是 https://m.weibo.cn/api/container/getIndex ,後面附帶了一連串的參數,這裡面有些參數是根據使用者變化的,有些是固定的,先提取出來。
uid=1192515960&
luicode=10000011&
lfid=100103type=3&q=李冰冰
featurecode=20000320&
type=user&
containerid=1005051192515960
再來分析接口的傳回結果,傳回資料是一個JSON字典結構,total 是微網誌總條數,每一條具體的微網誌内容封裝在 cards 數組中,具體内容字段是裡面的 text 字段。很多幹擾資訊已隐去。
{
"cardlistInfo": {
"containerid": "1005051192515960",
"total": 4963,
"page": 2
},
"cards": [
{
"card_type": 9,
"mblog": {
"created_at": "23小時前",
"idstr": "4369352550097750",
"text": "支援~",
}
}]
}
第二步:建構請求頭和查詢參數
分析完網頁後,開始用 requests 模拟浏覽器構造爬蟲擷取資料,因為這裡擷取使用者的資料無需登入微網誌,是以我們不需要構造 cookie資訊,隻需要基本的請求頭即可,具體需要哪些頭資訊也可以從浏覽器中擷取,首先構造必須要的請求參數,包括請求頭和查詢參數。

headers = {
"Host": "m.weibo.cn",
"Referer": "https://m.weibo.cn/u/1192515960",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) "
"Version/9.0 Mobile/13B143 Safari/601.1",
}
params = {"uid": "{uid}",
"luicode": "10000011",
"type": "uid",
"value": "1192515960",
"containerid": "{containerid}",
"page": "{page}"}
- uid是微網誌使用者的id
- containerid雖然不知道什麼意思,但也是和具體某個使用者相關的參數
- page 分頁參數
第三步:構造簡單爬蟲
通過傳回的資料能查詢到總微網誌條數 total,爬取資料直接利用 requests 提供的方法把 json 資料轉換成 Python 字典對象,從中提取出所有的 text 字段的值并放到 blogs 清單中,提取文本之前進行簡單過濾,去掉無用資訊。順便把資料寫入檔案,友善下次轉換時不再重複爬取。
def fetch_data(uid=None, container_id=None):
"""
抓取資料,并儲存到CSV檔案中
:return:
"""
page = 0
total = 4754
blogs = []
for i in range(0, total // 10):
params['uid'] = uid
params['page'] = str(page)
params['containerid'] = container_id
res = requests.get(url, params=params, headers=HEADERS)
cards = res.json().get("cards")
for card in cards:
# 每條微網誌的正文内容
if card.get("card_type") == 9:
text = card.get("mblog").get("text")
text = clean_html(text)
blogs.append(text)
page += 1
print("抓取第{page}頁,目前總共抓取了 {count} 條微網誌".format(page=page, count=len(blogs)))
with codecs.open('weibo.txt', 'w', encoding='utf-8') as f:
f.write("\n".join(blogs))
第四步:分詞處理并建構詞雲
爬蟲了所有資料之後,先進行分詞,這裡用的是結巴分詞,按照中文語境将句子進行分詞處理,分詞過程中過濾掉停止詞,處理完之後找一張參照圖,然後根據參照圖通過詞語拼裝成圖。
def generate_image():
data = []
jieba.analyse.set_stop_words("./stopwords.txt")
with codecs.open("weibo.txt", 'r', encoding="utf-8") as f:
for text in f.readlines():
data.extend(jieba.analyse.extract_tags(text, topK=20))
data = " ".join(data)
mask_img = imread('./52f90c9a5131c.jpg', flatten=True)
wordcloud = WordCloud(
font_path='msyh.ttc',
background_color='white',
mask=mask_img
).generate(data)
plt.imshow(wordcloud.recolor(color_func=grey_color_func, random_state=3),
interpolation="bilinear")
plt.axis('off')
plt.savefig('./heart2.jpg', dpi=1600)
最終效果圖:
總結:從李冰冰的微網誌動态可以看出,她是一個比較勵志的人,所散發的精神以積極向上為多。
參考:
32個Python爬蟲項目
都是誰在反對996?
Python和Java薪資最高,C#最低!
給《流浪地球》評1星的都是什麼心态?
《都挺好》彈幕資料,比劇情還精彩?
爬了自己的微信好友,原來他們是這樣的人……
春節人口遷徙大資料報告!
七夕前消費趨勢資料
爬了一下天貓上的Bra購買記錄,有了一些羞羞哒的發現...
Python做了六百萬字的歌詞分析,告訴你中國Rapper都在唱些啥
分析了42萬字歌詞後,終于搞清楚民謠歌手唱什麼了
十二星座的真實面目
唐朝詩人之間的關系到底是什麼樣的?
中國姓氏排行榜
三.爬蟲注意事項
1.設定合理的爬取間隔,不會給對方運維人員造成壓力,也可以防止程式被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.設定合理的user-agent,模拟成真實的浏覽器去提取内容。
- 首先打開你的浏覽器輸入:about:version。
- 使用者代理:
- 收集一些比較常用的浏覽器的user-agent放到清單裡面。
- 然後import random,使用随機擷取一個user-agent
- 定義請求頭字典headers={’User-Agen‘:}
- 發送request.get時,帶上自定義了User-Agen的headers
3.需要登入
發送request.get時,帶上自定義了Cookie的headers
headers={’User-Agen‘:
'Cookie': }
4.使用代理IP
通過更換IP來達到不斷高 效爬取資料的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
response = requests.get(url, headers=headers, proxies=proxies)