引言
前面我們已經介紹了 Kubernetes 的各方面實作方案,但是網絡這塊比較複雜,是以我們這裡單獨用來進行介紹,網絡部分主要分 5 個部分,即 Pod 網絡,Service 網絡,外網通訊、LoadBalance、Ingress,本文介紹其中的第一個部分 Pod 網絡,更多關于 Kubernetes 的介紹均收錄于
<Kubernetes系列文章>中。
網絡原理
作為拓展,這裡我們以 flannel 為例展開介紹一下 Kubernetes 内網絡通訊的實作。在介紹之前,我們得先明确 Kubernetes 中的三種網絡的概念:
- node network:承載 kubernetes 叢集中各個“實體”Node(master 和 worker)通信的網絡
- service network:由 kubernetes 叢集中的 Services 所組成的“網絡”,它的範圍在啟動叢集的時候進行了配置
- flannel network:即 Pod 網絡,叢集中承載各個 Pod 互相通信的網絡,它的範圍在啟動叢集和啟動網絡插件的時候進行了配置
node network 自不必多說,node 間通過其區域網路(無論是實體的還是虛拟的)通信。
Pod 網絡
pod 網絡即 flannel network 是我們要了解的重點,cluster 中各個 Pod 要實作互相通信,必須走這個網絡,無論是在同一 node 上的 Pod 還是跨 node 的 Pod。這裡以我的叢集為例,介紹 flannel 的網絡結構。
預設情況下,每個節點會從 PodSubnet 中注冊一個掩碼長度為 24 的子網,然後該節點的所有 pod ip 位址都會從該子網中配置設定。當 flannel 啟動成功後,會在主控端上生成一個描述子網環境的檔案,該檔案中記錄了所有 pod 的子網範圍(FLANNEL_NETWORK)以及本機 pod 的子網範圍(FLANNEL_SUBNET):
cat /run/flannel/subnet.env
# 檔案内容如下
#FLANNEL_NETWORK=192.168.128.0/18
#FLANNEL_SUBNET=192.168.132.1/24
#FLANNEL_MTU=1450
#FLANNEL_IPMASQ=true 當叢集内的每個機器配置設定好屬于自己的 pod subnet 域後,會在自己的網絡裝置中新增一個名為
flannel.1
的類型為 vxlan 的網絡裝置:
ip -d link show
#eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
# link/ether fa:16:3f:56:85:66 brd ff:ff:ff:ff:ff:ff promiscuity 0 addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
#flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
# link/ether 86:4f:51:1e:bb:38 brd ff:ff:ff:ff:ff:ff promiscuity 0
# vxlan id 1 local 10.231.209.117 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
#cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000
# link/ether 4e:a6:bb:c7:b9:d7 brd ff:ff:ff:ff:ff:ff promiscuity 0
# bridge forward_delay 1500 hello_time 200 max_age 2000 ageing_time 30000 stp_state 0 priority 32768 vlan_filtering 0 vlan_protocol 802.1Q bridge_id 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 root_port 0 root_path_cost 0 topology_change 0 topology_change_detected 0 hello_timer 0.00 tcn_timer 0.00 topology_change_timer 0.00 gc_timer 121.78 vlan_default_pvid 1 vlan_stats_enabled 0 group_fwd_mask 0 group_address 01:80:c2:00:00:00 mcast_snooping 1 mcast_router 1 mcast_query_use_ifaddr 0 mcast_querier 0 mcast_hash_elasticity 4 mcast_hash_max 512 mcast_last_member_count 2 mcast_startup_query_count 2 mcast_last_member_interval 100 mcast_membership_interval 26000 mcast_querier_interval 25500 mcast_query_interval 12500 mcast_query_response_interval 1000 mcast_startup_query_interval 3125 mcast_stats_enabled 0 mcast_igmp_version 2 mcast_mld_version 1 nf_call_iptables 0 nf_call_ip6tables 0 nf_call_arptables 0 addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
#veth65d142e7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
# link/ether 3e:86:a0:c8:f7:ca brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1
# veth
# bridge_slave state forwarding priority 32 cost 2 hairpin on guard off root_block off fastleave off learning on flood on port_id 0x8001 port_no 0x1 designated_port 32769 designated_cost 0 designated_bridge 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 從 flannel.1 的裝置資訊來看,它似乎與 eth0 存在着某種 bind 關系,而 eth0 則是主控端上的原始網絡。這是在其他 bridge、veth 裝置描述資訊中所沒有的。此外我們還可以看出 veth 裝置是 cni0 的 bridge_slave。然後我們着重看一下 Kubernetes 各個網卡的 ip。
ip -d addr show
#flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
# link/ether 86:4f:51:1e:bb:38 brd ff:ff:ff:ff:ff:ff promiscuity 0
# vxlan id 1 local 10.231.209.117 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# inet 192.168.132.0/32 scope global flannel.1
# valid_lft forever preferred_lft forever
#cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
# link/ether 4e:a6:bb:c7:b9:d7 brd ff:ff:ff:ff:ff:ff promiscuity 0
# bridge forward_delay 1500 hello_time 200 max_age 2000 ageing_time 30000 stp_state 0 priority 32768 vlan_filtering 0 vlan_protocol 802.1Q bridge_id 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 root_port 0 root_path_cost 0 topology_change 0 topology_change_detected 0 hello_timer 0.00 tcn_timer 0.00 topology_change_timer 0.00 gc_timer 226.02 vlan_default_pvid 1 vlan_stats_enabled 0 group_fwd_mask 0 group_address 01:80:c2:00:00:00 mcast_snooping 1 mcast_router 1 mcast_query_use_ifaddr 0 mcast_querier 0 mcast_hash_elasticity 4 mcast_hash_max 512 mcast_last_member_count 2 mcast_startup_query_count 2 mcast_last_member_interval 100 mcast_membership_interval 26000 mcast_querier_interval 25500 mcast_query_interval 12500 mcast_query_response_interval 1000 mcast_startup_query_interval 3125 mcast_stats_enabled 0 mcast_igmp_version 2 mcast_mld_version 1 nf_call_iptables 0 nf_call_ip6tables 0 nf_call_arptables 0 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# inet 192.168.132.1/24 scope global cni0
# valid_lft forever preferred_lft forever
#veth65d142e7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
# link/ether 3e:86:a0:c8:f7:ca brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1
# veth
# bridge_slave state forwarding priority 32 cost 2 hairpin on guard off root_block off fastleave off learning on flood on port_id 0x8001 port_no 0x1 designated_port 32769 designated_cost 0 designated_bridge 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 可以看到 flannel.1 和 cni0 的 ip 和該主控端被配置設定的 FLANNEL_SUBNET 的 ip 範圍一緻。然後,我們再看一看該主機上的路由表:
ip route
#default via <local network gateway> dev eth0 metric 10
#<local subnet> dev eth0 proto kernel scope link src <local ip>
#192.168.128.0/24 via 192.168.128.0 dev flannel.1 onlink
#192.168.129.0/24 via 192.168.129.0 dev flannel.1 onlink
#192.168.130.0/24 via 192.168.130.0 dev flannel.1 onlink
#192.168.131.0/24 via 192.168.131.0 dev flannel.1 onlink
#192.168.132.0/24 dev cni0 proto kernel scope link src 192.168.132.1
#192.168.133.0/24 via 192.168.133.0 dev flannel.1 onlink 路由表顯示,當要發送給自己的 pod 子網時(192.168.132.0/24),會通過 cni0 網卡,而當要發送其他主控端的 pod 時,會通過 flannel.1 網卡。到這裡,我們總結一下已經得到的情報,Kubernetes 目前通過 flannel.1 和 cni0 兩個網卡來完成 pod 子網的通訊,flannel.1 負責本機 Pod 與其他主控端 Pod 之間的通訊,cni0 負責本機内 Pod 間的通訊。那麼還有兩個疑問:1. cni0 又是怎麼連通 docker 内容器的?2. flannel.1 是怎麼連通其他主控端的? 我們知道 Pod 内的程序都是跑在 Docker 容器裡的,為了探究 cni0 的工作原理,我們就得深入調查一下 Docker 容器使用的網絡結構。
# e1adc507e8bc 是 kubia 服務的容器
docker exec -it e1adc507e8bc ip route
#default via 192.168.132.1 dev eth0
#192.168.128.0/18 via 192.168.132.1 dev eth0
#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.73
docker exec -it e1adc507e8bc ip -d link show
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity 0
#3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
# link/ether 3e:43:3e:1f:48:a1 brd ff:ff:ff:ff:ff:ff promiscuity 0
# veth
docker exec -it e1adc507e8bc ip -d addr show
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
#3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
# link/ether 3e:43:3e:1f:48:a1 brd ff:ff:ff:ff:ff:ff
# inet 192.168.132.73/24 scope global eth0
# valid_lft forever preferred_lft forever
# inet6 fe80::3c43:3eff:fe1f:48a1/64 scope link
# valid_lft forever preferred_lft forever 我們在 kubia 服務的 docker 容器中,可以看到 docker 内部的網絡也已經是主控端配置設定的 pod 子網 192.168.132.0/24,它的 ip 是 192.168.132.73,mac 位址是 3e:43:3e:1f:48:a1,而且所有 pod 網段的資料包都是通過 eth0 網卡發送的。那麼 docker 容器内的 eth0 網卡的資料是怎麼發送到主控端的呢?我們不妨來看一下該 Pod 的 pause 容器配置,因為網絡的設定都在 pause 中完成,其他 pod 内容器都是複用 pause 容器的網絡。
# 12e3a9c720d7 是 kubia pod 的 pause 容器
docker inspect 12e3a9c720d7
# 從 NetworkSettings 中我們可以獲得如下資訊
#"NetworkID": "33fd5df9316947f37e388d49b121d47c589d7a2510b7bf055d6d55e0e57c75c8"
#"EndpointID": "106924f59a8d74db3f8045ac40feb9c9aa5b0ad0b320fadd344496eec39ff107" 然後我們再看一下 docker 中如何定義網絡 33fd5df93。
docker network inspect 33fd5df93 很奇怪,在該網絡的描述中并沒有像 docker0 網橋那樣顯式地聲明自己是網橋類型("Driver": "bridge")。
[
{
"Name": "bridge",
"Id": "2cb95162f702d9f36620f95d61cba76055eeedc3791761209329eab37ef90235",
"Created": "2019-09-25T20:04:07.55834704+09:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
] 相反的,這裡 Kubernetes 使用了null 驅動("Driver": "null")。
[
{
"Name": "none",
"Id": "33fd5df9316947f37e388d49b121d47c589d7a2510b7bf055d6d55e0e57c75c8",
"Created": "2019-09-25T15:56:05.76660028+09:00",
"Scope": "local",
"Driver": "null",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": []
},
"Internal": false,
"Attachable": false,
"Containers": {
"12e3a9c720d72a41e829aeaa3e310436e1b9e33e1a7f8578b065506b64cb9b49": {
"Name": "k8s_POD_kubia-24hmb_default_3586fce7-a27c-4955-9c74-8bd1bb2b9171_0",
"EndpointID": "106924f59a8d74db3f8045ac40feb9c9aa5b0ad0b320fadd344496eec39ff107",
"MacAddress": "",
"IPv4Address": "",
"IPv6Address": ""
},
"598b6a4eeba4ae11ecfb2f07603bda106ade78acfea6776bb1aad624edc2d850": {
"Name": "k8s_POD_kubia-rpr99_default_a628f355-75c4-4d4b-a637-a81e3b30a156_0",
"EndpointID": "dfe139b8af4391507ed411d813200adbe7a3d9f30ab78e4682025e24afa30fec",
"MacAddress": "",
"IPv4Address": "",
"IPv6Address": ""
},
"e7e15a5df3880d22a2ca4b254f959346d487c5b8869af0448989a73f518cb553": {
"Name": "k8s_POD_coredns-5644d7b6d9-v56sk_kube-system_53751e33-88d8-4ab0-a831-a4fdf04c3fae_0",
"EndpointID": "5232bea08ee84f86ed5b6489743061377766d495139ff9e42b7e21d110d23d65",
"MacAddress": "",
"IPv4Address": "",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
] bridge 驅動,預設模式,即 docker0 網橋模式。此驅動為 docker 的預設設定,使用這個驅動的時候,libnetwork 将建立出的 Docker 容器連接配接到 Docker 網橋上。作為最正常的模式,bridge 模式已經可以滿足 Docker 容器最基本的使用需求了。然而其與外界通信使用 NAT,增加了通信的複雜性,在複雜場景下使用會有諸多限制。
null 驅動使用這種驅動的時候,Docker 容器擁有自己的 network namespace,但是并不需要 Docker 容器進行任何網絡配置。也就是說,這個 Docker 容器除了 network namespace 自帶的 loopback 網卡外,沒有其他任何網卡、IP、路由等資訊,需要使用者為 Docker 容器添加網卡、配置 IP 等。這種模式如果不進行特定的配置是無法正常使用的,但是優點也非常明顯,給了使用者最大的自由度來自定義容器的網絡環境。
這麼看來,每個 pod 中的網絡空間應該是獨立的,Kubernetes 建立好容器後手動向 docker 容器的 network 命名空間中加網卡,進而連通到主控端的 cni0 網橋的。
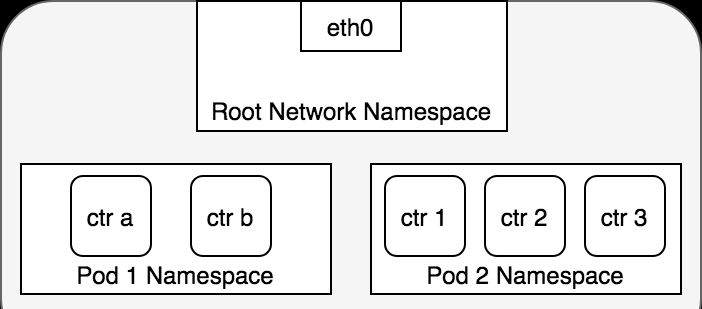
那麼它又是怎麼做到的呢?為了複現 Kubernetes 管理容器網絡的方案,我建立了一個新的容器,并且同樣使用前面用到的 kubia 鏡像。同時,我們也使用 Kubernetes 的 null Driver 網絡。
docker create --network 33fd5df931694 beikejiedeliulangmao/kubia
# 确認一下容器内的網卡情況,發現确實隻有 loopback
docker exec -it 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever 然後,我們使用 Kubernetes 的 cni0 網橋,連通容器和主控端,具體怎麼做呢?第一步,我們先将容器内的網絡空間共享出來,讓主控端可以操作。
# 檢視容器的 pid
docker inspect 8ef9475b6d6e|grep Pid
# "Pid": 68791
# 建立網絡命名空間目錄,後面操作網絡空間時都會基于此目錄存儲的内容
mkdir /var/run/netns
# 根據 pid 得到容器的網絡空間,然後通過軟連接配接的方式共享到主控端空間
ln -s /proc/68791/ns/net /var/run/netns/8ef9475b6d6e
# 确認網絡空間是否出現
ip netns list
# 然後檢視網絡空間的内容
ip netns exec 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever 到這為止,我們就可以在主控端中,看到 docker 容器的網絡空間内容了,接下來是第二步,基于 Kubernetes 的 cni0 網橋連通主控端和建立的容器。
# 我們先看一下網橋的名字
brctl show
#bridge name bridge id STP enabled interfaces
#cni0 8000.4ea6bbc7b9d7 no veth0bcd3dfd
# veth65d142e7
# veth9e1cec0c
# 如果您想自己建立一個新的網橋的話可以通過如下指令:
#brctl addbr newBridge
#ip addr add x.x.x.x/x dev newBridge
#ip link set dev newBridge up
# 這裡我們直接使用 Kubernetes 的 cni0 網橋,然後建立一個連接配接對端 peer
ip link add veth123 type veth peer name veth456
# 将 veth123 插到主控端的 cni0 網橋上
brctl addif cni0 veth123
ip link set veth123 up
brctl show
#bridge name bridge id STP enabled interfaces
#cni0 8000.4ea6bbc7b9d7 no veth0bcd3dfd
# veth65d142e7
# veth9e1cec0c
# veth123
# 将 veth456 放入容器的網絡空間後,容器中就能看到該網絡裝置,而主控端中就看不到了
ip link set veth456 netns 8ef9475b6d6e
ip netns exec 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
#13: veth456@if14: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
# link/ether ae:17:f4:64:63:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 我們也将容器中的網卡重命名為 eth0,啟動後再為其配置設定一個 ip 位址
ip netns exec 8ef9475b6d6e ip link set veth456 name eth0
ip netns exec 8ef9475b6d6e ip link set eth0 up
ip netns exec 8ef9475b6d6e ip addr add 192.168.132.150/24 dev eth0
ip netns exec 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
#13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
# link/ether ae:17:f4:64:63:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# inet 192.168.132.150/24 scope global eth0
# valid_lft forever preferred_lft forever
# inet6 fe80::ac17:f4ff:fe64:6305/64 scope link
# valid_lft forever preferred_lft forever
# 是不是網絡裝置的資訊已經和 Kubernetes 的容器内網絡資訊一樣了
ip netns exec 8ef9475b6d6e ip route
#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150
# 然後我們在主控端 ping 一下該主機
ping 192.168.132.150
#PING 192.168.132.150 (192.168.132.150) 56(84) bytes of data.
#64 bytes from 192.168.132.150: icmp_seq=1 ttl=64 time=0.210 ms
#64 bytes from 192.168.132.150: icmp_seq=2 ttl=64 time=0.094 ms 現在,我們建立的容器已經能和主控端連通了,但是還不能 ping 通其他網絡裝置,是以我們給其加一個預設路由,就像 Pod 容器中一樣。
ip netns exec 8ef9475b6d6e ip route add default via 192.168.132.1
ip netns exec 8ef9475b6d6e ip route add 192.168.128.0/18 via 192.168.132.1
ip netns exec 8ef9475b6d6e ip route
#ip netns exec 8ef9475b6d6e ip route
#default via 192.168.132.1 dev eth0
#192.168.128.0/18 via 192.168.132.1 dev eth0
#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150
ip netns exec 8ef9475b6d6e ping 192.168.132.73
ip netns exec 8ef9475b6d6e curl 192.168.132.73:8080
ip netns exec 8ef9475b6d6e ping 172.17.0.2
ip netns exec 8ef9475b6d6e curl google.com
ip netns exec 8ef9475b6d6e ping google.com 現在我們的容器網絡不光能連通 pod 的網絡,還能連通其他段(172.17.0.1)的網絡啦。這裡大家可能會有一個疑問,為什麼我能 curl 連通 google.com,但是 ping 卻不行呢?因為在主控端上對 tcp 做了 SNAT,而 ping 使用的 icmp 則沒有做 SNAT,這就導緻從我們建立的網絡中發出去的 icmp 包有去無回。

圖中的 cbr0 實際上就是 cni0 網橋的别名。在 Kubernetes 的 cni 中預設将網絡命名為 cbr0,您可以在中看到 Kubernetes 配置設定的所有位址,以及每個位址對應的容器 id(ip 位址作為檔案名),而在/var/lib/cni/networks/cbr0
中存儲了每個容器對應的網橋和插在網橋上的對端網絡裝置。/var/lib/cni/cache/results
好了,我們終于解決了第一個問題:cni0 裝置是如何連通 docker 容器,并讓容器間的網絡互通的。不同容器間的通訊是通過直聯網絡,實質上 cni0 在網絡中的第二層(資料鍊路層)運轉,這裡以我們建立的容器和 pod 容器之間的通訊為例。當我們在建立的容器中 ping pod 容器,根據路由表,将比對到
192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150
,即無需 gateway 轉發便可以直接将資料包送達。ARP 查詢後(要麼從 arp cache 中找到,要麼在 cni0 這個二層交換機中泛洪查詢)獲得 192.168.132.73 的 mac 位址。ip 包的目的 ip 填寫 192.168.132.73,二層資料幀封包将目的 mac 填寫為剛剛查到的 mac 位址,通過 eth0(192.168.132.150)發送出去。eth0 實際上是一個 veth pair,另外一端“插”在 cni0 這個交換機上,是以這一過程就是一個标準的二層交換機的資料封包交換過程, cni0 相當于從交換機上的一個端口收到以太幀資料,并将資料從另外一個端口發出去。隻有當在 pod 中通路 localhost,127.0.0.1,或者自己的 ip 時,資料幀隻會和容器内的 eth0 互動。
泛洪查詢:交換機根據收到資料幀中的源MAC位址建立該位址同交換機端口的映射,并将其寫入 MAC 位址表中。交換機将資料幀中的目的 MAC 位址同已建立的 MAC 位址表進行比較,以決定由哪個端口進行轉發。如資料幀中的目的 MAC 位址不在 MAC 位址表中,則向所有端口轉發。當任意節點回應了該資料幀,就将該節點的 MAC 位址和上述 IP 綁定,存在 MAC 表中。
而如果我是在剛才的容器中 ping 了其他網段的位址 比如 docker的預設網橋 docker0
172.17.0.2
。當 ping 執行後,根據容器路由表,沒有比對到直連網絡,隻能通過 default 路由将資料包發給Gateway: 192.168.132.1。雖然都是 cni0 接收資料,但這次更類似于“資料被直接發到 Bridge 上(因為橋的 ip 就是 192.168.132.1),而不是 Bridge 從一個端口接收轉發給另一個端口”。二層的目的 mac 位址填寫的是 gateway 192.168.132.1 自己的 mac 位址(cni0 Bridge的mac位址),此時的 cni0 更像是一塊普通網卡的角色,工作在三層(網絡層)。cni0 收到資料包後,發現并非是發給自己的 ip 包,通過主機路由表找到直連鍊路路由,cni0 将資料包 Forward 到 docker0 上(封裝的二層資料包的目的 MAC 位址為 docker0 的 mac 位址)。此時的 docker0 也是一種“網卡”的角色,由于目的 ip 依然不是 docker0 自身,是以 docker0 也會繼續這一轉發流程。通過 traceroute 可以印證這一過程:
ip netns exec 8ef9475b6d6e traceroute 172.17.0.2
#traceroute to 172.17.0.2 (172.17.0.2), 30 hops max, 60 byte packets
# 1 192.168.132.1 0.124 ms 0.053 ms 0.030 ms
# 2 172.17.0.1 3005.955 ms !H 3005.909 ms !H 3005.875 ms !H 現在,我們開始探索第二個問題,flannel.1 網絡裝置如何連通不同主機之間的 pod。通過前面的 docker0 例子中,我們知道 pod 中的資料幀如何通過主控端的路由轉發到其他網絡裝置,現在我們假設要發請求給另一個主控端上的 pod(192.168.128.10),這時候會比對到
192.168.128.0/24 via 192.168.128.0 dev flannel.1 onlink
。因為本機 flannel.1 網絡裝置的 ip(192.168.132.0) 并不是目标位址(192.168.128.10),是以資料幀到達 flannel.1 之後也是要發出去。資料包沿着網絡協定棧向下流動,在二層時需要封二層以太包,填寫目的 mac 位址,這時一般應該發出 ARP:”who is 192.168.128.10″,但是要記住 flannel.1 是一個 vxlan 裝置,因為該類裝置的特殊性,他并不會真正的在第二層發送這個 ARP 包,而是由 linux kernel 引發一個 ”L2 MISS” 事件并将 ARP 請求發到使用者空間的 flannel 程式。flannel 程式收到 ”L2 MISS” 核心事件以及 ARP 請求(who is 192.168.128.10)後,并不會向外網發送 ARP request,而是嘗試從 etcd 查找該位址比對的子網的 VtepMAC 資訊,該資訊目前存在
/registry/minions/<host_name>
。
VxLan: 全稱是 Virtual eXtensible Local Area Network,虛拟可擴充的區域網路。它是一種 overlay 技術,通過三層的網絡來搭建虛拟的二層網絡, 隻要是三層可達(能夠通過 IP 互相通信)的網絡就能部署 vxlan。接下來的執行個體中,您會清晰地了解到 VxLan 如何工作。
接下來,flannel 将查詢到的資訊放入主控端的 ARP cache表中:
ip n |grep 192.168
#192.168.132.100 dev cni0 lladdr 7a:cf:98:ce:4b:cc STALE
#192.168.132.70 dev cni0 lladdr 12:4a:7a:31:5b:d7 REACHABLE
#192.168.132.150 dev cni0 lladdr ae:17:f4:64:63:05 STALE
#192.168.132.73 dev cni0 lladdr 3e:43:3e:1f:48:a1 STALE
#192.168.133.0 dev flannel.1 lladdr 02:4e:1e:94:98:20 PERMANENT
#192.168.132.69 dev cni0 lladdr ca:b7:e3:83:0d:3a STALE
#192.168.129.0 dev flannel.1 lladdr 7a:52:54:58:5f:4c PERMANENT
#192.168.128.0 dev flannel.1 lladdr 26:12:3f:ba:e9:f5 PERMANENT
#192.168.131.0 dev flannel.1 lladdr 62:6d:b4:f7:47:0b PERMANENT
#192.168.130.0 dev flannel.1 lladdr 56:d7:1a:70:7b:e0 PERMANENT
#192.168.132.72 dev cni0 lladdr f2:98:cd:7b:23:d9 STALE flannel 完成這項工作後,linux kernel 就可以在 ARP table 中找到 192.168.128.10 對應的子網基ip(192.168.128.0)的 mac 位址并封裝二層以太包了。
到目前為止,已經呈現在大家眼前的封包如下圖:
不過這個封包還不能在實體網絡上傳輸,因為它實際上隻是 vxlan tunnel 上的 packet。我們需要将上述的 packet 從本機傳輸到目标機器上,這就得再次封包。這個任務在 vxlan 的 flannel network 中由 linux kernel 來完成。
flannel.1 為 vxlan 裝置,linux kernel 可以自動識别,并将上面的 packet 進行 vxlan 封包處理。在這個封包過程中,kernel 需要知道該資料包究竟發到哪個 node 上去。kernel 需要檢視本機上的 fdb(forwarding database)以獲得上面對端 vtep 裝置(已經從 ARP table 中查到其mac位址:26:12:3f:ba:e9:f5)所在的 node 位址。如果 fdb 中沒有這個資訊,那麼 kernel 會向使用者空間的 flannel 程式發起”L3 MISS”事件。flannel 收到該事件後,會查詢 etcd,擷取該 vtep 裝置對應的 node 的 IP,并将資訊注冊到 fdb 中。
這樣 Kernel 就可以順利查詢到該資訊并封包了:
bridge fdb show dev flannel.1|grep 26:12:3f:ba:e9:f5
#26:12:3f:ba:e9:f5 dst <target node ip> self permanent 由于目标 ip 是對端 pod 所處主控端的 ip,查找路由表,包應該從本機的 eth0 發出,這樣 src ip 和 src mac 位址也就确定了。封好的包示意圖如下:
當對端主控端 eth0 接收到該 vxlan 封包後,kernel 将識别出這是一個 vxlan 包,于是拆包後将 flannel.1 packet 轉給自身的 vtep(flannel.1)。然後 flannel.1 再将這個資料包轉到自己的的 cni0,繼而由 cni0 傳輸到 Pod 的某個容器裡。
文章說明
更多有價值的文章均收錄于
貝貝貓的文章目錄 版權聲明: 本部落格所有文章除特别聲明外,均采用 BY-NC-SA 許可協定。轉載請注明出處!
創作聲明: 本文基于下列所有參考内容進行創作,其中可能涉及複制、修改或者轉換,圖檔均來自網絡,如有侵權請聯系我,我會第一時間進行删除。
參考内容
[1]
kubernetes GitHub 倉庫[2]
Kubernetes 官方首頁[3]
Kubernetes 官方 Demo[4] 《Kubernetes in Action》
[5]
了解Kubernetes網絡之Flannel網絡[6]
Kubernetes Handbook[7]
iptables概念介紹及相關操作[8]
iptables超全詳解[9]
了解Docker容器網絡之Linux Network Namespace[10]
A Guide to the Kubernetes Networking Model[11]
Kubernetes with Flannel — Understanding the Networking[12]
四層、七層負載均衡的差別