上篇文章已經成功內建了Trino和CarbonData,這篇文章主要是測試我們的功能和性能方面的一些測試,測試出CarbonData相對于社群其他的一些檔案格式的優勢以及驗證內建性能和可靠性,包括是否能正确啟動叢集,正确識别Carbondata檔案進行讀取資料做count,聚合分析等
建表語句:
/*
* create table by user pay list
*/
CREATE TABLE IF NOT EXIST CARBONDATA_PAYMENT (
`gameId` int,
`unionId` int,
`orderId` STRING,
`userId` INT,
`createTime` bigint,
`payTime` bigint,
`status` int,
`money` int
) stored as carbondata
生成測試資料的Spark代碼:
package org.apache.carbondata.trino
import org.apache.spark.SparkContext
import org.apache.spark.sql.CarbonSession._
import org.apache.spark.sql.SparkSession
import scala.util.Random
/**
* @Description Build Test Data Store AS CarbonData
* @Author chenzhengyu
* @Date 2021-09-10 20:37
object TestDataFromCarbonData {
def main(args: Array[String]): Unit = {
val sc = new SparkContext();
val spark = SparkSession.builder().enableHiveSupport().getOrCreate()
val carbon = SparkSession.builder().config(sc.getConf).getOrCreateCarbonSession("hdfs://localhost:9000/user/hive/warehouse")
//build random num
val randomGameId = new Random(5);
val randomMoney = new Random();
import spark.implicits._
//build data
val dfTemp = spark.sparkContext.parallelize(1 to 1000000000).map(x => (randomGameId.nextInt(5), x % 8, "20210920" + (x % 100), x % 5, System.currentTimeMillis() + x % 500L, System.currentTimeMillis() + x % 500L, randomGameId.nextInt(4), randomMoney.nextInt(1000))).toDF("gameId", "unionId", "orderId", "userId", "createTime", "payTime", "status", "money")
//create temp view
dfTemp.createOrReplaceTempView("temp")
//create table
carbon.sql("CREATE TABLE CARBONDATA_PAYMENT (`gameId` int, `unionId` int, `orderId` STRING, `userId` INT, `createTime` bigint, `payTime` bigint,`status` int,`money` int ) stored as carbondata")
//show tables
carbon.sql("show tables").show
//insert data and select
spark.sql("insert into table CARBONDATA_PAYMENT select * from temp")
spark.sql("select count(1) from CARBONDATA_PAYMENT").show()
sc.stop()
}
}
這一部分代碼我們可以使用Spark-Shell或者使用打包工具打包成JAR,通過Standalone模式或者YARN模式進行執行,執行的流程如下:
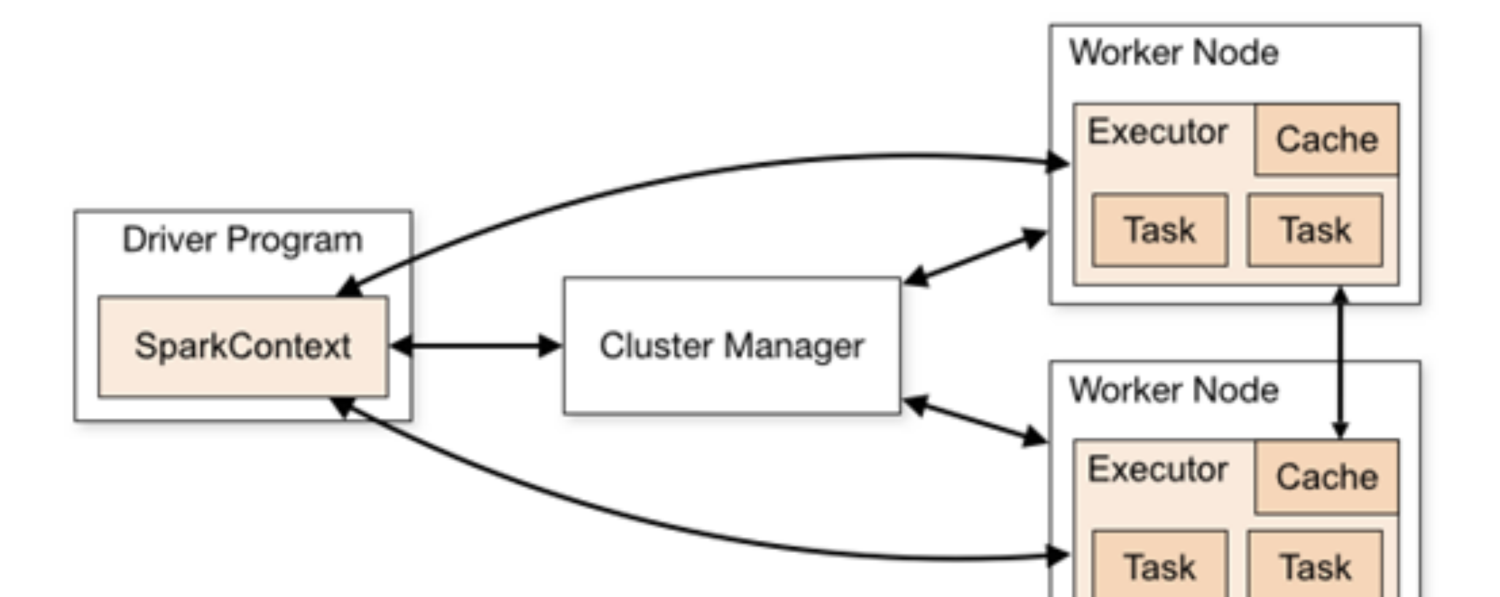
Spark架構的核心是一個計算引擎,整體來說,它采用了标準 master-slave 的結構。
如上圖所示,它展示了一個 Spark執行時的基本結構。圖形中的Driver表示master,負責管理整個叢集中的作業任務排程。圖形中的Executor 則是 slave,負責實際執行任務
我一共插入了大概10億條資料左右,平均每個分區插入2.5E條資料:

SELCT COUNT(1) AS TOTAL FROM CARBONDATA_PAYMENT
SELECT USERID,SUM(MONEY) AS TOTAL FROM CARBONDATA_PAYMENT GROUP BY USERID
這個流程針上面我做一個簡單的總結:首先我們通過Spark 內建 Carbondata成功後,去生成Carbondata檔案,我們通過SparkSession 這個類去生成一個臨時會話,然後通過Spark RDD 去模拟一些遊戲玩家訂單充值資料,然後注冊為臨時表Temp。通過在Spark上連接配接Hive中繼資料庫建立Carondata表,名字為CARBONDATA_PAYMENT的表。然後通過INSERT語句把剛剛的生成的資料插入到Hive表上,這個過程大概在10分鐘左右(受限于本機磁盤和CPU性能影響),後續我們通過觀察即可發現Hadoop的HDFS上已經寫入了對應的資料了。接着我們就可以關閉Spark了,開始啟動Presto(Trino)的服務端和用戶端,按照配置檔案配置好Hive的MetaStore位址和Catlog,我們使用Trino用戶端連接配接進去。連接配接進去後我們通過網頁打開控制台進行觀察SQL的執行情況。然後我們執行簡單查詢看看是否能正常工作,檢測完畢後,我們執行聚合查詢,模拟查詢根據玩家ID的總充值金額。然後在不同資料量(1w->10w->100w->1000w->1e->10e)的查詢下的執行情況。然後我們再模拟查詢某個玩家訂單号去查詢相關的詳情資料情況,并且最後對此進行總結。與此同時,我們模拟超出記憶體超出執行的情況,保護查詢避免叢集出現OOM的機制
受限于本機性能發揮,基于剛剛按照導師要求進行的大規模資料測試結論如下:
- 基本查詢、聚合查詢等查詢基本無問題,證明新版本Presto(Trino)內建成功
- 在做Count資料操作時候非常的快,基本1-2s可以出到結果,針對複雜的條件Count,如果有索引列也很快能查詢出來
- 通過觀察HDFS檔案路徑,可以發現Index檔案是單獨存儲的一份檔案,這樣做的目的是提升資料讀取效率
- 針對次元的查詢明細資料,例如根據訂單号進行查詢,我們可以發現在10E資料中秒級傳回查詢的明細資料,這個速度是十分快的
- 如果在執行時候,超過允許最大執行記憶體,則會叢集有停止執行的機制,避免記憶體oom