轉自dbaplus社群公衆号
作者:王康,唯品會資料平台進階開發工程師
GitHub 位址
https://github.com/apache/flink歡迎大家給 Flink 點贊送 star~
自 2017 年起,為保障内部業務在平時和大促期間的平穩運作,唯品會就開始基于 Kubernetes 深入打造高性能、穩定、可靠、易用的實時計算平台,現在的平台支援 Flink、Spark、Storm 等主流架構。
本文将分為五個方面,分享唯品會 Flink 的容器化實踐應用以及産品化經驗:
- 發展概覽
- Flink 容器化實踐
- Flink SQL 平台化建設
- 應用案例
- 未來規劃
一、發展概覽
1、叢集規模
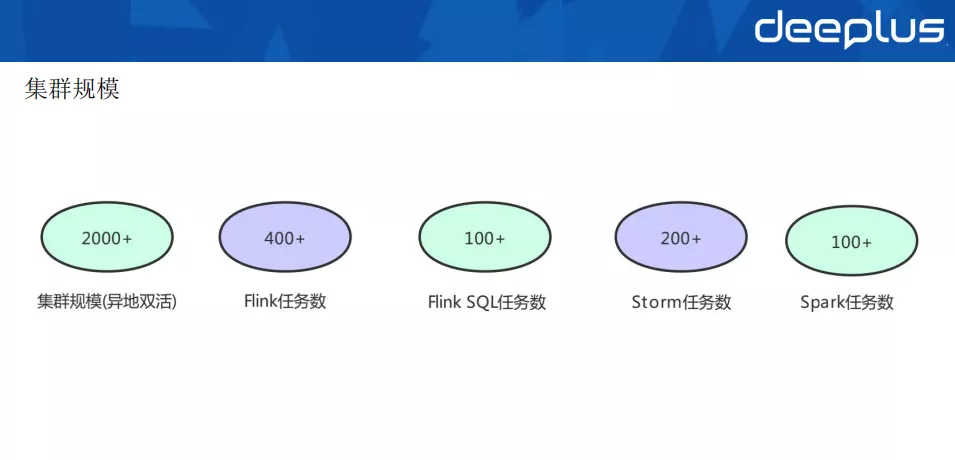
在叢集規模方面,我們有 2000+ 的實體機,主要部署 Kubernetes 異地雙活的叢集,利用 Kubernetes 的 namespaces,labels 和 taints 等實作業務隔離以及初步的計算負載隔離。
Flink 任務數、Flink SQL 任務數、Storm 任務數、Spark 任務數,這些線上實時應用加起來有 1000 多個。目前我們主要支援 Flink SQL 這一塊,因為 SQL 化是一個趨勢,是以我們要支援 SQL 任務的上線平台。
2、平台架構

我們從下往上進行解析實時計算平台的整體架構:
- 資源排程層(最底層)
實際上是用 deployment 的模式運作 Kubernetes 上,平台雖然支援 yarn 排程,但是 yarn 排程與批任務共享資源,是以主流任務還是運作在 Kubernetes 上的。并且,yarn 排程這一層主要是離線部署的一套 yarn 叢集。在 2017 年的時候,我們自研了 Flink on Kubernetes 的一套方案,因為底層排程分了兩層,是以在大促資源緊張的時候,實時跟離線就可以做一個資源的借調。
- 存儲層
主要用來支援公司内部基于 Kafka 的實時資料 vms,基于 binlog 的 vdp 資料和原生 Kafka 作為消息總線,狀态存儲在 HDFS 上,資料主要存入 Redis、MySQL、HBase、Kudu、HDFS、ClickHouse 等。
- 計算引擎層
主要是 Flink、Storm、Spark,目前主推的是 Flink,每個架構會都會支援幾個版本的鏡像以滿足不同的業務需求。
- 實時平台層
主要提供作業配置、排程、版本管理、容器監控、job 監控、告警、日志等功能,提供多租戶的資源管理(quota,label 管理)以及 Kafka 監控。資源配置也分為大促日和平常日,大促的資源和平常的資源是不一樣的,資源的權限管控也是不一樣的。在 Flink 1.11 版本之前,平台自建中繼資料管理系統為 Flink SQL 管理 schema;從 1.11 版本開始,則是通過 Hive metastore 與公司中繼資料管理系統融合。
- 應用層
主要是支援實時大屏、推薦、實驗平台、實時監控和實時資料清洗的一些場景。
二、Flink容器化實踐
1、容器化方案
上面是實時平台 Flink 容器化的架構圖。Flink 容器化其實是基于 Standalone 模式部署的。
我們的部署模式共有 Client、Job Manager、Task Manager 三個角色,每一個角色都會有一個 Deployment 來控制。
使用者通過平台上傳任務 jar 包、配置等,存儲于 HDFS 上。同時由平台維護的配置、依賴等也存儲在 HDFS 上,當 pod 啟動時,就會進行拉取等初始化操作。
Client 中主程序是一個由 go 開發的 agent,當 Client 啟動時,會首先檢查叢集狀态,當叢集準備好後,從 HDFS 上拉取 jar 包,再向這個叢集送出任務。Client 的主要任務是做容錯,它主要功能還有監控任務狀态,做 savepoint 等操作。
通過部署在每台實體機上的 smart-agent 采集容器的名額寫入 m3,以及通過 Flink 暴漏的接口将 metrics 寫入 prometheus,結合 grafana 展示。同樣通過部署在每台實體機上的 vfilebeat 采集挂載出來的相關日志寫入 es,在 dragonfly 可以實作日志檢索。
1)Flink 平台化
在實踐過程中,一定要結合具體場景和易用性,再去考慮做平台化工作。
2)Flink 穩定性
在我們應用部署以及運作過程中,異常是不可避免的,這時候平台就需要做一些保證任務在出現異常狀況後,依舊保持穩定性的一些政策。
-
pod 的健康和可用:
由 livenessProbe 和 readinessProbe 檢測,同時指定 pod 的重新開機政策,Kubernetes 本身可以做一個 pod 的拉起。
- Flink 任務産生異常時:
- Flink 有自已本身的一套 restart 政策和 failover 機制,這是它的第一層保障。
-
在 Client 中會定時監控 Flink 狀态,同時将最新的 checkpoint 位址更新到自己的緩存中,并彙報到平台,然後固化到 MySQL 中。當 Flink 無法再重新開機時,由 Client 重新從最新的成功 checkpoint 送出任務。這是它的第二層保障。
這一層将 checkpoint 固化到 MySQL 中後,就不再使用 Flink HA 機制了,少了 zk 的元件依賴。
- 目前兩層無法重新開機時或叢集出現異常時,由平台自動從固化到 MySQL 中的最新 checkpoint 重新拉起一個叢集,送出任務,這是它的第三層保障。
- 機房容災:
- 使用者的 jar 包,checkpoint 都做了異地雙 HDFS 存儲。
- 異地雙機房雙叢集。
2、Kafka 監控方案
Kafka 監控是任務監控裡非常重要的一個環節,整體的流程如下:
平台提供監控 Kafka 堆積,使用者在界面上,可以配置自己的 Kafka 監控,告知在怎樣的叢集,以及使用者消費 message 等配置資訊。可以從 MySQL 中将使用者 Kafka 監控配置提取後,再通過 jmx 監控 Kafka,這樣的資訊采集之後,寫入下遊 Kafka,再通過另一個 Flink 任務實時監控告警,同時将這些資料同步寫入 ck 裡面,進而回報給我們的使用者(這裡也可以不用 ck,用 Prometheus 去做監控也是可以的,但 ck 會更加适合),最後再用 Grafana 元件去展示給使用者。
三、Flink SQL 平台化建設
有了前面 Flink 的容器化方案之後,就要開始 Flink SQL 平台化建設了。大家都知道,這樣流式的 api 開發起來,還是有一定的成本的。 Flink 肯定是比 Storm 快的,也相對比較穩定、容易一些,但是對于一些使用者,特别是 Java 開發的一些同學來說,做這個是有一定門檻的。
Kubernetes 的 Flink 容器化實作以後,友善了 Flink api 應用的釋出,但是對于 Flink SQL 的任務仍然不夠便利。于是平台提供了更加友善的線上編輯釋出、SQL 管理等一棧式開發平台。
1、 Flink SQL 方案
平台的 Flink SQL 方案如上圖所示,任務釋出系統與中繼資料管理系統是完全解耦的。
1)Flink SQL 任務釋出平台化
在實踐過程中,需要考慮易用性,做平台化工作,主操作界面如下圖所示:
- Flink SQL 的版本管理、文法校驗、拓撲圖管理等;
- UDF 通用和任務級别的管理,支援使用者自定義 udf;
- 提供參數化的配置界面,友善使用者上線任務。
下圖是一個使用者界面配置的例子:
下圖是一個叢集配置的範例:
2)中繼資料管理
平台在 1.11 之前通過建構自己的中繼資料管理系統 UDM,MySQL 存儲 Kafka,Redis 等 schema,通過自定義 catalog 打通 Flink 與 UDM,進而實作中繼資料管理。
在 1.11 之後,Flink 內建 Hive 逐漸完善,平台重構了 Flink SQL 架構,并通過部署一個 SQL-gateway service 服務,中間調用自己維護的 SQL-Client jar 包,進而與離線中繼資料打通,實作了實時離線中繼資料的統一,為之後的流批一體打好了基礎。
在中繼資料管理系統建立的 Flink 表操作界面如下圖所示:建立 Flink 表的中繼資料,持久化到 Hive 裡,Flink SQL 啟動時從 Hive 裡讀取對應表的 table schema 資訊。
2、Flink SQL 相關實踐
平台對于官方原生支援或者不支援的 connector 進行整合和開發,鏡像和 connector,format 等相關依賴進行解耦,可以快捷的進行更新與疊代。
1)Flink SQL 相關實踐
Flink SQL 主要分為以下三層:
- connector 層
- 支援 VDP connector 讀取 source 資料源;
- 支援 Redis string、hash 等資料類型的 sink & 維表關聯;
- 支援 kudu connector & catalog & 維表關聯;
- 支援 protobuf format 解析實時清洗資料;
- 支援 vms connector 讀取 source 資料源;
- 支援 ClickHouse connector sink 分布式表 & 本地表高 TPS 寫入;
- Hive connector 支援數坊 Watermark Commit Policy 分區送出政策 & array、decimal 等複雜資料類型。
- runtime 層
- 主要支援拓撲圖執行計劃修改;
- 維表關聯 keyBy 優化 cache 提升查詢性能;
- 維表關聯延遲 join。
- 平台層
- Hive UDF;
- 支援 json HLL 相關處理函數;
- 支援 Flink 運作相關參數設定如 minibatch、聚合優化參數;
- Flink 更新 hadoop3。
2)拓撲圖執行計劃修改
針對現階段 SQL 生成的 stream graph 并行度無法修改等問題,平台提供可修改的拓撲預覽修改相關參數。平台會将解析後的 FlinkSQL 的 excution plan json 提供給使用者,利用 uid 保證算子的唯一性,修改每個算子的并行度,chain 政策等,也為使用者解決反壓問題提供方法。例如針對 ClickHouse sink 小并發大批次的場景,我們支援修改 ClickHouse sink 并行度,source 并行度 = 72,sink 并行度 = 24,提高 ClickHouse sink tps。
3)維表關聯 keyBy 優化 cache
針對維表關聯的情況,為了降低 IO 請求次數,降低維表資料庫讀壓力,進而降低延遲,提高吞吐,有以下三種措施:
下面是維表關聯 KeyBy 優化 cache 的圖:
在優化之前的時候,維表關聯 LookupJoin 算子和正常算子 chain 在一起,優化之間維表關聯 Lookup Join 算子和正常算子不 chain 在一起,将join key 作為 hash 政策的 key。
采用這種方式優化後,例如原來的 3000W 資料量維表,10 個 TM 節點,每個節點都要緩存 3000W 的資料,總共需要緩存 3 億的量。而經過 keyBy 優化之後,每個 TM 節點隻需要緩存 3000W/10 = 300W 的資料量,總共緩存的資料量隻有 3000W,這非常大程度減少了緩存資料量。
4)維表關聯延遲 join
維表關聯中,有很多業務場景,在維表資料新增資料之前,主流資料已經發生 join 操作,會出現關聯不上的情況。是以,為了保證資料的正确,将關聯不上的資料進行緩存,進行延遲 join。
最簡單的做法是,在維表關聯的 function 裡設定重試次數和重試間隔,這個方法會增大整個流的延遲,但主流 qps 不高的情況下,可以解決問題。
增加延遲 join 的算子,當 join 維表未關聯時,先緩存起來,根據設定重試次數和重試間隔進而進行延遲的 join。
四、應用案例
1、實時數倉
1)實時資料入倉
實時數倉主要分為三個過程:
- 流量資料一級 Kafka 進行實時資料清洗後,可以寫到二級清洗 Kafka,主要是 protobuf 格式,再通過 Flink SQL 寫入 Hive 5min 表,以便做後續的準實時 ETL,加速 ods 層資料源的準備時間。
- MySQL 業務庫的資料,通過 VDP 解析形成 binlog cdc 消息流,再通過 Flink SQL 寫入 Hive 5min 表,同時會送出到自定義分區,再把分區狀态彙報到服務接口,最後再做一個離線的排程。
- 業務系統通過 VMS API 産生業務 Kafka 消息流,通過 Flink SQL 解析之後寫入 Hive 5min 表。可以支援 string、json、csv 等消息格式。
使用 Flink SQL 做流式資料入倉是非常友善的,而且 1.12 版本已經支援了小檔案的自動合并,解決了大資料層一個非常普遍的痛點。
我們自定義分區送出政策,目前分區 ready 時候會調一下實時平台的分區送出 api,在離線排程定時排程通過這個 api 檢查分區是否 ready。
采用 Flink SQL 統一入倉方案以後,我們可獲得以下成果:
- 首先我們不僅解決了以往 Flume 方案不穩定的問題,使用者也可以實作自助入倉,大大降低入倉任務的維護成本,穩定性也可以得到保障。
- 其次我們還提升了離線數倉的時效性,從小時級降低至 5min 粒度入倉,時效性可以增強。
2)實時名額計算
- 實時應用消費清洗後 Kafka,通過 Redis 維表、api 等方式關聯,再通過 Flink window 增量計算 UV,持久化寫到 HBase 裡。
- 實時應用消費 VDP 消息流之後,通過 Redis 維表、api 等方式關聯,再通過 Flink SQL 計算出銷售額等相關名額,增量 upsert 到 kudu 裡,友善根據 range 分區批量查詢,最終通過資料服務對實時大屏提供最終服務。
以往名額計算通常采用 Storm 方式,這個方式需要通過 api 定制化開發,采用這樣 Flink 方案以後,我們可以獲得了以下成果:
- 将計算邏輯切到 Flink SQL 上,降低計算任務口徑變化快,解決修改上線周期慢等問題;
- 切換至 Flink SQL 可以做到快速修改,并且實作快速上線,降低了維護的成本。
3)實時離線一體化ETL資料內建
具體的流程如下圖所示:
Flink SQL 在最近的版本中持續強化了維表 join 的能力,不僅可以實時關聯資料庫中的維表資料,還能關聯 Hive 和 Kafka 中的維表資料,能靈活滿足不同工作負載和時效性的需求。
基于 Flink 強大的流式 ETL 的能力,我們可以統一在實時層做資料接入和資料轉換,然後将明細層的資料回流到離線數倉中。
我們通過将 presto 内部使用的 HyperLogLog(後面簡稱 HLL)實作引入到 Spark UDAF 函數裡,打通 HLL 對象在 Spark SQL 與 presto 引擎之間的互通。如 Spark SQL 通過 prepare 函數生成的 HLL 對象,不僅可以在 Spark SQL 裡 merge 查詢而且可以在 presto 裡進行 merge 查詢。
具體流程如下:
UV 近似計算示例:
2、實驗平台(Flink 實時資料入 OLAP)
唯品會實驗平台是通過配置多元度分析和下鑽分析,提供海量資料的 A/B-test 實驗效果分析的一體化平台。一個實驗是由一股流量(比如使用者請求)和在這股流量上進行的相對對比實驗的修改組成。實驗平台對于海量資料查詢有着低延遲、低響應、超大規模資料(百億級)的需求。
整體資料架構如下:
- 離線資料是通過 waterdrop 導入到 ClickHouse 裡面去;
- 實時資料通過 Flink SQL 将 Kafka 裡的資料清洗解析展開等操作之後,通過 Redis 維表關聯商品屬性,通過分布式表寫入到 ClickHouse,然後通過資料服務 adhoc 查詢,通過資料服務提供對外的接口。
業務資料流如下:
我們的實驗平台有一個很重要的 ES 場景,我們上線一個應用場景後,如果我想看效果如何,包括上線産生的曝光、點選、加購、收藏是怎樣的。我們需要把每一個資料的明細,比如說分流的一些資料,根據場景分區,寫到 ck 裡面去。
我們通過 Flink SQL Redis connector,支援 Redis 的 sink 、source 維表關聯等操作,可以很友善地讀寫 Redis,實作維表關聯,維表關聯内可配置 cache ,極大提高應用的 TPS。通過 Flink SQL 實作實時資料流的 pipeline,最終将大寬表 sink 到 CK 裡,并按照某個字段粒度做 murmurHash3_64 存儲,保證相同使用者的資料都存在同一 shard 節點組内,進而使得 ck 大表之間的 join 變成 local 本地表之間的 join,減少資料 shuffle 操作,提升 join 查詢效率。
五、未來規劃
1、提高Flink SQL易用性
Flink SQL 對于 Hive 使用者來說,使用起來還是有一點不一樣的地方。不管是 Hive,還是 Spark SQL,都是批量處理的一個場景。
是以目前我們的 Flink SQL 調試起來仍有很多不友善的地方,對于做離線 Hive 的使用者來說還有一定的使用門檻,例如手動配置 Kafka 監控、任務的壓測調優。是以如何能讓使用者的使用門檻降至最低,讓使用者隻需要懂 SQL 或者懂業務,把 Flink SQL 裡面的概念對使用者屏蔽掉,簡化使用者的使用流程,是一個比較大的挑戰。
将來我們考慮做一些智能監控,告訴使用者目前任務存在的問題,不需要使用者去學習太多的東西,盡可能自動化并給使用者一些優化建議。
2、資料湖CDC分析方案落地
一方面,我們做資料湖主要是為了解決我們 binlog 實時更新的場景,目前我們的 VDP binlog 消息流,通過 Flink SQL 寫入到 Hive ods 層,以加速 ods 層資料源的準備時間,但是會産生大量重複消息去重合并。我們會考慮 Flink + 資料湖的 cdc 入倉方案來做增量入倉。
另一方面我們希望通過資料湖,來替代我們 Kudu,我們這邊一部分重要的業務在用 Kudu。雖然 Kudu 沒有大量的使用,但鑒于 Kudu 的運維比一般的資料庫運維複雜得多、比較小衆,并且像訂單打寬之後的 Kafka 消息流、以及聚合結果都需要非常強的實時 upsert 能力,是以我們就開始調研 CDC+資料湖這種解決方案,用這種方案的增量 upsert 能力來替換 kudu 增量 upsert 場景。
Q&A
Q1:vdp connector 是 MySQL binlog 讀取嗎?和 canal是一種工具嗎?
A1 :vdp 是公司 binlog 同步的一個元件,将 binlog 解析之後發送到 Kafka。是基于 canal 二次開發的。我們定義了一個 cdc format 可以對接公司的 vdp Kafka 資料源,與 Canal CDC format 有點類似。目前沒有開源,使我們公司用的 binlog 的一個同步方案。
Q2 : uv 資料輸出到 HBase,銷售資料輸出到 kudu,輸出到了不同的資料源,主要是因為什麼采取的這種政策?
A2 :kudu 的應用場景沒有 HBase 這麼廣泛。uv 實時寫入的 TPS 比較高,HBase 比較适合單條查詢的場景,寫入 HBase 高吞吐 + 低延遲,小範圍查詢延遲低;kudu 的話具備一些 OLAP 的特性,可以存訂單類明細,列存加速,結合 Spark、presto 等做 OLAP 分析。
Q3 : 請問一下,你們怎麼解決的 ClickHouse 的資料更新問題?比如資料名額更新。
A3 : ck 的更新是異步 merge,隻能在同一 shard 同一節點同一分區内異步 merge,是弱一緻性。對于名額更新場景不太建議使用 ck。如果在 ck 裡有更新強需求的場景,可以嘗試 AggregatingMergeTree 解決方案,用 insert 替換 update,做字段級的 merge。
Q4:binlog 寫入怎麼保證資料的去重和一緻性?
A4 : binlog 目前還沒有寫入 ck 的場景,這個方案看起來不太成熟。不建議這麼做,可以用采用 CDC + 資料湖的解決方案。
Q5 : 如果 ck 各個節點寫入不均衡,怎麼去監控,怎麼解決?怎麼樣看資料傾斜呢?
A5 :可以通過 ck 的 system.parts 本地表監控每台機器每個表每個分區的寫入資料量以及 size,來檢視資料分區,進而定位到某個表某台機器某個分區。
Q6 : 你們在實時平台是如何做任務監控或者健康檢查的?又是如何在出錯後自動恢複的?現在用的是 yarn-application 模式嗎?存在一個 yarn application 對應多個 Flink job 的情況嗎?
A6 : 對于 Flink 1.12+ 版本,支援了 PrometheusReporter 方式暴露一些 Flink metrics 名額,比如算子的 watermark、checkpoint 相關的名額如 size、耗時、失敗次數等關鍵名額,然後采集、存儲起來做任務監控告警。
Flink 原生的 restart 政策和 failover 機制,作為第一層的保證。
在 Client 中會定時監控 Flink 狀态,同時将最新的 checkpoint 位址更新到自己的緩存中,并彙報到平台,固化到 MySQL 中。當 Flink 無法再重新開機時,由 Client 重新從最新的成功 checkpoint 送出任務。作為第二層保證。這一層将 checkpoint 固化到 MySQL 中後,就不再使用 Flink HA 機制了,少了 zk 的元件依賴。
目前兩層無法重新開機時或叢集出現異常時,由平台自動從固化到 MySQL 中的最新 chekcpoint 重新拉起一個叢集,送出任務,作為第三層保證。
我們支援 yarn-per-job 模式,主要基于 Flink on Kubernetes 模式部署 standalone 叢集。
Q7 : 目前你們大資料平台上所有的元件都是容器化的還是混合的?
A7 :目前我們實時這一塊的元件 Flink、Spark 、Storm、Presto 等計算架構實作了容器化,詳情可看上文 1.2 平台架構。
Q8 :kudu 不是在 Kubernetes 上跑的吧?
A8 :kudu 不是在 Kubernetes 上運作,這個目前還沒有特别成熟的方案。并且 kudu 是基于 cloudera manager 運維的,沒有上 Kubernetes 的必要。
Q9 : Flink 實時數倉次元表存到 ck 中,再去查詢 ck,這樣的方案可以嗎?
A9:這是可以的,是可以值得嘗試的。事實表與次元表資料都可以存,可以按照某個字段做哈希(比如 user_id),進而實作 local join 的效果。
活動推薦
阿裡雲基于 Apache Flink 建構的企業級産品-實時計算Flink版現開啟活動:
99元試用
實時計算Flink版(包年包月、10CU)即有機會獲得 Flink 獨家定制T恤;另包3個月及以上還有85折優惠!
了解活動詳情:
https://www.aliyun.com/product/bigdata/sc