寫法不一樣而功能完全相同的兩條 SQL 的在性能方面的差異。
示例一
需求:取出某個 group(假設 id 為 100)下的使用者編号(id),使用者昵稱(nick_name)、使用者性别
( sexuality ) 、 用 戶 簽 名 ( sign ) 和 用 戶 生 日 ( birthday ) , 并 按 照 加 入 組 的 時 間
(user_group.gmt_create)來進行倒序排列,取出前 20 個。
解決方案一、
SELECT id,nick_name
FROM user,user_group
WHERE user_group.group_id = 1
and user_group.user_id = user.id
limit 100,20;
解決方案二、
SELECT user.id,user.nick_name
FROM (
SELECT user_id
FROM user_group
ORDER BY gmt_create desc
limit 100,20) t,user
WHERE t.user_id = user.id;
我們先來看看執行計劃:
sky@localhost : example 10:32:13> explain
-> SELECT id,nick_name
-> FROM user,user_group
-> WHERE user_group.group_id = 1
-> and user_group.user_id = user.id
-> ORDER BY user_group.gmt_create desc
-> limit 100,20\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_group
type: ref
possible_keys: user_group_uid_gid_ind,user_group_gid_ind
key: user_group_gid_ind
key_len: 4
ref: const
rows: 31156
Extra: Using where; Using filesort
*************************** 2. row ***************************
table: user
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
ref: example.user_group.user_id
rows: 1
Extra:
sky@localhost : example 10:32:20> explain
-> SELECT user.id,user.nick_name
-> FROM (
-> SELECT user_id
-> FROM user_group
-> ORDER BY gmt_create desc
-> limit 100,20) t,user
-> WHERE t.user_id = user.id\G
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 20
ref: t.user_id
*************************** 3. row ***************************
id: 2
select_type: DERIVED
possible_keys: user_group_gid_ind
Extra: Using filesort
執行計劃對比分析:
解決方案一中的執行計劃顯示 MySQL 在對兩個參與 Join 的表都利用到了索引,user_group 表利用了
user_group_gid_ind 索 引 ( key: user_group_gid_ind ) , user 表 利 用 到 了 主 鍵 索 引 ( key:
PRIMARY),在參與 Join 前 MySQL 通過 Where 過濾後的結果集與 user 表進行 Join,最後通過排序取出
Join 後結果的“limit 100,20”條結果傳回。
解決方案二的 SQL 語句利用到了子查詢,是以執行計劃會稍微複雜一些,首先可以看到兩個表都和
解決方案 1 一樣都利用到了索引(所使用的索引也完全一樣),執行計劃顯示該子查詢以 user_group 為
驅動,也就是先通過 user_group 進行過濾并馬上進行這一論的結果集排序,也就取得了 SQL 中的
“limit 100,20”條結果,然後與 user 表進行 Join,得到相應的資料。這裡可能有人會懷疑在自查詢中
從 user_group 表所取得與 user 表參與 Join 的記錄條數并不是 20 條,而是整個 group_id=1 的所有結果。
那麼清大家看看該執行計劃中的第一行,該行内容就充分說明了在外層查詢中的所有的 20 條記錄全部被
傳回。
通過比較兩個解決方案的執行計劃,我們可以看到第一中解決方案中需要和 user 表參與 Join 的記錄
數 MySQL 通過統計資料估算出來是 31156,也就是通過 user_group 表傳回的所有滿足 group_id=1 的記錄
數(系統中的實際資料是 20000)。而第二種解決方案的執行計劃中,user 表參與 Join 的資料就隻有 20
條,兩者相差很大,通過本節最初的分析,我們認為第二中解決方案應該明顯優于第一種解決方案。
下面我們通過對比兩個解決覺方案的 SQL 實際執行的 profile 詳細資訊,來驗證我們上面的判斷。由
于 SQL 語句執行所消耗的最大兩部分資源就是 IO 和 CPU,是以這裡為了節約篇幅,僅列出 BLOCK IO 和 CPU
兩項 profile 資訊(Query Profiler 的詳細介紹将在後面章節中獨立介紹):
先打開 profiling 功能,然後分别執行兩個解決方案的 SQL 語句:
sky@localhost : example 10:46:43> set profiling = 1;
Query OK, 0 rows affected (0.00 sec)
sky@localhost : example 10:46:50> SELECT id,nick_name
-> limit 100,20;
+--------+-----------+
| id | nick_name |
| 990101 | 990101 |
| 990102 | 990102 |
| 990103 | 990103 |
| 990104 | 990104 |
| 990105 | 990105 |
| 990106 | 990106 |
| 990107 | 990107 |
| 990108 | 990108 |
| 990109 | 990109 |
| 990110 | 990110 |
| 990111 | 990111 |
| 990112 | 990112 |
| 990113 | 990113 |
| 990114 | 990114 |
| 990115 | 990115 |
| 990116 | 990116 |
| 990117 | 990117 |
| 990118 | 990118 |
| 990119 | 990119 |
| 990120 | 990120 |
20 rows in set (1.02 sec)
sky@localhost : example 10:46:58> SELECT user.id,user.nick_name
-> WHERE t.user_id = user.id;
20 rows in set (0.96 sec)
檢視系統中的 profile 資訊,剛剛執行的兩個 SQL 語句的執行 profile 資訊已經記錄下來了:
sky@localhost : example 10:47:07> show profiles\G
Query_ID: 1
Duration: 1.02367600
Query: SELECT id,nick_name
ORDER BY user_group.gmt_create desc
limit 100,20
Query_ID: 2
Duration: 0.96327800
Query: SELECT user.id,user.nick_name
WHERE t.user_id = user.id
2 rows in set (0.00 sec)
sky@localhost : example 10:47:34> SHOW profile CPU,BLOCK IO io FOR query 1;
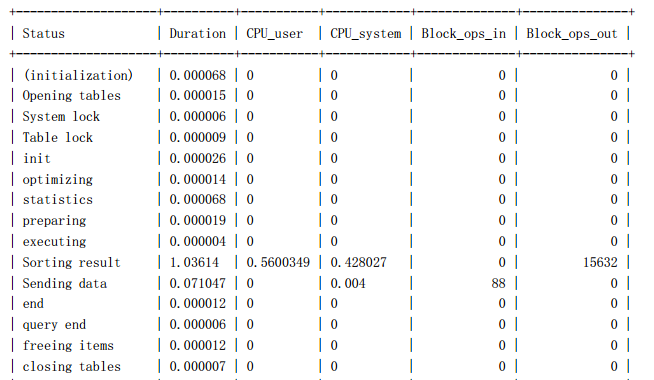
16 rows in set (0.00 sec)
sky@localhost : example 10:47:40> SHOW profile CPU,BLOCK IO io FOR query 2;

我們先看看兩條 SQL 執行中的 IO 消耗,兩者差別就在于“Sorting result”,我們回
顧一下前面執行計劃的對比,兩個解決方案的排序過濾資料的時機不一樣,排序後需要取
得的資料量一個是 20000,一個是 20,正好和這裡的 profile 資訊吻合,第一種解決方案的
“Sorting result”的 IO 值是第二種解決方案的将近 500 倍。
然後再來看看 CPU 消耗,所有消耗中,消耗最大的也是“Sorting result”這一項,第
一個消耗多出的緣由和上面 IO 消耗差異是一樣的。
結論:
通過上面兩條功能完全相同的 SQL 語句的執行計劃分析,以及通過實際執行後的
profile 資料的驗證,都證明了第二種解決方案優于第一種解決方案。