文|林育智(花名:源三 )
螞蟻集團進階專家 專注微服務/服務發現相關領域
校對|李旭東
本文 8624 字 閱讀 18 分鐘
|引 言|
服務發現是建構分布式系統的最重要的依賴之一, 在螞蟻集團承擔該職責的是注冊中心和 Antvip,其中注冊中心提供機房内的服務發現能力,Antvip 提供跨機房的服務發現能力。
本文讨論的重點是注冊中心和多叢集部署形态(IDC 次元),叢集和叢集之間不涉及到資料同步。
PART. 1 背 景
回顧注冊中心在螞蟻集團的演進,大概起始于 2007/2008 年,至今演進超過 13 年。時至今日,無論是業務形态還是自身的能力都發生了巨大的變化。
簡單回顧一下注冊中心的曆代發展:
V1:引進淘寶的 configserver
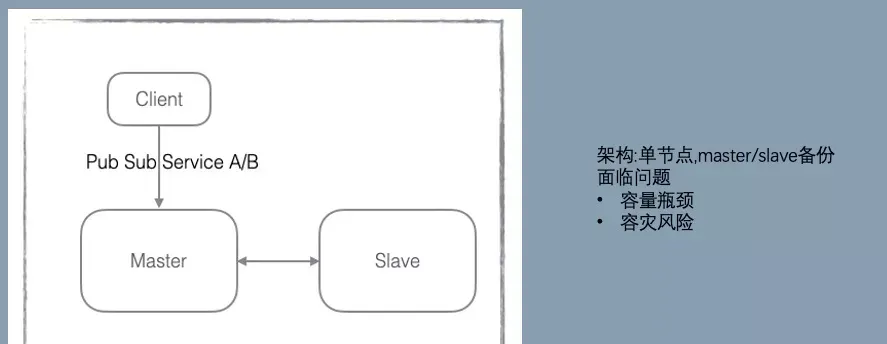
V2:橫向擴充

從這個版本開始,螞蟻和阿裡開始獨立的演進,最主要的差異點是在資料存儲的方向選擇上。螞蟻選擇了橫向擴充,資料分片存儲。阿裡選擇了縱向擴充,加大 data 節點的記憶體規格。
這個選擇影響到若幹年後的 SOFARegistry 和 Nacos 的存儲架構。
V3 / V4:LDC 支援和容災
V3 支援 LDC 單元化。
V4 增加了決策機制和運作時清單,解決了單機當機時需要人工介入處理的問題,一定程度上提升高可用和減少運維成本。
V5:SOFARegistry
前四個版本是 confreg,17 年啟動 V5 項目 SOFARegistry,目标是:
1.代碼可維護性:confreg 代碼曆史包袱較重
- 少量子產品使用 guice 做依賴管理,但大部分子產品是靜态類互動,不容易分離核心子產品和擴充子產品,不利于産品開源。
- 用戶端與服務端的互動模型嵌套複雜,了解成本極高且對多語言不友好。
2.運維痛點:引入 Raft 解決 serverlist 的維護問題,整個叢集的運維包括 Raft,通過 operator 來簡化。
3.魯棒性:在一緻性 hash 環增加多節點備份機制(預設 3 副本),2 副本當機業務無感。
4.跨叢集服務發現:站内跨叢集服務發現額外需要 antvip 支撐,希望可以統一 2 套設施的能力,同時商業化場景也有跨機房資料同步的需求。
這些目标部分實作了,部分實作的還不夠好,例如運維痛點還殘留一部分,跨叢集服務發現在面對主站的大規模資料下穩定性挑戰很大。
V6:SOFARegistry 6.0
2020 年 11 月,SOFARegistry 總結和吸收内部/商業化打磨的經驗,同時為了應對未來的挑戰,啟動了 6.0 版本大規模重構計劃。
曆時 10 個月,完成新版本的開發和更新工作,同時鋪開了應用級服務發現。
PART. 2 挑 戰
當下面臨的問題
叢集規模的挑戰
- 資料增長:随着業務的發展,業務的執行個體數在不斷增長,pub/sub 的數量也相應增長。以其中一個叢集為例,2019 年的資料為基準資料,在 2020 年 pub 接近千萬級。
下圖是該叢集曆年雙十一時的資料對比和切換應用級的優化效果。相比 2019 年雙十一,2021 年雙十一接口級的 pub 增長 200%,sub 增長 80%。
- 故障爆炸半徑增長:叢集接入的執行個體越多,故障影響的業務和執行個體數也就越多,保障業務的穩定是最基礎也是優先級最高的要求。
- 考驗橫向擴充能力:叢集達到一定的規模後,是否還具備繼續橫向擴充的能力,需要叢集具備良好的橫向擴充能力,從 10 擴到 100 和從 100 擴到 500 是不一樣的難度。
- HA 能力:叢集執行個體數多了後,面臨的節點總體的硬體故障率也相應增高,各種機器故障叢集是否能快速恢複?有運維經驗的同學都知道,運維一個小叢集和運維一個大叢集面臨的困難簡直是指數級增長。
- 推送性能:大多數服務發現的産品都選擇了資料的最終一緻性,但是這個最終在不同叢集的規模下到底是多久?相關的産品其實都沒有給出明确的資料。
但是實際上,我們認為這個名額是服務發現産品的核心名額。這個時長對調用有影響:新加的位址沒有流量;删除的位址沒有及時摘除等。螞蟻集團的 PaaS 對注冊中心的推送時延是有 SLO 限制的:如果變更推送清單延時超過約定值,業務端的位址清單就是錯誤的。我們曆史上也曾發生過因推送不及時導緻的故障。
業務執行個體規模增加的同時也帶來推送的性能壓力:釋出端 pub 下面的執行個體數增加;訂閱端業務執行個體數增加;一個簡單的估算,pub/sub 增長 2 倍,推送的資料量是 2*2,增長 4 倍,是一個乘積的關系。同時推送的性能也決定了同一時間可以支援的最大運維業務執行個體數,例如應急場景下,業務大規模重新開機。如果這個是瓶頸,就會影響故障的恢複時間。
叢集規模可以認為是最有挑戰性的,核心的架構決定了它的上限,确定後改造成本非常高。而且往往等到發現瓶頸的時候已經是兵臨城下了,我們要選擇能拉高産品技術天花闆的架構。
運維的挑戰
SOFARegistryX 立項時的一個主要目标是具備比 confreg 更好的運維能力:引入 meta 角色,通過 Raft 選舉和存儲元資訊,提供叢集的控制面能力。但是事實證明,我們還是低估了可運維的重要性,正如魯迅先生說:【程式員的工作隻有兩件事情,一件是運維,另一件還是運維】。
三年前的目标放到今天已經嚴重滞後了。
- 叢集數增長:螞蟻集團内部的業務是分站點部署的(簡單了解為每個站點是一塊相對比較獨立的業務,需要不同級别的隔離),同時一個站點需要部署多套叢集:容災需要分機房部署;開發需要分多環境。部署站點的數目增長超出我們的想像。現在已經達到數百個叢集了,還在迅速增長中,增長速度參考最近幾年美聯儲的貨币供應量增長速度。以前認為有些運維工作可以苟且,人肉頂一下,叢集數增長後,苟且次數太多了,擠占了開發/運維同學的精力,完全沒資源去規劃詩和遠方。
- 業務打擾:業務的運維是全天候 7*24 的,容量自适應/自愈/MOSN 每月一版本把全站應用犁一遍等等。下圖是每分鐘運維的機器批數,可以看到,就算是周末和深夜,運維任務也是不斷的。
螞蟻集團的同學對注冊中心的運維公告應該是比較熟悉和痛恨的。因為業務的敏感性,注冊中心之前一直是停機釋出和運維,這個時候需要鎖定全站的釋出/重新開機動作。為了盡量少影響業務,注冊中心相關的同學隻能獻祭一頭黑發,在深夜低峰期做相關的操作。即使這樣,仍然沒辦法做到對業務零打擾。
雲原生時代 naming 的挑戰
雲原生的技術時代下,可以觀察到一些趨勢:
- 微服務/FaaS 的推廣導緻輕型應用增多:執行個體數增多,需要能支撐更大的業務規模
- 應用執行個體的生命周期更短:FaaS 按需使用,autoscale 容量自适應等手段導緻執行個體的漲潮退潮更頻繁,注冊中心的性能主要展現在執行個體變更的響應速度上
- 多語言支援:在過去,螞蟻集團主要的開發體系是 Java,非 Java 語言對接基礎設施都是二等公民,随着 AI 和創新性業務的需求,非 Java 體系的場景越來越多。如果按照每種語言一個 SDK,維護成本會是個噩夢,當然 sidecar(MOSN)是個解法,但是自身是否能支援低侵入性的接入方式,甚至 sdk-free 的能力?
- 服務路由:在過去絕大部分的場景都可以認為 endpoint 是平等的,注冊中心隻提供通信的位址清單是可以滿足需求的。在 Mesh 的精确路由場景裡面,pilot 除了提供 eds(位址清單)也同時提供 rds(routing),注冊中心需豐富自身的能力。
- K8s:K8s 目前已經成為事實上的分布式作業系統,K8s-service 如何和注冊中心打通?更進一步,是否能解決 K8s-service 跨 multi-cluster 的問題?
「總結」
綜上,除了腳踏實地,解決當下的問題,還需要仰望星空。具備解決雲原生趨勢下的 naming 挑戰的可能性,也是 V6 重構的主要目标。
PART. 3 SOFARegistry 6.0:面向效能
SOFARegistry 6.0 不隻是一個注冊中心引擎,需要和周邊的設施配合,提升開發、運維、應急的效能,解決以下的問題。(紅色子產品是比較有挑戰性的領域)
SOFARegistry 6.0 相關的工作包括:
架構優化
架構的改造思路:在保留 V5 的存儲分片架構的同時,重點的目标是優化元資訊 meta 一緻性和確定推送正确的資料。
元資訊 meta 一緻性
V5 在 meta 角色中引入 Raft 的強一緻性進行選舉 leader 和存放元資訊,其中元資訊包括節點清單和配置資訊。資料的分片通過擷取 meta 的節點清單做一緻性 hash,這裡面存在兩個問題:
-
Raft/operator 運維複雜
(1)定制運維流程:需要支援 change peer 等編排。在螞蟻集團,特化的運維流程成本較高,同時也不利于輸出。
(2)實作一個生産健壯的 operator 成本非常高,包括接入變更管控 operator 自身的變更三闆斧等。
(3)對于網絡/磁盤的可用性比較敏感。在輸出的場景,會面臨比較惡劣的硬體情況,排查成本較高。
- 脆弱的強一緻性
meta 資訊的使用建立在滿足強一緻性的情況下,如果出現網絡問題,例如有 session 網絡分區連不上 meta,錯誤的路由表會導緻資料分裂。需要機制確定:即使 meta 資訊不一緻也能在短時間内維持資料的正确性,留有應急的緩沖時間。
推送正确的資料
當 data 節點大規模運維時,節點清單劇烈變化導緻資料不斷遷移,推送出去的資料存在完整性/正确性的風險。V5 通過引 3 副本來避免這種情況,隻要有一個副本可用,資料就是正确的,但是該限制對運維流程負擔很大,我們要確定每次操作少于兩個副本或者挑選出滿足限制的運維序列。
對于 V5 及之前的版本,運維操作是比較粗糙的,一刀切做停機釋出,通過鎖 PaaS 禁止業務變更,等 data 節點穩定後,再打開推送能力來確定避免推送錯誤資料的風險。
此外,預期的運維工作可以這樣做,但是對于突發的多 data 節點當機,這個風險仍然是存在的。
我們需要有機制確定:data 節點清單變化導緻資料遷移時,容忍接受額外的輕微推送時延,確定推送資料正确。
「成果」
- meta 存儲/選舉 元件插件化,站内去 Raft,使用 db 做 leader 選舉和存儲配置資訊,降低運維成本。
- 資料使用固定 slot 分片,meta 提供排程能力,slot 的排程資訊通過 slotTable 儲存,session/data 節點可容忍該資訊的弱一緻性,提升魯棒性。
- 多副本排程減少 data 節點變動時資料遷移的開銷,目前線上的資料量 follower 更新 leader 大概 200ms (follower 持有絕大部分的資料),直接配置設定 leader 資料同步耗時 2s-5s。
- 優化資料通信/複制鍊路,提升性能和擴充能力。
- 大規模運維不需要深夜鎖 PaaS,減少對業務打擾和保住運維人員頭發,提升幸福感。
資料鍊路和 slot 排程:
- slot 分片參考 Redis Cluster 的做法,采用虛拟哈希槽分區,所有的 dataId 根據哈希函數映射到 0 ~ N 整數槽内。
- meta 的 leader 節點,通過心跳感覺存活的 data 節點清單,盡可能均勻的把 slot 的多副本配置設定給 data 節點,相關的映射關系儲存在 slotTable,有變更後主動通知給 session/data。
- session/data 同時通過心跳擷取最新的 slotTable,避免 meta 通知失效的風險。
- slot 在 data 節點上有狀态機 Migrating -> Accept -> Moved。遷移時確定 slot 的資料是最新的才進入 Accept 狀态,才可以用于推送,確定推送資料的完整性。
data 節點變動的資料遷移:
對一個接入 10w+ client 的叢集進行推送能力壓測,分鐘級 12M 的推送量,推送延遲 p999 可以保持在 8s 以下。session cpu20%,data cpu10%,實體資源水位較低,還有較大的推送 buffer。
同時我們也線上上驗證橫向擴充能力,叢集嘗試最大擴容到 session370,data60,meta*3 ;meta 因為要處理所有的節點心跳,CPU 達到 50%,需要 8C 垂直擴容或者進一步優化心跳開銷。按照一個 data 節點的安全水位支撐 200w pub,一個 pub 大概 1.5K 開銷,考慮容忍 data 節點當機 1/3 仍然有服務能力,需要保留 pub 上漲的 buffer,該叢集可支撐 1.2 億的 pub,如果配置雙副本則可支撐 6kw 的 pub。
應用級服務發現
注冊中心對 pub 的格式保留很強的靈活性,部分 RPC 架構實作 RPC 服務發現時,采用一個接口一個 pub 的映射方式,SOFA/HSF/Dubbo2 都是采用這種模式,這種模型比較自然,但是會導緻 pub/sub 和推送量膨脹非常厲害。
Dubbo3 提出了應用級服務發現和相關原理【1】。在實作上,SOFARegistry 6.0 參考了 Dubbo3,采用在 session 端內建服務的中繼資料中心子產品的方案,同時在相容性上做了一些适配。
「應用級服務 pub 資料拆分」
「相容性」
應用級服務發現的一個難點是如何低成本的相容接口級/應用級,雖然最後大部分的應用都能更新到應用級,更新過程中會面臨以下問題:
- 應用數多,同時各個應用更新到應用級的時間點差距比較大
- 部分應用無法更新,例如一些遠古應用
我們采用以應用級服務為主,同時相容接口級的解決方案:
在更新時同時存在新舊版本的兩個 SOFARegistry,不同版本的 SOFARegistry 對應到不同的域名。更新後的應用端(圖中的 MOSN)采用雙訂閱雙釋出的方式逐漸灰階切換,確定切換過程中,沒有更新接入 MOSN 或者沒有打開開關的應用不受影響。
在完成絕大多數應用的應用級遷移後,更新後的應用都已經到了 SOFARegistry 6.0 版本的注冊中心上,但仍然存在少量應用因為沒有接入 MOSN,這些餘留的 old app 也通過域名切換到 SOFARegistry 6.0,繼續以接口級訂閱釋出和注冊中心互動。為了確定已更新的和沒更新的應用能夠互相訂閱,做了一些支援:
- 提供應用級 Publisher 轉接到口級 Publisher 的能力:接口級訂閱端是無法直接訂閱應用級釋出資料的,針對接口級訂閱按需從 AppPublisher 轉換出 InterfacePublisher,沒有接入 MOSN 的應用可以順利的訂閱到這部分資料,因為隻有少量應用沒有接入 MOSN,需要轉化的應用級 Publisher 很少。
- 應用級訂閱端在訂閱的時候額外發起一個接口級的訂閱,用于訂閱沒有接入更新的應用釋出資料。由于這部分應用非常少,實際絕大多數的服務級訂閱都不會有推送任務,是以對推送不會造成壓力。
「效果」
上圖是一個叢集切換應用級後的效果,其中切換後剩餘部分接口級 pub 是為了相容轉換出來的資料,接口級 sub 沒減少也是為了相容接口級釋出。如果不考慮相容性,pub 資料減少高達 97%。極大的減輕了資料規模的對叢集的壓力。
SOFARegistryChaos:自動化測試
注冊中心的最終一緻性的模型一直是個測試難題:
- 最終是多久?
- 達到最終前有沒有推送錯誤的資料
- 達到最終前有沒有推送少資料
- 叢集發生故障/資料遷移時對資料的正确性和時延的影響
- client 端頻繁按照各種順序調用 API 的影響
- client 端頻繁連接配接斷連的影響
針對該系列問題,我們開發了 SOFARegistryChaos,特别針對最終一緻性提供完備的測試能力,除此還提供功能/性能/大規模壓測/混沌測試等能力。同時,通過插件化的機制,也支援接入測試其他服務發現産品的能力,基于 K8s 的部署能力,能讓我們快速的部署測試元件。
具備以上的能力後,不單可以測試自身的産品能力,例如還可以快速的測試 zookeeper 在服務發現方面的相關性能來做産品比較。
測試觀測性
提供的關鍵資料的觀測能力,通過 metrics 透出,對接 Prometheus 即可提供可視化能力:
- 推送時延
- 設定時間内的最終一緻性檢測
- 發生故障注入的時間點
- 最終一緻期間推送資料的完整性
該能力的測試是一個比較有意思的創新點,通過固化一部分的 client 和對應的 pub,校驗每次其他各種變更導緻的推送資料,這部分資料都必須是要完整和正确的。
- 推送次數
- 推送資料體積
失敗 case 的排查
測試場景中,client 操作時序和故障注入都是随機編排的,我們在 SOFARegistryChaos master 端記錄和收集了所有的操作指令時序。當 case 失敗時,可通過失敗的資料明細和各個 client 的 API 調用情況來快速定位問題。
例如下圖的失敗 case 顯示在某個 Node 上的訂閱者對某個 dataId 的訂閱資料沒通過校驗,預期是應該要推空, 但是推送了一條資料下來。同時顯示了該 dataId 所有相關的 publisher 在測試期間的相關操作軌迹。
黑盒探測
大家是否經曆過類似的 case:
- 突然被業務告知系統出現問題,一臉懵的我:系統沒異常啊
- 發現系統出現故障時,實際已經對業務造成了嚴重影響
注冊中心因為本身的特性,對業務的影響往往是滞後的,例如 2K 個 IP 隻推送了 1K 個,這種錯誤不會導緻業務馬上感覺到異常。但是實際本身已經出問題了。對于注冊中心,更需要有提前發現治末病的能力。
這裡我們引入黑盒探測的方式:模拟廣義上的使用者行為,探測鍊路是否正常。
SOFARegistryChaos 實際上就可以作為一個注冊中心的使用者,并且是加強版的,提供端到端的告警能力。
我們把 SOFARegistryChaos 部署到線上,開啟小流量作為一個監控項。當注冊中心異常但還沒對業務造成可感覺的影響時,我們有機會及時介入,減少風險事件更新成大故障的風險。
磨刀不誤砍柴工
通過 SOFARegistryChaos,核心能力的驗證效率極大提升,品質得到保障的同時,開發同學寫代碼也輕松了許多。從 7 月份到 10 月中的 3 個半月時間裡,我們疊代并釋出了 5 個版本,接近 3 周 1 個版本。這個開發效率在以前是不敢想象的,同時也獲得完善的端到端告警能力。
運維自動化
nightly build
雖然我們叢集數目非常多,但是因為是區分了多環境,部分環境對于穩定性的要求相對生産流量要求稍微低一些,例如灰階以下的環境。這些環境的叢集是否可以在新版本保證品質的情況下,快速低成本的 apply 。結合 SOFARegistryChaos,我們和品質/SRE 的同學正在建設 nightly build 設施。
SOFARegistryChaos 作為變更門禁,新版本自動化的部署,接受 SOFARegistryChaos 的測試通過後,自動化部署到灰階以下的叢集,僅在生産釋出時候人工介入。
通過 nightly build,極大的減輕非生産環境的釋出成本,同時新版本能盡早接受業務流量的檢驗。
故障演練
雖然我們做了大量的品質相關的工作,但是線上上面對各種故障時究竟表現如何?是騾子還是馬,還是要拉出來溜一溜。
我們和 SRE 的同學線上上會定期做故障容災演練,包括但不限于網絡故障;大規模機器當機等。另外演練不能是一錘子買賣的事情,沒有保鮮的容災能力其實等于 0。在仿真/灰階叢集,進行容災常态化,演練-疊代循環。
定位診斷
故障容災演練常态化後,如何快速的定位到故障源成了擺在桌子上的一個問題,否則每次演練都雞飛狗跳的,效率太低了。
SOFARegistry 各個節點做了大量的可觀測性的改進,提供豐富的可觀測能力,SRE 的診斷系統通過相關資料做實時診斷,例如這個 case 裡就是一個 session 節點故障導緻 SLO 破線。有了定位能力後,自愈系統也可以發揮作用,例如某個 session 節點被診斷出網絡故障,自愈系統可以觸發故障節點的自動化替換。
目前,我們的容災演練應急絕大部分 case 已經不需要人肉介入,也隻有這樣低成本的演練才能常态化。
「收益」
通過不斷的演練暴露問題和快速疊代修複,SOFARegistry 的穩定性逐漸提升。
SOFARegistry 6.0 除了自身的優化,在測試/運維/應急方面做了大量的工作,目标是提升研發/品質/運維人員的效能,讓相關同學擺脫低效的人肉工作,提升幸福感。
PART. 4 開源:一個人可以走得很快,但一群人可以走的更遠
SOFARegistry 是一個開源項目,也是開源社群 SOFAStack 重要的一環,我們希望用社群的力量推動 SOFARegistry 的前進,而不是隻有螞蟻集團的工程師去開發。
在過去一年,SOFARegistry 因為重心在 6.0 重構上,社群幾乎處于停滞狀态,這個是我們做得不夠好的地方。
我們制定了未來半年的社群計劃,在 12 月份會基于内部版本開源 6.0,開源的代碼包含内部版本的所有核心能力,唯一差別是内部版本多了對 confreg-client 的相容性支援。
另外從 6.1 後,我們希望後繼的方案設計/讨論也是基于社群來開展,整個研發程序更透明和開放。
PART. 5 我們仍在路上
2021 年是 SOFARegistry 審視過去,全面夯實基礎,提升效能的一年。
當然,我們目前還仍然處在初級階段,前面還有很長的路要走。例如今年雙十一的規模面臨一系列非常棘手的問題:
- 一個叢集内單應用執行個體數過多(熱點應用單叢集高達 7K 個執行個體)導緻業務端收到位址推送時 CPU/memory 開銷過大。
- 全位址清單推送,導緻的連接配接數過多等。
還有其他的挑戰:
- 增量推送,減少推送資料量和 client 端的資源開銷
- 統一服務發現,支援跨叢集
- 适應雲原生下的新趨勢
- 社群的營運
- 産品易用性
「參 考」
【1】Dubbo3 提出了應用級服務發現和相關原理:
https://dubbo.apache.org/zh/blog/2021/06/02/dubbo3-%E5%BA%94%E7%94%A8%E7%BA%A7%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8E%B0/關于我們:
螞蟻應用服務團隊是服務于整個螞蟻集團的核心技術團隊,打造了世界領先的金融級分布式架構的基礎設施平台,是 Service Mesh 等雲原生領域的領先者,開發運維着全球最大的 Service Mesh 叢集,螞蟻集團的消息中間件每天支撐上萬億的消息流轉。
歡迎對 Service Mesh/微服務/服務發現 等領域感興趣的同學加入我們。
聯系郵箱: [email protected]
本周推薦閱讀
穩定性大幅度提升:SOFARegistry v6 新特性介紹 我們做出了一個分布式注冊中心 Prometheus on CeresDB 演進之路) 如何在生産環境排查 Rust 記憶體占用過高問題