## 使用者福利
阿裡雲最新釋出業界首款雲原生多模資料庫Lindorm,新使用者可申請首月免費試用,擷取産品技術支援,請加入釘釘群:35977898,更多内容請[參考連結](https://www.aliyun.com/product/apsaradb/lindorm?spm=a2c6h.12873639.0.0.74c15ad4EXvmuV)
離線資料導出背景
數倉、資料湖中我們通常會談到明細事實資料和次元彙總資料,這些資料有着豐富的應用場景,比如根據ID查詢明細資料,流計算時根據ID與次元表Join補齊環境資訊,根據條件在大寬表裡檢索資料,或者多條件跨表Join進行圈人。這些場景通常具有高并發、實時響應的需求,是離線系統滿足不了的, 将離線資料導入到HBase/Cassandra、Solr/ES、Clickhouse、MySQL等線上系統是開源生态的成熟解決方案。但資料導入一直存在着成本高、一緻性差、穩定性不足等問題,并随着資料體量的增長而愈發明顯。本文介紹離線資料導入雲原生多模資料庫Lindorm,首先分析資料導入的問題和現狀,然後介紹Lindorm Bulkload批量導入技術的演進和優勢。
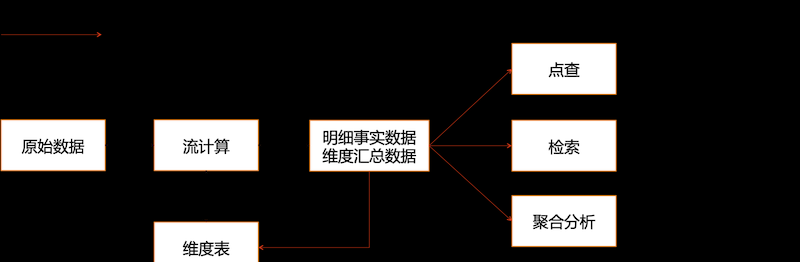
Lindorm是阿裡雲NoSQL 資料庫團隊推出的
雲原生多模資料庫産品,支援多類型、任意規模資料的低成本存儲處理和自适應彈性伸縮,服務于網際網路、IoT、車聯網、廣告、社交、監控、遊戲、風控等場景。Lindorm Bulkload是由LTS(Lindorm Tunnel Service)提供的低成本、高可靠、高性能的企業級批量導入服務,支援将MaxCompute、Hive等資料源中的資料導入Lindorm/HBase。利用Lindorm我們可以簡化上面的架構:

Lindorm 雲原生多模資料庫整體架構及背後的思考參考
乘雲觀海的新起點,新征程 —— 新Lindorm 2020離線資料導入線上系統存在的問題
成本高
離線導入通常是一種周期性的全量覆寫,全量意味着大規模資料,我們在生産環境中已經看到10TB級别日常導入任務。大的導入任務意味着密集的資源消耗,為了持久化要增加寫Log,為了可用性要多副本,為了事務要加鎖,再加上RPC、壓縮等開銷。對于線上系統的成本控制來說,不可預知的大流量非常可怕,我們必須預留更多的資源buffer,這往往意味着成本的浪費。除了淩晨或午高峰的定時型任務外,還會有營運活動臨時觸發的計算結果回流任務,這種任務對時效性要求很高,最多1-2小時内就需要完成大量資料的導入,時效性的要求提高,意味着對線上資源的挑戰更大。目前我們已經在用bulkload服務支援上億資料分鐘級别導入,普通的方式你可以通過線上叢集加資源來解決問題,但因為臨時的導入任務,使得整體叢集成本直線上升,使用率直線下降,這顯然讓人無法接受。
Lindorm采用
LSM Tree架構。讀取存儲到Lindorm裡的一條記錄需要合并多個SSTable後送出給用戶端。基于這樣的原理,Lindorm可以實作直接生成并向系統中“插入”新的SSTable,進而實作“新”資料的加載。開源生态中HBase也同樣具備該能力,可以利用TableOutputFormat在MapReduce中直接生成SSTable,并通過API直接加載SSTable到HBase。我們把這種導入方式叫做“Bulkload”,Bulkload可以有效降低寫入成本,其不需要日志、事務和RPC,并且SSTable生成過程可以與Lindorm分離使用獨立的資源,提高資源使用率。
資料一緻性差
離線導入通常是一種周期性的全量覆寫,另一項挑戰在于如何保證資料的一緻性。業務希望要麼看到前一天的資料,要麼看到今天的資料,如果讀到部分更新的資料會造成一定的問題,希望資料更新本身要麼成功,要麼全部復原。目前的系統僅能提供最終一緻性,有些甚至最終一緻也做不到。對于通過API寫入的方式,一種方式是先把資料複制到本地,确認成功後再解析并寫入系統達到最終一緻性。Bulkload本身可以做到原子加載,較長的寫入的過程隻是在生成檔案,用一個過程較短的load操作使得資料同時生效,幾乎不會出現中間狀态。但Bulkload不支援覆寫,比如某一行昨天有三個列,今天想更新為,但寫入的結果是,C列沒有被删除,這是由Lindorm/HBase自身的動态列特性造成的,沒有Overwrite整行的邏輯。即便支援了整行更新也還會存在漏洞,如果昨天的資料存在行Row1,今天的離線資料中沒有Row1,在Bulkload後昨天的Row1依然存在。
業務側可以通過切換表的方式來實作強一緻,每次導入資料前建立表T-new,導入成功後切換讀鍊路到T-new,删除舊表。但一套方案增加了建表、切流、删表等操作,業務運維起來非常麻煩。
影響線上系統穩定性
這裡我們不讨論導入系統本身的穩定性,你可能使用Sqoop、Spark、Hive等來完成資料導出,這些系統自身的穩定性不在讨論範圍内,我們探讨資料導入對線上系統的穩定性影響。
通過API大量的資料導入會直接争搶系統資源,造成查詢性能下降。回想我們開篇提到的明細事實資料和次元彙總資料,他們通常應用在推薦、風控、廣告等線上場景,查詢的波動或逾時就意味着資損。我們用Bulkload替換API導入,因為SSTable是用外部資源生成的,是以不會出現CPU、IO等資源的争搶,穩定性直接提升一個數量級。但Bulkload加載引發緩存命中率下降和緩存置換會造成一定程度的抖動,新SSTable加入後,新的查詢讀這個檔案産生冷讀,同時導緻緩存更新。Bulkload是全量更新,此時系統中存在兩份資料,但LSM-Tree結構需要讀取全部檔案進行Merge才能得到最終資料,讀的代價增加了。新的檔案加入會觸發Compaction,Compaction本身又會消耗CPU和IO資源,又會導緻緩存的更新。綜上所述,距離零線上影響還有很大的差距。
資料傾斜
資料傾斜是分布式系統常見問題之一,資料傾斜的痛在于很難去處理,重新負載均衡是一個耗時長、資源消耗大的過程。如果業務并發比較高就更慘了,因為大分區造成讀寫熱點使問題持續惡化,你可能有必要進行有損恢複來挽回局面。在離線資料同步線上系統的場景裡,通常是初始化時存在資料傾斜問題,但長期運作的作業也可能因為變化而出現問題。考慮初始化時第一次同步資料,線上系統的表需要設計合理的分區模式和分區數量,但“合理”不容易做到,現實中經常遇到的是客戶采用預設選擇,是以這個問題還是要由系統自己來徹底解決。采用Hash分片的方式一般比較均勻,但分片的數量不好定奪,擴容會帶來抖動,另外Hash會影響範圍掃描性能,不是萬金油。而如果采用Range分片,比如像HBase,一旦分區規則和資料分布不比對就會造成資料傾斜。
Lindorm Bulkload的優勢
Lindorm Bulkload是由LTS(Lindorm Tunnel Service)提供的低成本、高可靠、高性能的企業級批量導入服務,支援将MaxCompute、Hive等資料源中的資料導入Lindorm/HBase。
- 低成本:Bulklaod模式天然比API模式節省資源,無需日志、事務、RPC等方面的開銷。同時利用外部生成SSTable的特殊性,我們對SSTable Writer進行了優化,使其性能提升2倍以上
- 一緻性提升:我們把表切換的邏輯做到系統内部,對客戶透明,支援強一緻覆寫寫(即将上線)。對于同城多活的執行個體,我們支援多個Zone同時Load資料。
- 防導入抖動:我們提供了多級限速、本地化率、緩存更新優化等多種手段減少導入時的性能波動
- 反資料傾斜:可以自動檢測資料分布,實時調節目标表的分區,并做到分布式導入下的負載均衡
- 易用性:白屏化接入
- 可靠性:系統高可用,有完善的監控報警體系
Lindorm Bulkload的流程圖
同城多活導入
在同城多活場景下,資料需要導出到每一個Zone實作本地通路。N個Zone對應建立N個導出任務是一種解決方法,但這些任務之間很難協同在同一時間完成,造成資料不一緻問題。另外N個任務重複了N次計算浪費資源。Lindorm Bulkload支援在一個任務裡并發導出多個叢集,會先複制資料,确認所有叢集資料複制成功後再一起執行Load操作,可以把不一緻的視窗控制在秒級。另外Lindorm Bulkload實作了一個MultiClusterDataOutputFormat,把SSTable Writer編碼壓縮後的資料流複制到所有叢集,進而減少重複的SSTable計算。
強一緻覆寫更新(即将上線)
強一緻覆寫更新是指新導入的資料完全覆寫舊資料,使用者不會讀到部分更新的資料。我們通過新表舊表切換的方式來實作強一緻,新資料寫入新表,切換後新請求通路新表,舊表在無通路後删除。整體邏輯内置到系統對客戶透明。對于一些AI算法類的場景,可能希望資料回退到上一個版本,可以在資源回收筒直接恢複。
防導入抖動
客戶希望資料導入盡可能減少對線上通路的影響,這個方面我們做了一些針對優化。資料導入保障100%的本地化率,找到SSTable的所屬分區,進而找到其目前的計算節點,将一份資料複制到該節點的DN上。資料導入提供多級限速,第一層是網絡流量限速,第二層是SSTable加載數量限速,降低對讀請求延遲的影響。優化緩存汰換,加載新的檔案一定會導緻緩存變化,可能造成一個集中的汰換,我們在核心層面使這個汰換更加平滑和高效。
反資料傾斜
在HBase社群Bulkload方案中,源資料要先做分區排序,排序是為了更高效的生成SSTable,SSTable内部的資料是按主鍵排序的。分區一般采用和HBase表的分區對齊,這樣SSTable可以恰好的“插入”的分區内,如果SSTable跨越了兩個分區,那麼需要進行Split,這是一個耗時耗力的工作。Lindorm Bulkload在很長時間也采用的同樣方案,如下圖所示,一旦源資料的分布與目标表不一緻就會産生資料傾斜,導入任務會出現長尾,目标叢集也可能會出現大的分區,我們在上面章節已經說明了大分區的危害。
為解決這個問題Lindorm推出了Anti-DataSkew Bulkload,首先利用
Quantiles和
Mergeable Summaries算法對源資料進行均勻切分(MaxCompute的RangeCluster表已經支援),排序過程中的分區與目标表的分區解耦,消滅導入長尾。主動識别源資料與目标表分布不一緻,自動化調整目标表分區。假如目标表已經有大量資料,那麼調整過程的Split、Compaction耗時很長,此時利用Lindorm的級聯Split能力快速對分區進行Split。
性能優化
Lindorm Bulkload是LTS服務中的一項功能,LTS是獨立于Lindorm/HBase叢集之外的一個分布式系統,是以Lindorm Bulkload中最核心的SSTable Writer可專項優化。原生的SSTable Writer是面向KV的,每一個KV的寫入都會有很多次的比較、編碼。但Bulkload的上遊資料是以行為機關的,每一行由多個KV組成,并且有相同的時間戳,我們利用這一特性開發了RowAwareWriter,複用行内kv的可用結果,對于大寬表型的導入任務有成倍的優化效果。同時我們利用CPU的緩存來優化編碼壓縮中資料的複制過程。
總結
Lindorm Bulkload是由LTS(Lindorm Tunnel Service)提供的低成本、高可靠、高性能的企業級批量導入服務,支援将MaxCompute、Hive等資料源中的資料導入Lindorm/HBase。歡迎新使用者使用,也歡迎新老使用者提意見、提需求,您的鞭策是我們前進的動力:)
## 咨詢交流
歡迎加入Lindorm技術交流群
