本篇介紹深度學習在自然語言處理(NLP)中的應用,從詞向量開始,到最新最強大的BERT等預訓練模型,梗概性的介紹了深度學習近20年在NLP中的一些重大的進展
在深度學習之前,用于解決NLP問題的機器學習方法一般都基于淺層模型(如SVM和logistic 回歸),這些模型都在非常高維和稀疏的特征(one-hot encoding)上進行訓練和學習,出現了次元爆炸等問題難以解決。并且基于傳統機器學習的NLP系統嚴重依賴手動制作的特征,它們極其耗時,且通常并不完備。
而近年來,基于稠密向量表征的神經網絡在多種NLP任務上得到了不錯結果。這一趨勢取決了詞嵌入和深度學習方法的成功;并且深度學習使多級自動特征表征學習成為可能。是以,本文從詞的分布式表征開始介紹深度學習在NLP中的應用
分布式詞表征(詞向量)的實作
通常來講,在2003年的《A Neural Probabilistic Language Model》中Bengio等人提出了神經語言模型(NNLM),而它的副産品,詞向量,可以實作詞的分布式表征。該文通常被認為是深度學習在自然語言進行中應用的開始。提出伊始,由于屆時計算機計算能力的限制,該網絡并不能較好的得到訓練。是以,這一篇成果,在當時并沒有得到相當的關注
2008年Collobert和Weston展示了第一個能有效利用預訓練詞嵌入的研究工作,他們提出的神經網絡架構,構成了目前很多方法的基礎。這一項研究工作還率先将詞嵌入作為 NLP 任務的高效工具。
不過詞嵌入真正走向NLP主流還是Mikolov 等人在 2013 年做出的研究《Distributed Representations of Words and Phrases and their Compositionality》。
Mikolov 等研究者在這篇論文中提出了連續詞袋模型CBOW和 Skip-Gram 模型,通過引入負采樣等可行性的措施,這兩種方法都能學習高品質的詞向量
分布式的詞表征的一大好處是實作了語義的合成性,即兩個詞向量相加得到的結果是語義相加的詞,例如[man]+[royal]=[king]
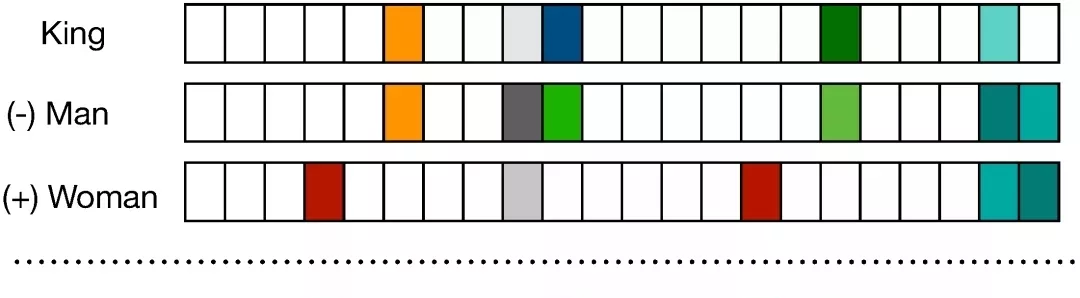
這種語義合成性的理論依據最近已經由Gittens et al. 在2017年給出,他們表示隻有保證某些特定的假設才能滿足語義合成性,例如詞需要在嵌入空間中處于均勻分布。
GloVe是另外一個很有名的獲得詞向量的方法,在有些情況下,CBOW和Skip-Gram采用的交叉熵損失函數有劣勢。是以GloVe采用了平方損失。同時,它基本上是一種基于詞統計的模型,它令詞向量拟合預先基于整個資料集計算得到的全局統計資訊,進而學習高效的詞表征
NLP中特征提取方法的進化
随着詞分布式表征的問題得到了有效的解決,人們開始思考如何提取詞序列中進階的語義資訊,然後才能将這些提取到的語義資訊,應用到下遊的NLP任務中,例如情感分析、問答系統、機器翻譯以及自動摘要等。
最早用來對自然語言詞序列進行特征提取的,其實是卷積神經網絡(CNN)。這主要歸因于卷積神經網絡在圖像領域取得的驕人成績。
使用 CNN 進行句子模組化可以追溯到Collobert和Weston在2008年的研究,他們使用多任務學習為不同的NLP任務輸出多個預測,如詞性标注、語塊分割、命名實體标簽和語義相似詞等。其中查找表可以将每一個詞轉換為一個使用者自定義次元的向量。是以通過查找表,n個詞的輸入序列 {s_1,s_2,... s_n } 能轉換為一系列詞向量 {w_s1, w_s2,... w_sn}。
在Collobert 2011年的研究中,他擴充了以前的研究,并提出了一種基于CNN的通用架構來解決大量NLP任務,這兩個工作都令NLP研究者嘗試在各種任務中普及 CNN架構。CNN具有從輸入句子抽取n-gram特征的能力,是以它能為下遊任務提供具有句子層面資訊的隐藏語義表征。
因為語言序列常常具有長程性,需要記憶很早時候的輸入資訊,CNN并不具備這種能力。這個時候,循環神經網絡(RNN)網絡被提出

RNN的思路是處理序列資訊。“循環”表示RNN模型對序列中的每一個執行個體都執行同樣的任務,并且權重共享,進而使輸出依賴于之前的計算和結果。
通常,RNN通過将token挨個輸入到循環單元中,來生成表示序列的固定大小向量。一定程度上,RNN對之前的計算有“記憶”,并在目前的進行中使用對之前的記憶。該模闆天然适合很多NLP 任務,如語言模組化、機器翻譯、語音識别、圖像字幕生成。是以近年來,RNN在NLP任務中逐漸流行。
但是RNN容易出現梯度消失和爆炸的問題,因而其改進版本LSTM和GRU被提出來了
LSTM比簡單RNN多了“遺忘門”,其獨特機制幫助該網絡克服了梯度消失和梯度爆炸問題。與原版RNN不同,LSTM允許誤差通過無限數量的時間步進行反向傳播。它包含三個門:輸入門、遺忘門和輸出門,并通過結合這三個門來計算隐藏狀态。另一個門控RNN變體是GRU,複雜度更小,其在大部分任務中的實驗性能與LSTM類似。GRU包括兩個門:重置門和更新門,并像沒有記憶單元的 LSTM那樣處理資訊流。是以,GRU不加控制地暴露出所有的隐藏内容。由于GRU的複雜度較低,它比LSTM更加高效。
在llya Sutskever等人2014年的研究《Sequence to Sequence Learning with Neural Networks》中,作者提出了一種通用深度LSTM編碼器-解碼器架構,可以實作序列之間的映射。使用一個LSTM将源序列編碼為定長向量,源序列可以是機器翻譯任務中的源語言、問答任務中的問題或對話系統中的待回複資訊。然後将該向量作為另一個 LSTM解碼器的初始狀态。在推斷過程中,解碼器逐個生成token,同時使用最後生成的token更新隐藏狀态。
傳統編碼器-解碼器架構的一個潛在問題是:有時編碼器會強制編碼可能與目前任務不完全相關的資訊。這個問題在輸入過長或資訊量過大時也會出現,選擇性編碼是不可能的。是以,能夠根據編碼器編碼内容動态解碼内容的注意力機制(Attention)得到提出。
《Neural Machine Translation by Jointly Learning to Align and Translate》首次将注意力機制應用到機器翻譯任務,尤其改進了在長序列上的性能。該論文中,關注輸入隐藏狀态序列的注意力信号由解碼器最後的隐藏狀态的多層感覺機決定。通過在每個解碼步中可視化輸入序列的注意力信号,可以獲得源語言和目智語言之間的清晰對齊。
但是RNN及其優化變種,因為都要按時序輸入,都存在編碼效率低下的問題。Transformer這種基于self-attention機制的強大特征提取器應運而生。《Attention Is All You Need》提出了Transformer,它完全去除了編碼步中的循環和卷積,僅依賴注意力機制來捕捉輸入和輸出之間的全局關系。是以,整個架構更加并行化,在翻譯、解析等任務上訓練得到積極結果所需的時間也更少。
NLP中的預訓練模型
訓練得到的詞向量表征的詞語之間的資訊其實有限。詞向量一個難以解決的問題就是多義詞的問題,例如“bank”在英文中有“河岸”和“銀行”兩種完全不同意思,但是在詞向量中确實相同的向量來表征,這顯然不合理。
2017年,為了解決這個問題,ELMO模型在“Deep contextualized word representation”被提出。
ELMO的本質思想是:用事先訓練好的語言模型學好一個單詞的Word Embedding,此時多義詞無法區分,不過這沒關系。在實際使用Word Embedding的時候,單詞特定的上下文就可以知道,這個時候模型可以根據上下文單詞的語義去調整單詞的Word Embedding表示,這樣經過調整後的Word Embedding更能表達在這個上下文中的具體含義,自然也就能克服多義詞的問題。
從ELMO開始,這種先預訓練,在實際應用時再fine-Tune的模式就開始流行起來了。我們再看ELMO,通過雙向語言模型,能夠學到較豐富的語義資訊。但其用的是LSTM作為特征抽取器,在特征抽取能力上較弱
2018年,Generative Pre-Training(GPT)采用單向語言模型,用Transformer作為特征抽取器,取得了非常不錯的效果,但由于主創人員營銷能力欠佳,并沒有像下面這一個主角一樣,在NLP領域掀起滔天巨浪。
2018年10月,谷歌推出BERT(Bidirectional Encoder Representation from Transformers)模型,重新整理了幾乎所有NLP任務的榜單,一時風頭無兩。仔細看BERT的實作,其與GPT的主要差别在于,BERT用的“雙向語言模型”,它通過MASK掉預料中的部分詞再重建的過程來學習預料中詞語序列中的語義表示資訊,同樣采用Transformer作為特征抽取器。BERT的出現,因其效果太好,幾乎讓其他所有的NLP工作都黯然失色。
2019年2月openAI用更大的模型,規模更大品質更好的資料推出了GPT2.0,其語言生成能力令人驚歎。
目前來看,出彩的工作都是基于BERT和GPT的改進工作。在2019年6月,XLNet: Generalized Autoregressive Pretraining for Language Understanding誕生,其基于BERT和GPT等兩類預訓練模型來進行改進,分别吸取了兩類模型的長處,獲得的很好的效果。
需要注意的是,所有的預訓練模型都是無監督的,這意味着,模型的資料來源是廉價而且數量巨大的。因為XLNET在訓練時一直是under-fitting的,是以即使是通過增加資料量,都還能提升NLP預訓練模型的效果。這無疑是振奮人心的