本文整理自京東進階技術專家付海濤在 Flink Forward Asia 2020 分享的議題《Apache Flink 在京東的實踐與優化》,内容包括:
- 業務演進和規模
- 容器化實踐
- Flink 優化改進
- 未來規劃
GitHub 位址
https://github.com/apache/flink歡迎大家給 Flink 點贊送 star~
一、業務演進和規模
1. 業務演進
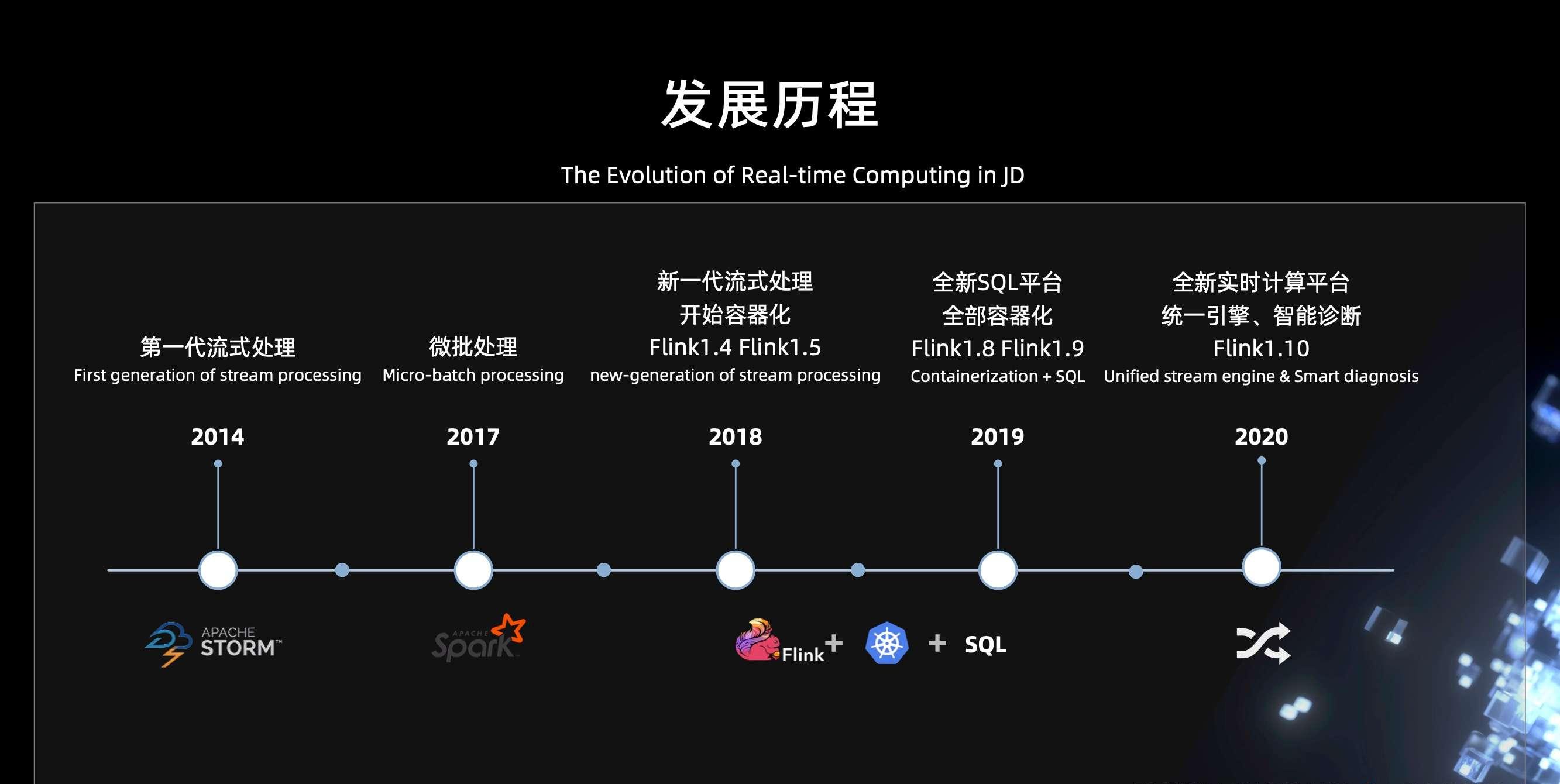
京東在 2014 年基于 storm 打造了第一代流式處理平台,可以較好的滿足業務對于資料處理實時性的要求。不過它有一些局限性,對于那些資料量特别大,但是對延遲卻不那麼敏感的業務場景,顯得有些力不從心。于是我們在 2017 年引入了 Spark streaming,利用它的微批處理來應對這種業務場景。
随着業務的發展和業務規模的擴大,我們迫切需要一種兼具低延遲和高吞吐能力,同時支援視窗計算、狀态和恰好一次語義的計算引擎。
- 于是在 2018 年,我們引入了 Flink,同時開始基于 K8s 進行實時計算容器化的更新改造;
- 到了 2019 年,我們所有的實時計算任務都跑在 K8s 上了。同年我們基于 Flink 1.8 打造了全新的 SQL 平台,友善業務開發實時計算應用;
- 到了 2020 年,基于 Flink 和 K8s 打造的全新實時計算平台已經比較完善了,我們進行了計算引擎的統一,同時支援智能診斷,來降低使用者開發和運維應用的成本和難度。在過去,流處理是我們關注的一個重點。同年,我們也開始支援批處理,于是整個實時計算平台開始朝着批流一體的方向演進。
2. 業務場景
京東 Flink 服務于京東内部非常多的業務線,主要應用場景包括實時數倉、實時大屏、實時推薦、實時報表、實時風控和實時監控,當然還有其他一些應用場景。總之,實時計算的業務需求,一般都會用 Flink 進行開發。

3. 業務規模
目前我們的 K8s 叢集由 5000 多台機器組成,服務了京東内部 20 多個一級部門。目前線上的流計算任務數有 3000 多,流計算的處理峰值達到 5億條每秒。
二、容器化實踐
下面分享一下容器化的實踐。
在 2017 年,京東内部的大多數任務還是 storm 任務,它們都是跑在實體機上的,同時還有一小部分的 Spark streaming 跑在 Yarn 上。不同的運作環境導緻部署和運維的成本特别高,并且在資源利用上有一定的浪費,是以我們迫切需要一個統一叢集資源管理和排程系統,來解決這個問題。
經過一系列的嘗試、對比和優化,我們選擇了 K8s。它不僅可以解決部署運維、資源利用的一些問題,還具有雲原生彈性自愈、天然容器完整隔離、更易擴充遷移等優點。于是在 2018 年初,我們開始進行容器化的更新改造。
在 2018 年的 6.18,我們隻有 20% 的任務跑在 K8s 上;到了 2019 年 2 月份,已經實作了實時計算的所有任務都跑在 K8s 上。容器化後的實時計算平台經曆了 6.18,雙 11 多次大促,扛住了洪峰壓力,運作的非常穩定。
但是,我們過去的 Flink 容器化方案是基于資源預先配置設定的靜态方式,不能滿足很多業務場景,于是我們在 2020 年也進行了一個容器化方案的更新,後面會詳細介紹。
容器化帶來非常多的收益,這裡主要強調三點:
- 第一,可以很友善的實作服務的混合部署,極大地提升資源共享能力,節省機器資源。
- 第二,天然的彈性擴充,一定的自愈能力,并且它可以做到一個更完整的資源隔離,更好的保障業務的穩定性。
- 第三,通過容器化實作了開發、測試、生産的一緻環境,同時提高了部署和自動化運維的能力,使管理和運維的成本降低了一半。
我們過去的容器化方案是基于 K8s deployment 部署的 Standalone Session 叢集。它需要使用者在平台建立叢集時,事先預估出叢集所需資源,比如需要的 jobmanager 和 taskmanager 的資源規格和個數,然後平台通過 K8s 用戶端向 K8s master 送出請求,來建立 jobmanager 的 deployment 和 taskmanager 的 deployment。
其中,整個叢集的高可用是基于 ZK 實作;狀态存儲主要是存在 HDFS,有小部分存在 OSS;監控名額 (容器名額、JVM 名額、任務名額) 上報到 Prometheus,結合 Grafana 實作名額的直覺展示;日志是基于我們京東内部的 Logbook 系統進行采集、存儲和查詢。
在實踐中發現,這個方案有兩點不足:
- 第一,資源需要提前配置設定,無法滿足靈活多變的業務需要,無法做到按需配置設定。
- 第二,極端場景下 Pod 不能正常拉起, 影響任務恢複 。
于是我們進行了一個容器化方案的更新,實作了基于 K8s 的動态的資源配置設定方式。在叢集建立的時候,首先我們會根據使用者指定的 job manager 的數量建立 jobmanager 的 deployment;使用者在送出任務的時候,我們會根據任務所需要的資源數,動态的向平台申請資源,建立 taskmanager。
在運作過程中,如果發現這個任務需要擴容,job manager 會和平台互動,進行動态擴容;而在發現資源浪費時,會進行縮容。通過這樣一個方式可以很好的解決靜态預配置設定帶來的問題,并提高了資源使用率。
此處,通過平台與 K8s 互動進行資源的建立&銷毀,主要基于 4 點考慮:
- 保證了計算平台對資源的監管。
- 避免了平台叢集配置 & 邏輯變化對鏡像的影響。
- 屏蔽了不同容器平台的差異。
- 平台原有 K8s 互動相關代碼複用。
另外,為了相容原有 Slot 配置設定政策 (按 slot 分散),在送出任務時會預估出任務所需資源并一次性申請,同時按照一定的政策進行等待。等到有足夠的資源,能滿足任務運作的需求時,再進行 slot 的配置設定。這樣很大程度上可以相容原有的 slot 分散配置設定政策。
三、Flink 優化改進
下面介紹一下 Flink 的優化改進。
1、預覽拓撲
在業務使用平台的過程中,我們發現有幾個業務痛點:
- 第一,任務調優繁瑣。在平台送出任務、運作之後如果要調整任務并行度、Slot 分組、Chaining 政策等,需要重新修改程式,或者通過指令行參數配置的方式進行調優,這是非常繁瑣的。
- 第二,SQL 任務無法靈活指定算子配置。
- 第三,任務送出到叢集之後,到底需要多少資源,任務所需 Slot 數預先不清楚。
- 第四,并行度調整後網絡 buffer 不足。
為了解決這些問題,我們開發了預覽拓撲的功能:
- 第一,拓撲配置。使用者送出任務到平台之後,我們會把拓撲給預覽出來,允許它靈活的配置這些算子的并行度。
- 第二,槽位分組預覽。我們會清晰的顯示出任務的槽位分組情況和需要多少個槽。
- 第三,網絡 Buffer 預估。這樣可以最大限度的友善使用者在平台進行業務的調整和調優。
下面簡單介紹預覽拓撲的工作流程。使用者在平台送出 SQL 作業或 Jar 作業,這個作業送出之後,會生成一個算子的配置資訊,再回報到我們平台。我們平台會把整個拓撲圖預覽出來,然後使用者就可以線上進行算子配置資訊的調整。調整完之後,把調整完的配置資訊重新送出到我們平台。并且,這個過程可以是連續調整的,使用者調整完覺得 ok 了就可以送出任務。送出任務之後,整個線上調整的參數就生效了。
這裡任務可以多次送出,如何保證前後兩次送出生成算子穩定的對應關系呢?我們采用這樣一個政策:如果你指定了 uidHash 或者 uid,我們就可以拿 uidHash 和 uid 作為這樣一個對應關系的 Key。如果沒有,我們會周遊整個拓撲圖,按照廣度優先的順序,根據算子在拓撲圖中的位置生成确定的唯一的 ID。拿到唯一的 ID 之後,就可以得到一個确定的關系了。
2、背壓量化
下面介紹一下我們的第二個改進,背壓量化。目前觀測背壓有兩種方式:
- 第一種方式是通過 Flink UI 的背壓面闆,可以非常直覺的檢視目前的背壓情況。但是它也有些問題:
- 第一,有的場景下采集不到背壓。
- 第二,無法跟蹤曆史背壓情況。
- 第三,背壓影響不直覺。
- 第四,在大并行度的時候背壓采集會有一定的壓力。
- 另外一種觀測背壓的方式是基于 Flink Task Metrics 名額。比如說,它會上報 inPoolUsage、outPoolUsage 這些名額,然後把它采集到 Prometheus 進行一個查詢,這種方式可以解決背壓曆史跟蹤的問題。不過它有其他一些問題:
- 第一,不同 Flink 版本的背壓名額含義有一定差異。
- 第二,分析背壓有一定門檻,你需要對整個背壓相關的名額有比較深的認識,聯合進行分析。
- 第三,背壓的影響不是那麼直覺,很難衡量它對業務的影響。
針對這個問題,我們的解決方案是采集背壓發生的位置、時間和次數名額,然後上報上去。将量化的背壓監控名額與運作時拓撲結合起來,就可以很直覺的看到背壓産生的影響 (影響任務的位置、時長和次數)。
3、檔案系統支援多配置
下面介紹下檔案系統支援多配置的功能。
目前在 Flink 中使用檔案系統時,會使用 FileSystem.get 傳入 URI,FileSystem 會将 shceme+authority 作為 key 去查找緩存的檔案系統,如果不存在,根據 scheme 查找到 FileSystemFactory 調用 create 建立檔案系統,傳回之後就可以對檔案進行操作了。不過,在平台實踐過程中,經常會遇到這樣的問題:
- 第一, 如何把 checkpoint 寫入公共 HDFS,把業務資料寫入另外的 HDFS?比如在平台統一管理狀态,使用者不關注狀态的存儲,隻關注自己業務資料讀寫 HDFS 這樣的場景,會有這樣的需求。怎麼滿足這樣的一個業務場景呢?
- 一個方案是可以把多個 HDFS 叢集的配置進行融合,但是它會有個問題。就是如果多個 HDFS 叢集配置有沖突的話,合并會帶來一定的問題。
- 另外,可以考慮一些聯邦的機制,比如 ViewFs,但這種機制可能又有點重。是否有其它更好的方案呢?
- 第二, 如何将資料從一個 OSS 存儲讀出、處理後寫到另外一個 OSS 存儲?
這兩個問題都涉及到如何讓 Flink 的同一個檔案系統支援多套配置。我們的解決方案是通過使用不同的scheme指定和隔離不同的配置。以 HDFS 支援多配置為例,如下圖所示:
- 第一步,在配置中設定自定義 scheme (aaHDFS) 的綁定的 scheme (HDFS) 及對應 HDFS 配置路徑。
- 第二步,在調用 FileSystem.get 時,從 aaHDFS 對應的路徑加載 Hadoop 配置。
- 第三步,在讀寫 HDFS 時,使用 HadoopFileSystemWrapper 将使用者自定義 scheme 的路徑 (aaHDFS://) 轉換為真實的 hadoop 路徑 (HDFS://)。
我們也做了許多其它的優化和擴充,主要分為三大塊。
- 第一塊是性能的優化,包括 HDFS 優化 (合并小檔案、降低 RPC 調用)、基于負載的動态 rebalance、Slot 配置設定政策擴充 (順序、随機、按槽分散) 等等。
- 第二塊是穩定性的優化,包括 ZK 防抖、JM Failover 優化、最後一次 checkpoint 作為 savepoint 等等。
- 第三塊是易用性的優化,包括日志增強 (日志分離、日志級别動态配置)、SQL 擴充 (視窗支援增量計算,支援offset)、智能診斷等等。
四、未來規劃
最後是未來規劃。歸納為 4 點:
- 第一,持續完善 SQL 平台。持續增強完善 SQL 平台,推動使用者更多地使用 SQL 開發作業。
- 第二,智能診斷和自動調整。全自動智能診斷,自适應調整運作參數,作業自治。
- 第三,批流一體。SQL 層面批流一體,兼具低延遲的流處理和高穩定的批處理能力。
- 第四,AI 探索實踐。批流統一和 AI 實時化,人工智能場景探索與實踐。
第三屆 Apache Flink 極客挑戰賽報名開始!
30 萬獎金等你來!
伴随着海量資料的沖擊,資料處理分析能力在業務中的價值與日俱增,各行各業對于資料處理時效性的探索也在不斷深入,作為主打實時計算的計算引擎 - Apache Flink 應運而生。
為給行業帶來更多實時計算賦能實踐的思路,鼓勵廣大熱愛技術的開發者加深對 Flink 的掌握,Apache Flink 社群聯手阿裡雲、英特爾、阿裡巴巴人工智能治理與可持續發展實驗室 (AAIG)、Occlum 聯合舉辦 "第三屆 Apache Flink 極客挑戰賽暨 AAIG CUP" 活動,即日起正式啟動。
👉
點選了解更多賽事資訊👈
更多 Flink 相關技術問題,可掃碼加入社群釘釘交流群
第一時間擷取最新技術文章和社群動态,請關注公衆号~
活動推薦
阿裡雲基于 Apache Flink 建構的企業級産品-實時計算Flink版現開啟活動:
99 元試用
實時計算Flink版(包年包月、10CU)即有機會獲得 Flink 獨家定制T恤;另包 3 個月及以上還有 85 折優惠!
了解活動詳情:
https://www.aliyun.com/product/bigdata/sc