作業要求來源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3002
0.從新聞url擷取點選次數,并整理成函數
- newsUrl
- newsId(re.search())
- clickUrl(str.format())
- requests.get(clickUrl)
- re.search()/.split()
- str.lstrip(),str.rstrip()
- int
- 整理成函數
- 擷取新聞釋出時間及類型轉換也整理成函數
1 # 擷取新聞url點選次數
2 def getClickUrl(url):
3 res2 = requests.get(url)
4 return int(re.findall(r"\$\('#hits'\).html\('(\d+)", res2.text)[0])
5
6 # 擷取新聞釋出時間及類型轉換
7 def getNewTime(url):
8 res = requests.get(url)
9 print(res.encoding)
10 res.encoding = 'utf-8'
11
12 soup = BeautifulSoup(res.text, 'html.parser')
13
14 info = soup.select('.show-info')[0].text
15 info = info.split("\xa0\xa0")
16 for i in info:
17 if (':' in i):
18 temp = i.split("釋出時間:")
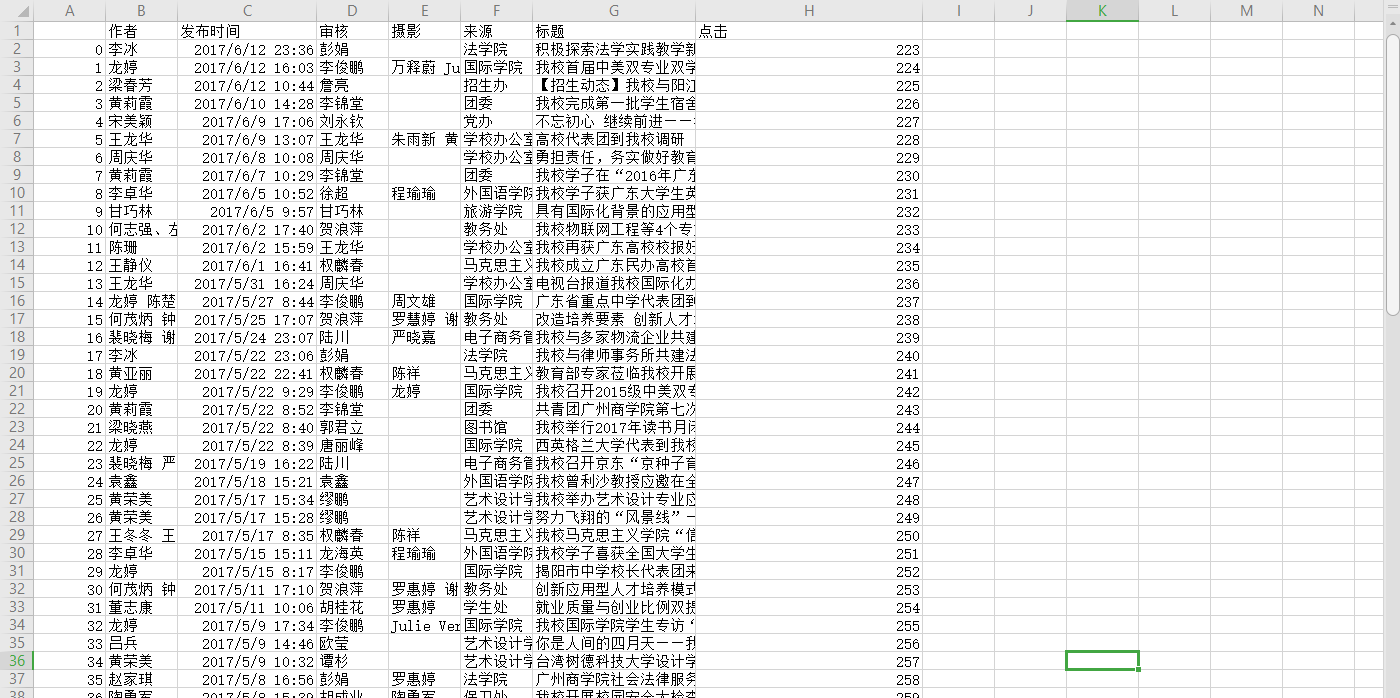
19 return datetime.datetime.strptime(temp[1], "%Y-%m-%d %H:%M:%S ") 1.從新聞url擷取新聞詳情: 字典,anews
2.從清單頁的url擷取新聞url:清單append(字典) alist
3.生成所頁清單頁的url并擷取全部新聞 :清單extend(清單) allnews
*每個同學爬學号尾數開始的10個清單頁
4.設定合理的爬取間隔
import time
import random
time.sleep(random.random()*3)
5.用pandas做簡單的資料處理并儲存
儲存到csv或excel檔案
newsdf.to_csv(r'F:\duym\爬蟲\gzccnews.csv')
1 def getNewList(new_page):
2 new_list = []
3 response = requests.get(new_page)
4 response.encoding = 'utf-8'
5 resopnse = response.text
6 soup = BeautifulSoup(resopnse, 'html.parser')
7 new_list_html = soup.select(".news-list a")
8 for i in new_list_html:
9 new_list.append(i['href'])
10 return new_list
11
12 def getNewInfo(url):
13 res = requests.get(url)
14 print(res.encoding)
15 res.encoding = 'utf-8'
16
17 soup = BeautifulSoup(res.text, 'html.parser')
18
19 info = soup.select('.show-info')[0].text
20 info = info.split("\xa0\xa0")
21 dict = {"作者": '', "标題": '', "釋出時間": '', "來源": '', "點選": 0}
22 for i in info:
23 if (':' in i):
24 temp = i.split("釋出時間:")
25 dict["釋出時間"] = temp[1]
26 # print(temp)
27 temp = {}
28 if (':' in i):
29 temp = i.split(":")
30 dict[temp[0]] = temp[1]
31 # print(temp)
32 temp = {}
33
34 # 擷取點選次數
35 url2 = "http://oa.gzcc.cn/api.php?op=count&id=11094&modelid=80"
36 res2 = requests.get(url2)
37 # print(res2.text)
38 # print (re.findall(r"\$\('#hits'\).html\('(\d+)",res2.text))
39 dict['點選'] = int(re.findall(r"\$\('#hits'\).html\('(\d+)", res2.text)[0])
40
41 # 時間轉換
42 dict["釋出時間"] = datetime.datetime.strptime(dict["釋出時間"], "%Y-%m-%d %H:%M:%S ")
43 print("釋出時間類型為", type(dict["釋出時間"]))
44 # 擷取标題
45 title = soup.select(".show-title")[0].text
46 dict["标題"] = title
47 return dict
48
49 url = r'http://news.gzcc.cn/html/xiaoyuanxinwen/'
50 allNews = []
51 for i in range(44, 54):
52 new_page = url + str(i) + r'.html'
53 new_list = getNewList(new_page)
54 for new_url in new_list:
55 allNews.append(getNewInfo(new_url))
56 time.sleep(random.random() * 3)
57 news = DataFrame(allNews)
58 news.to_csv(r'newsInfo.csv') 運作效果圖如下: