形形色色的監控系統
監控一直是IT系統中的核心組成部分,負責問題的發現以及輔助性的定位。無論是傳統運維、SRE、DevOps、開發者都需要關注監控系統并參與到監控系統的建設和優化。從最開始大型機的作業系統、Linux基礎名額,監控系統就已經開始出現并逐漸演進,現階段能夠搜尋到的監控系統不下于上百種,按照不同類别也有非常多的劃分方式,例如:
- 監控對象:通用型(通用的監控方式,适應于大部分的監控對象),專一型(為某一功能定制,例如Java的JMX系統、CPU的高溫保護、硬碟的斷電保護、UPS切換系統、交換機監控系統、專線監控等)
- 資料擷取方式:Push(CollectD、Zabbix、InfluxDB);Pull(Prometheus、SNMP、JMX)
- 部署方式:耦合式(和被監控系統在一起部署);單機(單機單執行個體部署);分布式(可以橫向擴充);SaaS化(很多商業的公司提供SaaS的方式,無需部署)
- 資料擷取方式:接口型(隻能通過某些API拿去);DSL(可以有一些計算,例如PromQL、GraphQL);SQL(标準SQL、類SQL)
- 商業屬性:開源免費(例如Prometheus、InfluxDB單機版);開源商業型(例如InfluxDB叢集版、Elastic Search X-Pack);閉源商業型(例如DataDog、Splunk、AWS Cloud Watch)
Pull or Push
對于建設一套公司内部使用的監控系統平台,相對來說可選的方案還是非常多的,無論是用開源方案自建還是使用商業的SaaS化産品,都有比較多的可選項。但無論是開源方案還是商業的SaaS産品,真正實施起來都需要考慮如何将資料給到監控平台,或者說監控平台如何擷取到這些資料。這裡就涉及到資料擷取方式的選型:Pull(拉)還是Push(推)模式?
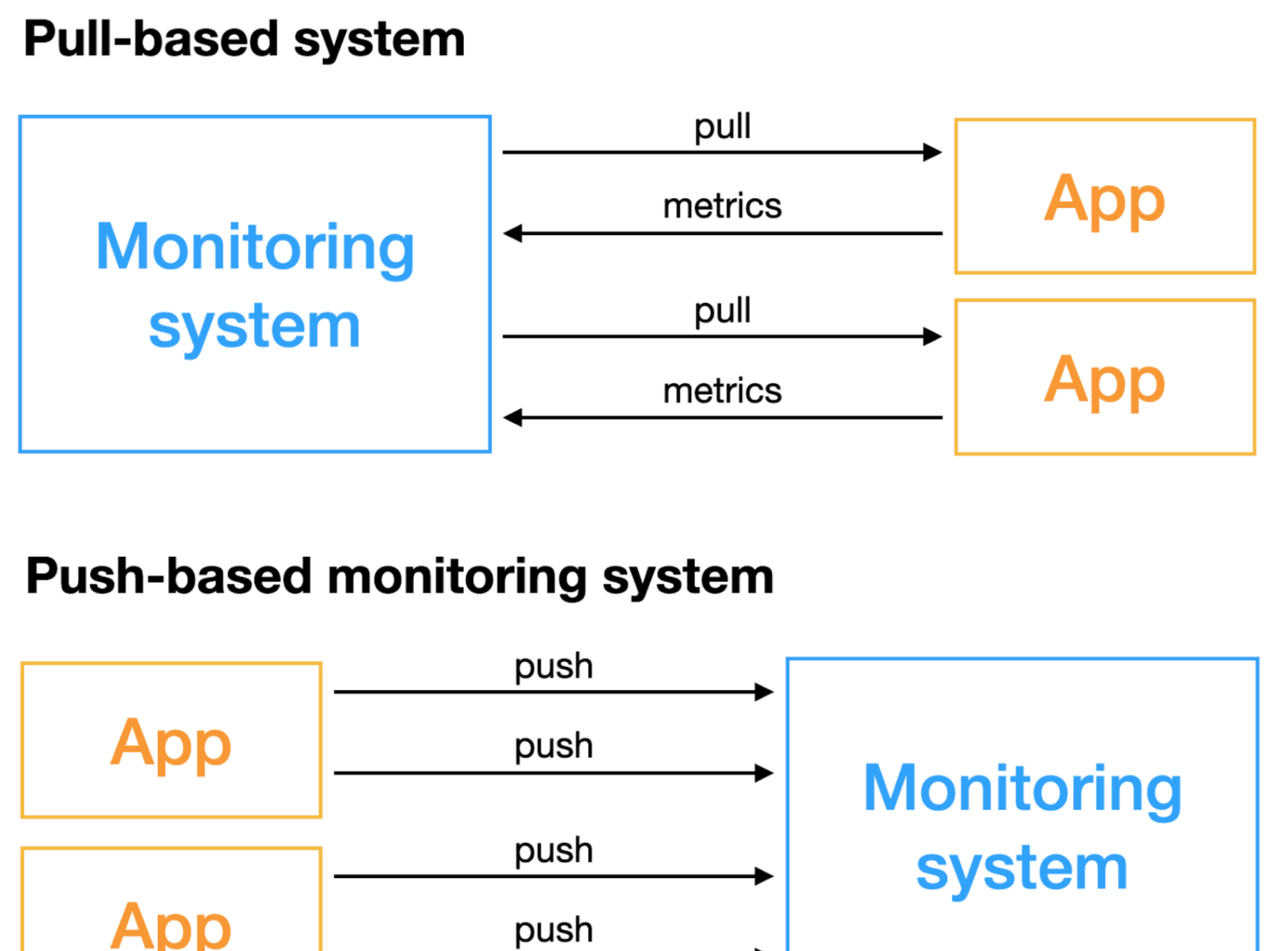
基于Pull類型的監控系統顧名思義是由監控系統主動去擷取名額,需要被監控的對象能夠具備被遠端通路的能力;基于Push類型的監控系統不主動擷取資料,而是由監控對象主動推送名額。兩種方式在非常多的地方都有差別,對于監控系統的建設和選型來說,一定要事先了解這兩種方式各自的優劣,選擇合适的方案來實施,否則如果盲目實施,後續對監控系統的穩定性和部署運維代價來說将是災難性的。
Pull vs Push概覽
下面将從幾個方面來展開介紹,為了節約讀者時間,這裡先用一個表格來做概要性的論述,細節在後面會展開:
| 一級分類 | 二級分類 | Pull | Push |
| 原理與部署 | 配置 | 原生中心化配置 | 端上配置,通過配置中心支援中心化 |
| 監控對象發現 | 依賴服務發現機制,例如Zookeeper、Etcd、Consul等注冊中心 | 由應用、Agent自主上報,無需服務發現子產品 | |
| 部署方式 |
|
| |
| 擴充性 | 可擴充性 | 依賴Pull端擴充;需要Pull Agent和存儲解耦(原生Prometheus不支援);Push Agent按照分片劃分 | 簡單,本身Agent可橫向擴充 |
| 能力對比 | 監控對象存活性 | 簡單 | 無法區分對象未存活的原因 |
| 資料齊全度計算 |
| 較困難 | |
| 短生命周期(Job、Serverless)/資料擷取實時性 | 難以适用 | 适用 | |
| 名額擷取靈活性 | On Demand按需擷取 | 被動接受,需要一些過濾器額外支援 | |
| 應用耦合性 | 應用與監控系統解耦,應用無需關心Push的對端位址、Push錯誤處理等 | 耦合性相比Pull較高 | |
| 機器、人力代價 | 資源消耗 |
|
|
| 安全性保證 | 工作量大,需要保證應用暴露端口的安全性以及Exporter端口的安全性,容易被DDos攻擊或者出現資料洩露 | 低,Agent與服務端一般都進行帶有加密、鑒權的資料傳輸 | |
| 核心運維消耗 |
|
|
原理與架構對比

如上圖所示,Pull模型資料擷取的核心是Pull子產品,一般和監控的後端一起部署,例如Prometheus,核心組成包括:
- 服務發現系統,包括主機的服務發現(一般依賴于公司内部自己的CMDB系統)、應用服務發現(例如Consul)、PaaS服務發現(例如Kubernetes);Pull子產品需要具備對這些服務發現系統的對接能力
- Pull核心子產品,除了服務發現部分外,一般使用通用協定去遠端拉取資料,一般支援配置拉取間隔、逾時間隔、名額過濾/Rename/簡單的Process能力
- 應用側SDK,支援監聽某個固定端口來提供被Pull的能力
- 由于各類中間件/其他系統不相容Pull協定,是以需要開發對應的Exporter的Agent,支援拉取這些系統的名額并提供标準的Pull接口
Push模型相對比較簡單:
- Push Agent,支援拉取各類被監控對象的名額資料,并推送到服務端,可以和被監控系統耦合部署,也可以單獨部署
- ConfigCenter(可選),用來提供中心化的動态配置能力,例如監控目标、采集間隔、名額過濾、名額處理、遠端目标等
- 應用側SDK,支援發送資料到監控後端,或者發送到本地Agent(通常是本地Agent也實作一套後端的接口)
小結:純粹從部署複雜性上而言,在中間件/其他系統的監控上,Pull模型的部署方式太過複雜,維護代價較高,使用Push模式較為便捷;應用提供Metrics端口或主動Push部署代價相差不大。
Pull的分布式解決方案
在擴充性上,Push方式的資料采集天然就是分布式的,在監控後端能力可以跟上的時候,可以無限的橫向擴充。相比之下Pull方式擴充較為麻煩,需要:
- Pull子產品與監控後端解耦,Pull作為Agent單獨部署
- Pull Agent需要做分布式的協同,一般最簡單是做Sharding,例如從服務發現系統處擷取被監控的機器清單,對這些機器進行Hash後取模Sharding來決定由哪個Agent來負責Pull。
- 新增一個配置中心(可選)用來管理各個PullAgent
相信反應快的同學已經看出來,這種分布式的方式還是有一些問題:
- 單點瓶頸還是存在,所有的Agent都需要去請求服務發現子產品
- Agent擴容後,監控目标會變化,容易産生資料重複或缺失
監控能力對比
監控目标存活性
存活性是監控所需要做的第一件也是最基礎的工作,Pull模式監控目标存活性相對來說非常簡單,直接在Pull的中心端就知道能否請求到目标端的名額,如果失敗也能知道一些簡單的錯誤,比如網絡逾時、對端拒絕連接配接等。
Push方式相對來說就比較麻煩,應用沒有上報可能是應用挂了,也可能是網絡問題,也可能是遷移到了其他的節點上了,因為Pull子產品可以和服務發現實時關聯,但Push沒有,是以隻有服務端再和服務發現互動才能知道具體失敗的原因。
資料齊全度這個概念在大型的監控系統中還是非常重要的,比如監控一千個副本的交易應用的QPS,這個名額需要結合一千個資料進行疊加,如果沒有資料齊全度的概念,若配置QPS相比降低2%告警,由于網絡波動,超過20個副本上報的資料延遲幾秒,那就會觸發誤報。是以在配置告警的時候還需要結合資料齊全度資料進行綜合考慮。
資料齊全度的計算也一樣是依賴于服務發現子產品,Pull方式是按照一輪一輪的方式進行拉取,是以一輪拉取完畢後資料就是齊全的,即使部分拉取失敗也知道資料不全的百分比是多少;
而Push方式由每個Agent、應用主動Push,每個用戶端的Push間隔、網絡延遲都不一樣,需要服務端去根據曆史情況計算資料齊全度,相對代價比較大。
短生命周期/Serverless應用監控
在實際場景中,短生命周期/Serverless的應用也有很多,尤其是對成本友好的情況下,我們會大量使用Job、彈性執行個體、無服務應用等,例如渲染型的任務到達後啟動一個彈性的計算執行個體,執行完畢後立馬銷毀釋放;機器學習的訓練Job、事件驅動的無服務工作流、定期執行的Job(例如資源清理、容量檢查、安全掃描)等。這些應用通常生命周期極短(可能在秒級或毫秒級),Pull的定期模型極難去監控,一般都需要使用Push的方式,由應用主動推送監控資料。
為了應對這種短生命周期的應用,純Pull的系統都會提供一個中間層(例如Prometheus的Push Gateway):接受應用主動Push,再提供Pull的端口給監控系統。但這就需要額外多個中間層的管理和運維成本,而且由于是Pull模拟Push,上報的延遲會升高而且還需要即使清理這些立即消失的名額。
靈活性與耦合度
從靈活性上來講,Pull模式稍微有一些優勢,可以在Pull子產品配置到底想要哪些名額,對名額做一些簡單的計算/二次加工;但這個優勢也是相對的,Push SDK/Agent也可以去配置這些參數,借助于配置中心的存在,配置管理起來也是很簡單的。
從耦合度上講,Pull模型和後端的耦合度要低很多,隻需要提供一個後端可以了解的接口即可,具體連接配接哪個後端,後端需要哪些名額等不用關心,相對分工比較明确,應用開發者隻需要暴露應用自己的名額即可,由SRE(監控系統管理者)來擷取這些名額;Push模型相對來說耦合度要高一些,應用需要配置後端的位址以及鑒權資訊等,但如果借助于本地的Push Agent,應用隻需要Push本地位址,相對來說代價也并不大。
運維與成本對比
資源成本
從整體成本上講,兩種方式總體的差别不大,但從歸屬方角度來看:
- Pull模式核心消耗在監控系統側,應用側的代價較低
- Push模式核心消耗在推送和Push Agent端,監控系統側的消耗相比Pull要小很多
運維成本
從運維角度上講,相對而言Pull模式的代價要稍高,Pull模式需要運維的元件包括:各類Exporter、服務發現、PullAgent、監控後端;而Push模式隻需要運維:Push Agent、監控後端、配置中心(可選,部署方式一般是和監控後端一起)。
- 這裡需要注意的一點是,Pull模式由于是服務端向用戶端主動發起請求,網絡上需要考慮跨叢集連通性、應用側的網絡防護ACL等,相比Push的網絡連通性比較簡單,隻需要服務端提供一個可供各節點通路的域名/VIP即可。
Pull or Push如何選型
目前開源方案,Pull模式的代表Prometheus的家族方案(之是以稱之為家族,主要是預設單點的Prometheus擴充性受限,社群有非常多Prometheus的分布式方案,比如Thanos、VictoriaMetrics、Cortex等),Push模式的代表InfluxDB的TICK(Telegraf, InfluxDB, Chronograf, Kapacitor)方案。這兩種方案都有各自的優缺點,在雲原生的大背景下,随着Prometheus在CNCF、Kubernetes帶領下的大火,很多開源軟體都開始提供Prometheus模式的Pull端口;但同時還有很多系統本身設計之初就難以提供Pull端口,這些系統的監控相比而言使用Push Agent方式更為合理。
而應用本身到底該使用Pull還是Push一直沒有一個很好的定論,具體的選型還需要根據公司内部的實際場景,例如如果公司叢集的網絡很複雜,使用Push方式較為簡單;有很多短生命周期的應用,需要使用Push方式;移動端應用隻能用Push方式;系統本身就用Consul做服務發現,隻需要暴露Pull端口就可以很容易實施。
是以綜合考慮情況下對于公司内部的監控系統來說,應該同時具備Pull和Push的能力才是最優解:
- 主機、程序、中間件監控使用Push Agent
- Kubernetes等直接暴露Pull端口的使用Pull模式
- 應用根據實際場景選擇Pull or Push
SLS在Pull和Push上的政策
SLS目前支援日志(Log)、時序監控(Metric)、分布式鍊路追蹤(Trace)的統一存儲和分析。對于時序監控方案是相容Prometheus的格式标準,提供的也是标準的PromQL文法。面對數十萬SLS的使用者,應用場景可能會千差萬别,不可能用單一的Pull或Push來對應所有客戶需求。是以SLS在Pull和Push的選型上SLS并沒有走單一路線,而是相容Pull和Push模型。此外對于開源社群和Agent,SLS的政策是完全相容開源生态,而非自己去造一個閉合生态:
- Pull模型:完全相容Prometheus的Pull Scrap能力。可以使用Prometheus的Remote Write,讓Prometheus來做Pull的Agent;和Prometheus Scrap一樣能力的 VMAgent 也可以這樣使用;SLS自己的Agent Logtail也可以實作Prometheus的Scrap能力
- Push模型:目前業界的監控PushAgent生态最完善的當屬 Telegraf ,SLS的Logtail内置了Telegraf,可以支援所有的Telegraf的上百種監控插件
相比VMAgent、Prometheus這類Pull Agent以及原生Telegraf,SLS額外提供了最迫切的Agent配置中心和Agent監控能力,可以在服務端去管理每個Agent的采集配置以及監控這些Agent的運作狀态,盡可能降低運維管理代價。
是以實際使用SLS進行監控方案的搭建會非常簡單:
- 在SLS的控制台(Web頁面)去建立一個存儲監控資料的MetricStore
- 部署Logtail的Agent(一行指令)
- 在控制台上配置監控資料的采集配置(Pull、Push都可以)
總結
本文主要介紹了監控系統中最糾結的Pull or Push選擇問題,筆者結合數年的實際經驗以及遇到的各類客戶場景對Pull和Push的各類方向進行了比對,僅供大家在監控系統建設過程中參考,也歡迎大家留言和讨論。
對SLS技術感興趣的小夥伴們,可以關注:
- SLS(日志服務)雲原生觀測分析平台 https://www.aliyun.com/product/sls
- 知乎:智能日志分析專欄
- 更多SLS的系列直播與教育訓練視訊會同步到微信公衆号與B站,敬請留意
- https://blog.sflow.com/2012/08/push-vs-pull.html
- https://steve-mushero.medium.com/push-vs-pull-configs-for-monitoring-c541eaf9e927
- https://giedrius.blog/2019/05/11/push-vs-pull-in-monitoring-systems/
- https://docs.victoriametrics.com/vmagent.html
- https://github.com/influxdata/telegraf
- https://sls.aliyun.com/