作者:李輝
GitHub 位址
https://github.com/apache/flink歡迎大家給 Flink 點贊送 star~
在伴魚發展早期,出現了一系列實時性相關的需求,比如算法工程師期望可以拿到使用者的實時特征資料做實時推薦,産品經理希望資料方可以提供實時名額看闆做實時營運分析。
這個階段中台資料開發工程師主要是基于 Spark 實時計算引擎開發作業來滿足業務方提出的需求。然而這類作業并沒有統一的平台進行管理,任務的開發形式、送出方式、可用性保障等也完全因人而異。
伴随着業務的加速發展,越來越多的實時場景湧現出來,對實時作業的開發效率和品質保障提出了更高的要求。為此,我們從去年開始着手打造伴魚公司級的實時計算平台,平台代号 Palink,由 Palfish + Flink 組合而來。
之是以選擇 Flink 作為平台唯一的實時計算引擎,是因為近些年來其在實時領域的優秀表現和主導地位,同時活躍的社群氛圍也提供了非常多不錯的實踐經驗可供借鑒。目前 Palink 項目已經落地并投入使用,很好地滿足了伴魚業務在實時場景的需求。
核心原則
通過調研阿裡雲、網易等各大廠商提供的實時計算服務,我們基本确定了 Palink 的整個産品形态。同時,在系統設計過程中緊緊圍繞以下幾個核心原則:
- 極簡性:保持簡易設計,快速落地,不過度追求功能的完整性,滿足核心需求為主;
- 高品質:保持項目品質嚴要求,核心子產品思慮周全;
- 可擴充:保持較高的可擴充性,便于後續方案的疊代更新。
系統設計
平台整體架構
以下是平台整體的架構示意圖:
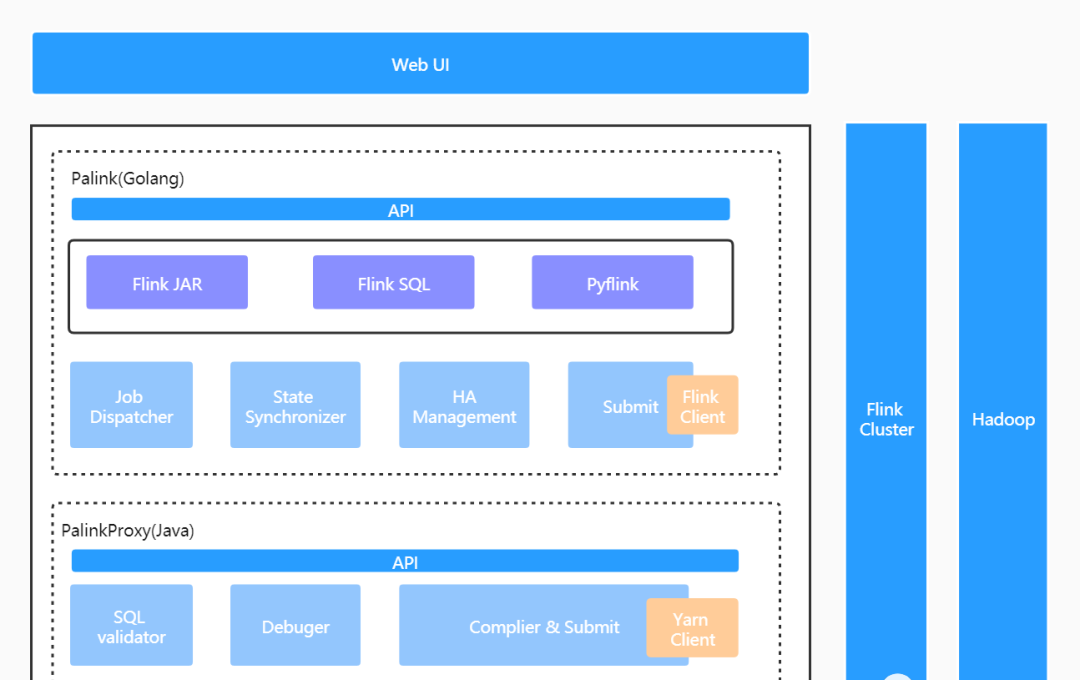
整個平台由四部分組成:
- Web UI:前端操作頁面;
- Palink (GO) 服務:實時作業管理服務,負責作業元資訊及作業生命周期内全部狀态的管理,承接全部的前端流量。包括作業排程、作業送出、作業狀态同步及作業 HA 管理幾個核心子產品;
- PalinkProxy(JAVA) 服務:SQL 化服務,Flink SQL 作業将由此子產品編譯、送出至遠端叢集。包括 SQL 文法校驗、SQL 作業調試及 SQL 作業編譯和送出幾個核心子產品;
- Flink On Yarn:基于 Hadoop Yarn 做叢集的資源管理。
這裡之是以将背景服務拆分成兩塊,并且分别使用 GO 和 JAVA 語言實作,原因主要有三個方面:
- 一是伴魚擁有一套非常完善的基于 GO 語言實作的微服務基礎架構,基于它可以快速建構服務并擁有包括服務監控在内的一系列周邊配套,公司目前 95% 以上的服務是基于此服務架構建構的;
- 二是 SQL 化子產品是基于開源項目二次開發實作的(這個在後文會做詳細介紹),而該開源項目使用的是 JAVA 語言;
- 三是内部服務增加一次遠端調用的成本是可以接受的。
這裡也展現了我們極簡性原則中對快速落地的要求。事實上,以 GO 為核心開發語言是非常具有 Palfish 特色的,在接下來伴魚大資料系列的相關文章中也會有所展現。
接下來本文将着重介紹 Palink 幾個核心子產品的設計。
作業排程&執行
後端服務接收到前端建立作業的請求後,将生成一條 PalinkJob 記錄和一條 PalinkJobCommand 記錄并持久化到 DB,PalinkJobCommand 為作業送出執行階段抽象出的一個實體,整個作業排程過程将圍繞該實體的狀态變更向前推進。其結構如下:
type PalinkJobCommand struct {
ID uint64 `json:"id"`
PalinkJobID uint64 `json:"palink_job_id"`
CommandParams string `json:"command_params"`
CommandState int8 `json:"command_state"`
Log string `json:"log"`
CreatedAt int64 `json:"created_at"`
UpdatedAt int64 `json:"updated_at"`
} 這裡并沒有直接基于 PalinkJob 實體來串聯整個排程過程,是因為作業的狀态同步會直接作用于這個實體,如果排程過程也基于該實體,兩部分的邏輯就緊耦合了。
排程流程
下圖為作業排程的流程圖:

palink pod 異步執行競争分布式鎖操作,保證同一時刻有且僅有一個執行個體擷取周期性監測權限,滿足條件的 Command 将直接被發送到 Kafka 待執行隊列,同時變更其狀态,保證之後不再被排程。此外,所有的 palink pod 将充當待執行隊列消費者的角色,并歸屬于同一個消費者組,消費到消息的執行個體将擷取到最終的執行權。
執行流程
作業的執行實則是作業送出的過程,根據作業類型的不同送出工作流有所差別,可細分為三類:
- Flink JAR 作業:我們摒棄了使用者直接上傳 JAR 檔案的互動方式。使用者隻需提供作業 gitlab 倉庫位址即可,打包建構全流程平台直接完成。由于每一個服務執行個體都内嵌 Flink 用戶端,任務是直接通過 Flink run 方式送出的。
- PyFlink 作業:與 Flink JAR 方式類似,少了編譯的過程,送出指令也有所不同。
- Flink SQL 作業:與上兩種方式差別較大。對于 Flink SQL 作業而言,使用者隻需送出相對簡單的 SQL 文本資訊,這個内容我們是直接維護在平台的元資訊中,故沒有和 gitlab 倉庫互動的地方。SQL 文本将進一步送出給 PalinkProxy 服務進行後續的編譯,然後使用 Yarn Client 方式送出。
Command 狀态機
PalinkJobCommand 的狀态流轉如下圖所示:
- UNDO:初始狀态,将被排程執行個體監測。
- DOING:執行中狀态,同樣會排程執行個體監測,防止長期處于進行中的髒狀态産生。
- SUCCESSED:執行成功狀态。随着使用者的後續行為,如重新送出、重新啟動操作,狀态會再次回到 UNDO 态。
- FAILED:執行失敗狀态。同上,狀态可能會再次回到 UNDO 态。
作業狀态同步
作業成功送出至叢集後,由于叢集狀态的不确定性或者其他的一些因素最終導緻任務異常終止了,平台該如何及時感覺到?這就涉及到我們即将要闡述的另一個話題 “狀态同步“。
狀态同步流程
這裡首先要回答的一個問題是:同步誰的狀态?
有過離線或者 Flink on yarn 開發經驗的同學一定知道,作業在部署到 yarn 上之後會有一個 application 與之對應,每一個 application 都有其對應的狀态和操作動作,比如我們可以執行 Yarn UI 上 Kill Application 操作來殺掉整個任務。
同樣的,當我們翻閱 Flink 官方文檔或者進入 Flink UI 頁面也都可以看到每一個任務都有其對應的狀态和一系列操作行為。最直接的想法肯定是以 Flink 任務狀态為準,畢竟這是我們最想拿到的。
但仔細分析,其實二者的狀态對于平台而言沒有太大差別,隻是狀态的粒度有所不同而已,yarn application 的狀态已經是對 Flink 狀态做了一次 state mapping。可是考慮到,Flink 在 HA 的時候,作業對外暴露的 URL 會發生變更,這種情況下隻能通過擷取作業對應的 application 資訊才能拿到最新的位址。
與此同時,一次狀态同步的過程不僅僅隻是希望拿到最新的狀态,對于任務的 checkpoint 等相關資訊同樣是有同步的訴求。看來二者的資訊在一次同步的過程中都需要擷取,最終的狀态同步設計如下:
前置流程和作業排程流程類似,有且僅有一個執行個體負責周期性監測工作,符合條件的 Job ID(注,并非所有的作業都用同步的必要,比如一些處于終态的作業)将發送到内部延遲隊列。之是以采用延遲隊列而非 Kafka 隊列,主要是為了将同一時間點批量同步的需求在一定時間間隔内随機打散,降低同步的壓力。最後,在擷取到作業的完整資訊後,再做一次 state mapping 将狀态映射為平台抽象的狀态類型。
由于狀态同步是周期性進行的,存在一定的延遲。是以在平台擷取作業詳情時,也會同步觸發一次狀态同步,保證擷取最新資料。
Job 狀态機
PalinkJob 的狀态流轉如下圖所示:
- DEPLOYING:作業初始狀态,将随着 PalinkJobCommand 的狀态驅動向 DEPLOY_SUCCESSED 和 DEPLOY_FAILED 流轉。
- DEPLOY_SUCCESSED:部署成功狀态,依賴作業「狀态同步」驅動向 RUNNING 狀态或者其他終态流轉。
- DEPLOY_FAILED:部署失敗狀态,依賴使用者重新送出向 DEPLOYING 狀态流轉。
- RUNNING:運作中狀态。可通過使用者執行暫停操作向 FINISHED 狀态流轉,或執行終止操作向 KILLED 狀态流轉,或因為内部異常向 FAILED 狀态流轉。
- FINISHED:完成狀态,作業終态之一。通過使用者執行暫停操作,作業将回到此狀态。
- KILLED:終止狀态,作業終态之一。通過使用者執行終止操作,作業将回到此狀态。
- FAILED:失敗狀态,作業終态之一。作業異常會轉為此狀态。
作業 HA 管理
解決了上述問題之後,另一個待讨論的話題便是 “作業 HA 管理”。我們需要回答使用者以下的兩個問題:
- 作業是有狀态的,但是作業需要代碼更新,如何處理?
- 作業異常失敗了,怎麼做到從失敗的時間點恢複?
Flink 提供了兩種機制用于恢複作業:Checkpoint 和 Savepoint,本文統稱為儲存點。Savepoint 可以看作是一種特殊的 Checkpoint ,隻不過不像 Checkpoint 定期的從系統中生成,它是使用者通過指令觸發的,使用者可以控制儲存點産生的時間點。
任務啟動時,通過指定 Checkpoint 或 Savepoint 外部路徑,就可以達到從儲存點恢複的效果。我們對于平台作業 HA 的管理也是基于這兩者展開的。下圖為管理的流程圖:
使用者有兩種方式來手動停止一個作業:暫停和終止。
- 暫停操作通過調用 Flink cancel api 實作,将觸發作業生成 Savepoint。
- 終止操作則是通過調用 yarn kill application api 實作,用于快速結束一個任務。
被暫停的作業重新開機時,系統将比較 Savepoint 和 Checkpoint 的生成時間點,按照最近的一個儲存點啟動,而當作業被重新送出時,由于使用者可能變更了代碼邏輯,将直接由使用者決定是否按照儲存點恢複。對于被終止的作業,無論是重新開機或者是重新送出,都直接采取由使用者決定的方式,因為終止操作本身就帶有丢棄作業狀态的色彩。
失敗狀态的作業是由于異常錯誤被迫停止的。對于這類作業,有三重保障:
- 一是任務自身可以設定重新開機政策自動恢複,外部平台無感覺;
- 二是,對于内部重新開機依舊失敗的任務在平台側可再次設定上層重新開機政策;
- 三是,手動重新開機或重新送出。僅在重新送出時,由使用者決定按照那種方式啟動,其餘場景皆按照最近的儲存點啟動。
任務 SQL 化
Flink JAR 和 PyFlink 都是采用 Flink API 的形式開發作業,這樣的形式必然極大地增加使用者的學習成本,影響開發的效率。需要不斷輸入和培養具有該領域開發技能的工程師,才能滿足源源不斷的業務需求。
而産品定位不僅僅是面向資料中台的開發工程師們,我們期望可以和離線目标使用者保持一緻,将目标群體滲透至分析人員乃至業務研發和部分的産品經理,簡單的需求完全可以自己動手實作。要達到這個目的,必然開發的形式也要向離線看齊,作業 SQL 化是勢在必行的。
我們期望 Flink 可以提供一種類似于 Hive Cli 或者 Hive JDBC 的作業送出方式,使用者無需寫一行 Java 或 Scala 代碼。查閱官方文檔,Flink 确實提供了一個 SQL 用戶端以支援以一種簡單的方式來編寫、調試和送出表程式到 Flink 叢集,不過截止到目前最新的 release 1.13 版本,SQL 用戶端僅支援嵌入式模式,相關的功能還不夠健全,另外對于 connector 支援也是有限的。是以,需要尋求一種更穩定、更高可擴充性的實作方案。
經過一番調研後,我們發現袋鼠雲開源的「FlinkStreamSQL」基本可以滿足我們目前的要求。此項目是基于開源的 Flink 打造的,并對其實時 SQL 進行了擴充,支援原生 Flink SQL 所有的文法。
實作機制
下圖為 Flink 官方提供的作業角色流程圖,由圖可知,使用者送出的代碼将在 Client 端進行加工、轉換(最終生成 Jobgraph )然後送出至遠端叢集。
那麼要實作使用者層面的作業 SQL 化,底層的實作同樣是繞不開這個流程。實際上 FlinkStreamSQL 項目就是通過定制化的手段實作了 Client 端的邏輯,可以将整個過程簡要地描述為:
建構 PackagedProgram
利用 PackagedProgramUtils 生成 JobGraph。
通過 YarnClusterDescriptor 送出作業。
其中,第一步是最關鍵的,PackagedProgram 的構造方法如下:
PackagedProgram.newBuilder()
.setJarFile(coreJarFile)
.setArguments(execArgs)
.setSavepointRestoreSettings(savepointRestoreSettings)
.build(); execArgs 為外部輸入參數,這裡就包含了使用者送出的 SQL。而 coreJarFile 對應的就是 API 開發方式時使用者送出的 JAR 檔案,隻不過這裡系統幫我們實作了。coreJarFile 的代碼對應項目中的 core module,該 module 本質上就是 API 開發方式的一個 template 模闆。module 内實作了自定義 SQL 解析以及各類 connector plugin 注入。更多細節可通過開源項目進一步了解。
定制開發
我們基于 FlinkStreamSQL 進行了二次開發,以滿足内部更多樣化的需求。主要分為以下幾點:
- 服務化:整個 SQL 化子產品作為 proxy 獨立部署和管理,以 HTTP 形式暴露服務;
- 支援文法校驗特性;
- 支援調試特性:通過解析 SQL 結構可直接擷取到 source 表和 sink 表的結構資訊。平台可通過人工構造或線上抓取源表資料的方式得到測試資料集,sink 算子被 localTest connector 算子直接替換,以截取結果資料輸出;
- 支援更多的 connector plugin,如 pulsar connector;
- 其他特性。
除了上文提到的一些功能特性,平台還支援了:
- DDL 語句注入
- UDF 管理
- 租戶管理
- 版本管理
- 作業監控
- 日志收集
這些點就不在本文詳細闡述,但作為一個實時計算平台這些點又是必不可少的。
線上效果
作業總覽
作業詳情
未來工作
随着業務的繼續推進,平台将在以下幾方面繼續疊代優化:
- 穩定性建設:實時任務的穩定性建設必然是未來工作中的首要事項。作業參數如何設定,作業如何自動調優,作業在流量高峰如何保持穩定的性能,這些問題需要不斷探索并沉澱更多的最佳實踐;
- 提升開發效率:SQL 化建設。盡管 SQL 化已初具雛形,但開發起來依舊具備一定的學習成本,其中最明顯的就是 DDL 的建構,使用者對于 source、sink 的 schema 并不清楚,最好的方式是平台可以和我們的中繼資料中心打通将建構 DDL 的過程自動化,這一點也是我們目前正在做的;
- 優化使用體驗:體驗上的問題在一定程度上也直接影響到了開發的效率。通過不斷收集使用者回報,持續改進;
- 探索更多業務場景:目前伴魚内部已開始基于 Flink 開展 AI 、實時數倉等場景的建設。未來我們将繼續推進 Flink 在更多場景上的實踐。
更多 Flink 相關技術交流,可掃碼加入社群釘釘大群~
活動推薦
阿裡雲基于 Apache Flink 建構的企業級産品-實時計算Flink版現開啟6月限時活動:
0元試用
實時計算Flink版(包年包月、10CU)即可有機會獲得 Flink 獨家定制T恤;另包3個月及以上還有85折優惠!
了解活動詳情:
https://www.aliyun.com/product/bigdata/sc