本文轉載自公衆号【麒思妙想】,詳細介紹了 Flink + Hudi 湖倉一體化方案的原型建構。主要内容為:
- Hudi
- 新架構與湖倉一體
- 最佳實踐
- Flink on Hudi
- Flink CDC 2.0 on Hudi
一、Hudi
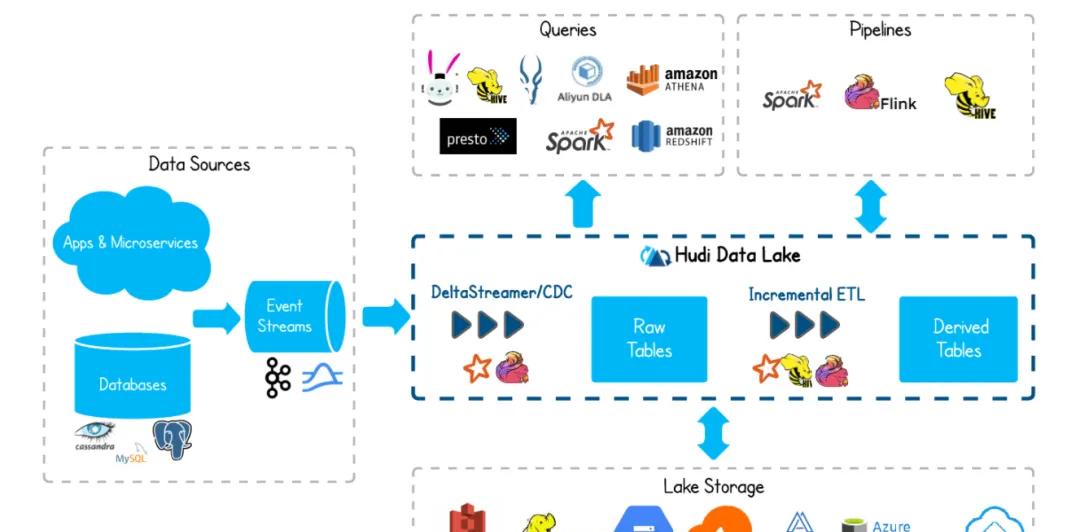
1. 簡介
Apache Hudi (發音為 “Hoodie”)在 DFS 的資料集上提供以下流原語
- 插入更新 (如何改變資料集?)
- 增量拉取 (如何擷取變更的資料?)
Hudi 維護在資料集上執行的所有操作的時間軸 (timeline),以提供資料集的即時視圖。Hudi 将資料集組織到與 Hive 表非常相似的基本路徑下的目錄結構中。資料集分為多個分區,檔案夾包含該分區的檔案。每個分區均由相對于基本路徑的分區路徑唯一辨別。
分區記錄會被配置設定到多個檔案。每個檔案都有一個唯一的檔案 ID 和生成該檔案的送出 (commit)。如果有更新,則多個檔案共享相同的檔案 ID,但寫入時的送出 (commit) 不同。
存儲類型 – 處理資料的存儲方式
- 寫時複制
- 純列式
- 建立新版本的檔案
- 讀時合并
- 近實時
視圖 – 處理資料的讀取方式
讀取優化視圖 - 輸入格式僅選擇壓縮的列式檔案
- parquet 檔案查詢性能
- 500GB 的延遲時間約為 30 分鐘
- 導入現有的 Hive 表
近實時視圖
- 混合、格式化資料
- 約 1-5 分鐘的延遲
- 提供近實時表
增量視圖
- 資料集的變更
- 啟用增量拉取
Hudi 存儲層由三個不同的部分組成
中繼資料 – 它以時間軸的形式維護了在資料集上執行的所有操作的中繼資料,該時間軸允許将資料集的即時視圖存儲在基本路徑的中繼資料目錄下。時間軸上的操作類型包括
- 送出 (commit),一次送出表示将一批記錄原子寫入資料集中的過程。單調遞增的時間戳,送出表示寫操作的開始。
- 清理 (clean),清理資料集中不再被查詢中使用的檔案的較舊版本。
- 壓縮 (compaction),将行式檔案轉化為列式檔案的動作。
- 索引,将傳入的記錄鍵快速映射到檔案 (如果已存在記錄鍵)。索引實作是可插拔的,Bloom 過濾器 - 由于不依賴任何外部系統,是以它是預設配置,索引和資料始終保持一緻。Apache HBase - 對少量 key 更高效。在索引标記過程中可能會節省幾秒鐘。
- 資料,Hudi 以兩種不同的存儲格式存儲資料。實際使用的格式是可插入的,但要求具有以下特征 – 讀優化的列存儲格式 (ROFormat),預設值為 Apache Parquet;寫優化的基于行的存儲格式 (WOFormat),預設值為 Apache Avro。
2. 為什麼 Hudi 對于大規模和近實時應用很重要?
Hudi 解決了以下限制:
- HDFS 的可伸縮性限制;
- 需要在 Hadoop 中更快地呈現資料;
- 沒有直接支援對現有資料的更新和删除;
- 快速的 ETL 和模組化;
- 要檢索所有更新的記錄,無論這些更新是添加到最近日期分區的新記錄還是對舊資料的更新,Hudi 都允許使用者使用最後一個檢查點時間戳。此過程不用執行掃描整個源表的查詢。
3. Hudi的優勢
- HDFS 中的可伸縮性限制;
- Hadoop 中資料的快速呈現;
- 支援對于現有資料的更新和删除;
- 快速的 ETL 和模組化。
(以上内容主要引用于:《Apache Hudi 詳解》)
二、新架構與湖倉一體
通過湖倉一體、流批一體,準實時場景下做到了:資料同源、同計算引擎、同存儲、同計算口徑。資料的時效性可以到分鐘級,能很好的滿足業務準實時數倉的需求。下面是架構圖:

MySQL 資料通過 Flink CDC 進入到 Kafka。之是以資料先入 Kafka 而不是直接入 Hudi,是為了實作多個實時任務複用 MySQL 過來的資料,避免多個任務通過 Flink CDC 接 MySQL 表以及 Binlog,對 MySQL 庫的性能造成影響。
通過 CDC 進入到 Kafka 的資料除了落一份到離線資料倉庫的 ODS 層之外,會同時按照實時資料倉庫的鍊路,從 ODS->DWD->DWS->OLAP 資料庫,最後供報表等資料服務使用。實時數倉的每一層結果資料會準實時的落一份到離線數倉,通過這種方式做到程式一次開發、名額口徑統一,資料統一。
從架構圖上,可以看到有一步資料修正 (重跑曆史資料) 的動作,之是以有這一步是考慮到:有可能存在由于口徑調整或者前一天的實時任務計算結果錯誤,導緻重跑曆史資料的情況。
而存儲在 Kafka 的資料有失效時間,不會存太久的曆史資料,重跑很久的曆史資料無法從 Kafka 中擷取曆史源資料。再者,如果把大量的曆史資料再一次推到 Kafka,走實時計算的鍊路來修正曆史資料,可能會影響當天的實時作業。是以針對重跑曆史資料,會通過資料修正這一步來處理。
總體上說,這個架構屬于 Lambda 和 Kappa 混搭的架構。流批一體資料倉庫的各個資料鍊路有資料品質校驗的流程。第二天對前一天的資料進行對賬,如果前一天實時計算的資料無異常,則不需要修正資料,Kappa 架構已經足夠。
(本節内容,引用自:《37 手遊基于 Flink CDC + Hudi 湖倉一體方案實踐》)
三、最佳實踐
1. 版本搭配
版本選擇,這個問題可能會成為困擾大家的第一個絆腳石,下面是 Hudi 中文社群推薦的版本适配:
| Flink | |
|---|---|
| 1.12.2 | 0.9.0 |
| 1.13.1 | 0.10.0 |
建議用 Hudi master +Flink 1.13 這樣可以和 CDC connector 更好地适配。
2. 下載下傳Hudi
https://mvnrepository.com/artifact/org.apache.Hudi/Hudi-Flink-bundle
目前 maven 中央倉庫,最新版本是 0.9.0 ,如果需要下載下傳 0.10.0 版本 , 可以加入社群群,在共享檔案中下載下傳,也可以下載下傳源碼自行編譯。
3. 執行
如果将
Hudi-Flink-bundle_2.11-0.10.0.jar
放到了
Flink/lib
下,則隻需要如下執行即可,否則會出現各種找不到類的異常
bin/SQL-client.sh embedded
四、Flink on Hudi
建立 maven 工程,修改 pom 如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>Flink_Hudi_test</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<Flink.version>1.13.1</Flink.version>
<Hudi.version>0.10.0</Hudi.version>
<hadoop.version>2.10.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-core</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-streaming-java_2.11</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-connector-jdbc_2.11</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-java</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-clients_2.11</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-table-api-java-bridge_2.11</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-table-common</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-table-planner_2.11</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-table-planner-blink_2.11</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-table-planner-blink_2.11</artifactId>
<version>${Flink.version}</version>
<type>test-jar</type>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>Flink-connector-mySQL-CDC</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hudi</groupId>
<artifactId>Hudi-Flink-bundle_2.11</artifactId>
<version>${Hudi.version}</version>
<scope>system</scope>
<systemPath>${project.basedir}/libs/Hudi-Flink-bundle_2.11-0.10.0-SNAPSHOT.jar</systemPath>
</dependency>
<dependency>
<groupId>mySQL</groupId>
<artifactId>mySQL-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
</dependencies>
</project> 我們通過建構查詢
insert into t2 select replace(uuid(),'-',''),id,name,description,now() from mySQL_binlog
将建立的 MySQL 表,插入到 Hudi 裡。
package name.lijiaqi;
import org.apache.Flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.Flink.table.api.EnvironmentSettings;
import org.apache.Flink.table.api.SQLDialect;
import org.apache.Flink.table.api.TableResult;
import org.apache.Flink.table.api.bridge.java.StreamTableEnvironment;
public class MySQLToHudiExample {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSQLDialect(SQLDialect.DEFAULT);
// 資料源表
String sourceDDL =
"CREATE TABLE mySQL_binlog (\n" +
" id INT NOT NULL,\n" +
" name STRING,\n" +
" description STRING\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mySQL://127.0.0.1:3306/test', \n"+
" 'driver' = 'com.mySQL.jdbc.Driver', \n"+
" 'username' = 'root',\n" +
" 'password' = 'dafei1288', \n" +
" 'table-name' = 'test_CDC'\n" +
")";
// 輸出目标表
String sinkDDL =
"CREATE TABLE t2(\n" +
"\tuuid VARCHAR(20),\n"+
"\tid INT NOT NULL,\n" +
"\tname VARCHAR(40),\n" +
"\tdescription VARCHAR(40),\n" +
"\tts TIMESTAMP(3)\n"+
// "\t`partition` VARCHAR(20)\n" +
")\n" +
// "PARTITIONED BY (`partition`)\n" +
"WITH (\n" +
"\t'connector' = 'Hudi',\n" +
"\t'path' = 'hdfs://172.19.28.4:9000/Hudi_t4/',\n" +
"\t'table.type' = 'MERGE_ON_READ'\n" +
")" ;
// 簡單的聚合處理
String transformSQL =
"insert into t2 select replace(uuid(),'-',''),id,name,description,now() from mySQL_binlog";
tableEnv.executeSQL(sourceDDL);
tableEnv.executeSQL(sinkDDL);
TableResult result = tableEnv.executeSQL(transformSQL);
result.print();
env.execute("mySQL-to-Hudi");
}
} 查詢 Hudi
package name.lijiaqi;
import org.apache.Flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.Flink.table.api.EnvironmentSettings;
import org.apache.Flink.table.api.SQLDialect;
import org.apache.Flink.table.api.TableResult;
import org.apache.Flink.table.api.bridge.java.StreamTableEnvironment;
public class ReadHudi {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSQLDialect(SQLDialect.DEFAULT);
String sourceDDL =
"CREATE TABLE t2(\n" +
"\tuuid VARCHAR(20),\n"+
"\tid INT NOT NULL,\n" +
"\tname VARCHAR(40),\n" +
"\tdescription VARCHAR(40),\n" +
"\tts TIMESTAMP(3)\n"+
// "\t`partition` VARCHAR(20)\n" +
")\n" +
// "PARTITIONED BY (`partition`)\n" +
"WITH (\n" +
"\t'connector' = 'Hudi',\n" +
"\t'path' = 'hdfs://172.19.28.4:9000/Hudi_t4/',\n" +
"\t'table.type' = 'MERGE_ON_READ'\n" +
")" ;
tableEnv.executeSQL(sourceDDL);
TableResult result2 = tableEnv.executeSQL("select * from t2");
result2.print();
env.execute("read_Hudi");
}
} 展示結果
五、Flink CDC 2.0 on Hudi
上一章節,我們使用代碼形式建構實驗,在本章節裡,我們直接使用官網下載下傳的 Flink 包來建構實驗環境。
1. 添加依賴
添加如下依賴到 $Flink_HOME/lib 下:
- Hudi-Flink-bundle_2.11-0.10.0-SNAPSHOT.jar (修改 Master 分支的 Hudi Flink 版本為 1.13.2 然後建構)
- hadoop-mapreduce-client-core-2.7.3.jar (解決 Hudi ClassNotFoundException)
- Flink-SQL-connector-mySQL-CDC-2.0.0.jar
- Flink-format-changelog-json-2.0.0.jar
- Flink-SQL-connector-Kafka_2.11-1.13.2.jar
注意,在尋找 jar 的時候,
CDC 2.0
更新過
group id
,不再試
com.alibaba.ververica
而是改成了
com.ververica
2. Flink SQL CDC on Hudi
建立 MySQL CDC 表
CREATE TABLE mySQL_users (
id BIGINT PRIMARY KEY NOT ENFORCED ,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector' = 'mySQL-CDC',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'dafei1288',
'server-time-zone' = 'Asia/Shanghai',
'database-name' = 'test',
'table-name' = 'users'
); 建立 Hudi 表
CREATE TABLE Hudi_users5(
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
`partition` VARCHAR(20)
) PARTITIONED BY (`partition`) WITH (
'connector' = 'Hudi',
'table.type' = 'MERGE_ON_READ',
'path' = 'hdfs://localhost:9009/Hudi/Hudi_users5'
); 修改配置,讓查詢模式輸出為表,設定 checkpoint
set execution.result-mode=tableau;
set execution.checkpointing.interval=10sec;
進行輸入導入
INSERT INTO Hudi_users5(id,name,birthday,ts, partition
查詢資料
select * from Hudi_users5;
執行結果
3. 卡執行計劃
這個問題研究了很久,表面上很正常,日志也沒有任何報錯,也可以看出來 CDC 起作用了,有資料寫入,但是就是卡在
hoodie_stream_write
上一動不動,沒有資料下發。感謝社群大佬
Danny Chan
的提點,可能是 checkpoint的問題,于是做了設定
于是終于正常:
至此,Flink + Hudi 湖倉一體化方案的原型建構完成。
參考連結
https://blog.csdn.net/weixin_49218925/article/details/115511022 https://blog.csdn.net/qq_37095882/article/details/103714548 https://mp.weixin.qq.com/s/xoucbJxzO2Zkq_b2_WDUbA