此次作業的要求來自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.清單,元組,字典,集合分别如何增删改查及周遊。
清單的增删改查及周遊操作:
test = [ 'Michael' , 'Bob',33,'李四','Tracy','may']
test[2]='aa'; #修改清單的值
test.insert(1,'jack')#增加清單的值
test.append('Cady');#在末尾增加清單的值
test.pop(3)#根據元素下标修改清單的值
x = test.index('may');
print(x);#根據清單元素查找元素在清單中的下标号
for i in list:
print ("序号:%s 值:%s" % (list.index(i) + 1, i))#清單的周遊
print(test) 元組的增删改查及周遊操作:
tu = (1, 2, 3, 'alex', [2, 3, 4, 'taibai'], 'egon')
print(tu[2]) # 查找元祖下标3的元素
print(tu[0:4]) # 查找元祖下标0-4的元素
for i in tu:
print(i) #循環元祖裡的元素,隻循環一次。
tu[4].append('ss')
print(tu) # 在元祖裡面的清單裡增加元素
del tu; #删除整個元組 字典的增删改查及周遊操作:
test = {'Alice': 44, 'Beth': 55, 'Cecil': 76,'Cady':78,'Bob':79};
# 字典裡更改元素
test['Beth'] = 65;
print(test);
# 字典增加資訊
test['Baby'] = 67;
print(test);
test = {'Alice': 95, 'Beth': 81, 'Cecil': 76,'Cady':87,'Bob':79,'Molly':86};
# 删除字典的資訊
del test['Alice'];
print(test);
# 清空字典的資訊
test.clear();
print(test);
# 删除字典,使用下面語句後整個字典被删除
del test 集合的增删改查及周遊操作:
test = {'Alice', 'Beth', 'Cecil', 'Cady', 'Bob', 'Molly'};
# 添加某個元素到集合中
test.add('Youth');
print(test);
# 添加元素到集合中
test.update({123, 456});
print(test);
basket = {'orange', 'banana', 'pear', 'apple'};
# 1.删除元素,如果元素不存在,則會發生錯誤
test.remove('Alice');
print(test);
# 2.删除元素,如果元素不存在,不會發生錯誤
test.discard('Beth');
print(test);
# 3.随機删除集合中的一個元素
x = basket.pop();
print("删除的元素是:", x);
print(basket); 2.總結清單,元組,字典,集合的聯系與差別。參考以下幾個方面:
- 括号
- 有序無序
- 可變不可變
- 重複不可重複
-
存儲與查找方式
答:
- 清單用“[]”表示,元組則是用“()”表示,字典最外面用花括号{},每一組用冒号連起來,然後各組用逗号隔開。集合可以用set()函數或者方括号{}建立,元素之間用逗号”,”分隔。
- 清單和元組都是有序的,而字典與集合為無序的。
- 清單中的元素可以是任意類型,也就是可變的序列,元組則屬于不可變序列類型 ,字典也是與可變序列。
- 清單,元組,字典都可重複,集合則不可重複。
清單和元組的存儲與查找方式通過值來完成,而字典則是通過鍵值對(鍵不能重複)來完成,集合則是通過鍵(不能重複)來完成。
總結:
清單和元組有很多相似的地方,操作也差不多。不過清單是可變序列,元組為不可變序列。也就是說清單主要用于對象長度不可知的情況下,而元組用于對象長度已知的情況下,而且元組元素一旦建立變就不可修改。 字典主要應用于需要對元素進行标記的對象,這樣在使用的時候便不必記住元素清單中或者元組中的位置,隻需要利用鍵來進行通路對象中相應的值。集合中的元素不可重複的特點使它被拿來去重。
3.詞頻統計
1.下載下傳一長篇小說,存成utf-8編碼的文本檔案 file
2.通過檔案讀取字元串 str
3.對文本進行預處理
4.分解提取單詞 list
5.單詞計數字典 set , dict
6.按詞頻排序 list.sort(key=lambda),turple
7.排除文法型詞彙,代詞、冠詞、連詞等無語義詞
自定義停用詞表
或用stops.txt
8.輸出TOP(20)
輸出的TOP(20)如下圖所示:
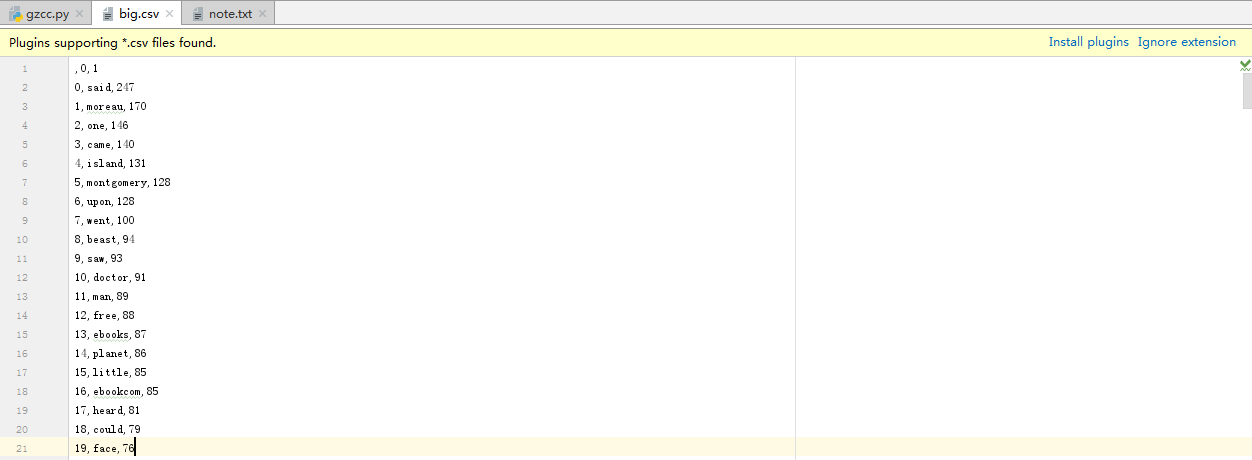
9.可視化:詞雲
詞雲生成結果:

線上工具生成詞雲:
https://wordart.com/create
exclude={ 'i','me','my','myself', 'we','our', 'ours','ourselves', 'you', "you're", "you've","you'll", "you'd", 'your', 'yours', 'yourself','yourselves', 'he', 'him', 'his', 'himself', 'she',"she's",'her','hers', 'herself', 'it', "it's",
'its', 'itself','they', 'them','their', 'theirs', 'themselves', 'what','which', 'who', 'whom', 'this', 'that', 'that', 'these','those','am','is','are','was','were','be','been',
'being', 'have', 'has', 'had', 'having','do', 'does', 'did', 'doing','a','an','the','and','but','if','or','because','as','until','while','of','at','by','for','with','about',
'against','between','into','through','during','before','after','above','below','to','from','up','down','in','out','on','off','over','under','again','further','then','once',
'here','there','when','where','why','how','all','any','both','each','few','more','most','other','some','such','no','nor','not','only','own','same','so','than','too','very','s','t',
'can','will','just','don',"don't",'should',"should've",'now','d','ll','m','o','re','ve','y','ain','aren',"aren't",'couldn',"couldn't",}#需要删除的無意義的詞語
def gettxt():
sep=".,:;?!"
txt=open('note.txt','r').read().lower()#打開txt檔案,并進行讀取,并把文章中的大寫字母轉換為小寫,進行檔案預處理
for ch in sep:
txt=txt.replace(ch,'')
return txt
bigList= gettxt().split()
print('has:',bigList.count('has'))
bigSet=set(bigList)
bigSet=bigSet-exclude#删除無意義的詞語
print(bigSet)
bigDict ={}
for word in bigSet:
bigDict[word] = bigList.count(word)#輸出詞語出現的頻率
print(bigDict)
#print(bigDict.keys())
#print(bigDict.items())
word=list(bigDict.items())
word.sort(key=lambda x:x[1],reverse=True)#通過詞頻的數量來排序,并且由大到小排序
print(word)
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')#把統計詞頻的結果儲存進名為big的csv格式的檔案中 實驗運作結果: