概述
什麼是基數統計
基數是指集合中不重複元素的個數,在網站營運、流量分析時我們經常需要統計的UV(Unique Visitor),就是一種基數,在使用SQL查詢時,我們可以通過COUNT和DISTINCT這兩個函數的組合進行基數統計,下列SQL:
select count(distinct(seller_id)) from kylin_sales; 就是統計銷售事實表中賣家這一列的基數。
基數統計算法
基數統計最直覺的算法就是周遊集合中的所有元素,使用Set等資料結構記錄元素是否已出現,若未出現,則加一,采用這種算法,需要存儲集合中所有元素,這在大資料場景下需要占用較大的存儲空間,是以,對于如何壓縮存儲空間,提出了Bitmap(位圖)以及更進一步優化的RoaringBitmap資料結構存儲元素是否存在。使用Bitmap進行基數統計本質上還是一種精确統計方法,雖壓縮了存儲空間,但還是存儲了元素是否存在的明細資料,存儲空間随元素取值範圍線性增長,并且在統計多個集合合并的基數時,仍需周遊明細資料,是以在大資料場景下,提出了HyperLogLog等機率統計方法,在不儲存明細資料的前提下對基數進行近似估計,大大降低存儲空間、提高計算速度的同時,也能保證一定的準确度,達到性能和精确的平衡。
基數統計算法在Kylin中的應用
Kylin是一個開源、分布式的OLAP存儲和查詢引擎,其核心思想是基于Cube理論,将明細資料中的各列分為次元和量度,在次元上進行預先聚合,通過空間換時間,加速查詢。作為OLAP分析中的常見場景,Kylin也支援基數統計,包括基于RoaringBitmap的精确統計和基于HyperLogLog的近似統計。分析者在設計Cube中的量度時,可以引入COUNT_DISTINCT表達式,對某列進行基數統計預計算,儲存計算結果,而在查詢時,Kylin也提供了SQL化的查詢方式,通過COUNT和DISTINCT這兩個函數對于已預計算的某列進行基數查詢時,會命中預計算結果,在此基礎上,進行進一步合并,而無需周遊明細資料,進而大大提高查詢速度。
文章目錄
本文後續分以下幾個部分進行詳細介紹:
- 基于RoaringBitmap的精确統計算法;
- 基于HyperLogLog的近似統計算法;
- 如何在Kylin中進行基數統計;
- Kylin中基數統計的實作。
基于RoaringBitmap的精确統計算法
Bitmap
Bitmap(位圖)即使用一個比特數組表示一個集合中存在的元素,數組中的每一位表示一個元素是否存在,若該位為0,表示相應元素不存在,若該位為1,表示相應元素存在,是以,Bitmap數組長度即集合中元素取值範圍大小,數組中1的總數即集合基數。若集合中的元素類型為整數,且取值範圍為[0, 7],則可以使用1個位元組表示其Bitmap,例如,集合為{1, 4, 4, 7},則其Bitmap為10010010(則右至左依次表示1至8各元素),基數為3,另一個集合為{3, 3, 4},則其Bitmap為00011000,基數為2,兩個集合并集的Bitmap可以通過或操作計算:
$$
10010010 | 00011000 = 10011010
是以并集的基數為4,兩個集合交集的Bitmap可以通過與操作計算:
10010010 \& 00011000 = 00010000
是以交集的技術為1。若集合中的元素類型為整數,且取值範圍為[0, 100000000 - 1],則其Bitmap的大小為:
100000000/(8*1024*1024)=12M
是以,隻需要約12M就可以存儲取值範圍為1億的元素集合,降低存儲空間,但其在空間使用上仍存在以下問題:
- 對于每個次元均需要用一個Bitmap存儲元素集合(例如每天的通路使用者);
- 稀疏和稠密集合的Bitmap大小相同(例如某天的通路使用者很少,則其Bitmap中會填充大量0)。
RoaringBitmap
針對以上問題,2016年由S. Chambi、D. Lemire、O. Kaser等人在論文《Better bitmap performance with Roaring bitmaps》中提出了RoaringBitmap進行優化,RoaringBitmap的思路是:定義集合元素類型是32位無符号整數(即取值範圍為[0, $2^{32}$ - 1]),對集合中的每一個元素,根據其高16位進行分桶(分桶在論文中稱為container),是以,最多有65536($2^{16}$)個分桶,再将低16位存入相應的分桶中,而分桶的類型分為3種:
- Array Container,其資料結構為short類型數組,每個short類型儲存一個元素的低16位,數組初始長度為4,最大長度為4096,也就是說最多可儲存4096個元素,最大占用8KB(4096 * 2Byte),是以Array Container适合存儲稀疏資料,另外Array Container中的數組有序,便于二分查找;
- Bitmap Container,即上一節中的普通位圖,其資料結構為long類型數組,每個比特表示一個元素,數組固定長度為1024,也就是說可儲存目前分桶所有$2^{16}$個元素,固定占用8KB(1024 * 8Byte),是以Bitmap Container适合存儲稠密資料;
- Run Container,其資料結構為short類型數組,數組初始長度為4,Run Container采用行程長度編碼(Run Length Encoding)算法對桶中的元素進行壓縮,并将壓縮後的資料儲存在數組中。例如,桶中元素為2個連續整數序列{2, 3, 4, 5}和{15,16},則經過行程長度編碼後壓縮成兩個二進制組{2, 3}和{15, 1},分别表示從2開始連續遞增3次、從15開始遞增1次,是以,Run Container适合存儲連續資料。
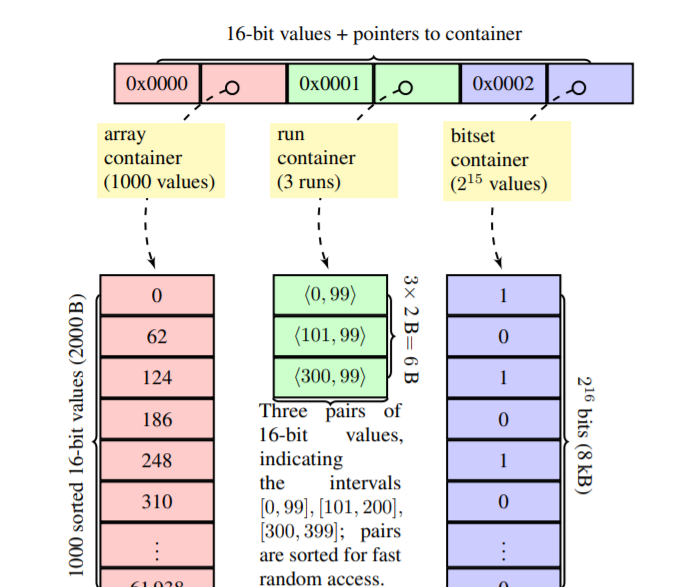
圖1 RoaringBitmap示例
圖1是官方論文中的一個RoaringBitmap示例,其中,第一個分桶儲存高位均為0x0000,低位是從0開始、按62連續遞增的1000個整數,該分桶元素個數不足4096,是以分桶類型采用Array Container,占用2000Byte,第二個分桶儲存高位均為0x0001,低位是[0, 99]、[101, 99]、[300, 99]這三個範圍的連續整數序列,是以分桶類型采用Run Container,占用6Byte,第三個分桶儲存[2 $2^{16}$, 3 $2^{16}$)範圍内的所有奇數,即高位均為0x0002,低位是從0開始,按2連續遞增的$2^{15}$個整數,該分桶元素個數超過4096,是以分桶類型采用Bitmap Container,占用8KB。
RoaringBitmap各分桶所采用的類型不是一成不變的,會根據分桶記憶體儲資料的變化動态調整,當分桶不存在、需要初始建立時,若隻插入一個元素,則預設采用Array Container存儲,若插入多個元素,則分析采用Array Container和Run Container分别占用的空間,選擇占用空間小的類型進行存儲,當Array Container的元素個數超過4096時,則會自動轉化成Bitmap Container,這樣使得各分桶占用空間始終不會超過8KB。
綜上,RoaringBitmap在分桶中的資料較稀疏時,采用變長數組存儲資料(最大不超過8KB),在分桶中的資料較稠密時,采用定長數組存儲資料(固定大小8KB),在分桶中的資料較連續時,采用行程長度編碼壓縮資料,通過針對不同的資料,采用不同的存儲方式,最大限度地節省存儲空間。
RoaringBitmap官方提供了多種語言的實作,可以很友善地在工程中引入、使用,其Java版本Maven坐标如下所示:
<dependencies>
<dependency>
<groupId>org.roaringbitmap</groupId>
<artifactId>RoaringBitmap</artifactId>
<version>[0.6,)</version>
</dependency>
</dependencies> 基于HyperLogLog的近似統計算法
抛硬币遊戲
首先通過抛硬币遊戲闡述HyperLogLog算法的基本思想,但不作嚴格的數學推導。假設抛硬币得到正面和反面的機率分别為0.5,在一個回合中不停抛硬币,直至得到正面,那麼抛一次就得到正面的機率為0.5(一次正面),抛兩次得到正面的機率為$0.5^2$(一次正面,一次反面),抛k次得到正面的機率為$0.5^k$(k-1次反面,1次正面),是以,每個回合是一個伯努利過程。
定義X為n個回合中,每個回合抛硬币直至得到正面次數的最大值。首先,一個回合至少抛k+1次才得到正面的機率為$0.5^k$(前k次均為反面),那麼,一個回合至多抛k次就能得到正面的機率為1-$0.5^k$,而所有n個回合均至多抛k次就能得到正面的機率為:
P(X\leq k)=(1-0.5^k)^n
同理,所有n個回合均至多抛k-1次就能得到正面的機率為:
P(X\leq k-1)=(1-0.5^{k-1})^n
那麼,所有n個回合至少有一次抛硬币的次數大于或等于k次的機率為:
P(X\geq k)=1-(1-0.5^{k-1})^n
從$P(X\leq k)$和$P(X\geq k)$中可以看出,當$n\gg 2^k$時,$P(X\leq k)$趨近為0,當$n\ll 2^k$時,$P(X\geq k)$也趨近為0。若k~max~為實際n個回合中抛硬币次數最大值,假設$n\gg 2^{k_{max}}$,那麼k~max~為目前值的機率趨近為0(從$P(X\leq k)$分析k~max~應該比目前值更大),假設假設$n\ll 2^{k_{max}}$,那麼$k_{max}$為目前值的機率也趨近為0(從$P(X\geq k)$分析k~max~應該比目前值更小),是以,可以用$2^{k_{max}}$作為n的粗略估計。
基于上述思想,對于集合中的元素,我們可以使用哈希函數将其映射為整數(即二進制序列),然後計算二進制序列中從左至右第一個1的位置序号,每次計算過程可以類比于一次抛硬币,第一個1的位置序号即抛硬币直至得到正面的次數,若集合基數為n,則有n個回合,記$k_{max}$為第一個1的位置序号最大值,那麼可以用$2^{k_{max}}$作為n的粗略估計。
HyperLogLog
在上節算法思想的基礎上,P. Flajolet在論文《LogLog counting of large cardinalities》和《HyperLogLog: The analysis of a near-optimal cardinality estimation algorithm》中先後提出了LogLog和HyperLogLog算法進行優化,算法的優化包括引入分桶,
1用一個理想的哈希函數,對資料流中的每一個元素求出一個哈希值
如果使用long來存儲哈希值,則該哈希函數需将2e64個不同值均勻映射到0~2e64-1上
2對每個哈希值,取最後p位來決定桶序号
3 在剩下的(64-p)位中找到第一個1出現的位置,如果大于桶中現有值,則更新
4 所有元素處理完畢後,求所有桶中的值的調和平均數
調和平均數是将所有數值取倒數并求其算法平均數後,再将此算數平均數取倒數而得
5乘以m得到最後結果E
比如一個示例如下所示:
如何在Kylin中進行基數統計
資料模型
作為OLAP分析中的常見場景,Kylin也支援基數統計,包括基于RoaringBitmap的精确統計和基于HyperLogLog的近似統計。這裡,先介紹一下Kylin的官方資料模型,并以此模型作為示例介紹如何在Kylin中進行基數統計。

圖2 資料模型,包含1張事實表和4張次元表
官方資料模型為雪花模型,如圖2所示,包含1張事實表和4張次元表:
- KYLIN_SALES,銷售事實表;
- KYLIN_ACCOUNT,使用者次元表;
- KYLIN_CAL_DT,日期次元表;
- KYLIN_CATEGORY_GROUPING,類别次元表
- KYLIN_COUNTR,國家次元表。
如果從銷售事實表中查詢共有多少賣家(即賣家這一列的基數),則執行下列SQL:
select count(distinct(seller_id)) from kylin_sales; Cube設計
Kylin的核心思想是在資料模型的基礎上設計Cube,在次元上進行預先聚合,通過空間換時間,這裡略過次元的設計,在量度上的設計上,可以選擇“COUNT_DISTINCT”表達式,并標明參數類型為銷售事實表中的seller_id這一列,而在具體的傳回類型上,目前Kylin共支援5種基數統計方式,其中1種是基于RoaringBitmap的精确統計,另外4種均是基于HyperLogLog的近似統計,但分桶數不同,随分桶數的增加,精度不斷提高,而占用空間也不斷增加,表1列出了這5種方式。
圖3 COUNT_DISTINCT類型量度設定
表1 5種基數統計方式的占用空間和誤差機率
| 傳回類型 | 每行占用空間 | 誤差機率 |
|---|---|---|
| 随基數變化,一般是HLLC的若幹倍 | 精确 | |
| HLLC 10 | 1KB | <9.75% |
| HLLC 12 | 4KB | <4.88% |
| HLLC 14 | 16KB | <2.44% |
| HLLC 15 | 32KB | <1.72% |
| HLLC 16 | 64KB | <1.22% |
另外,不管采用哪種方式,基數統計與其他類型量度相比,均需要占用較多的存儲空間,而在實際存儲時,量度是作為HBase KV存儲模型中的Value來存儲的,HBase的Value可以劃分為多個列族,各列族資料儲存在獨立的HFile檔案中,是以,Kylin官方建議将基數統計量度設定在單獨的列族中,其資料與其他類型量度隔離,這樣可以減少查詢其他量度時掃描資料的大小,提高查詢速度。
圖4 列族設定
另外,采用Bitmap方式時,若選擇的字段類型非整型,則需要另外建構字典,将原始字段值轉化為整型值,基于整型值建構Bitmap。目前Kylin提供兩種字典格式,即Global Dictionary和Segment Dictinonary,顧名思義,Global Dictionary是全局字典,被所有Segment共享,是以支援跨Segment做“COUNT_DISTINCT”操作,但單個字典占用空間大,而Segment Dictionary基于某個Segment的值建構,是以不支援跨Segment操作,但單個字典占用空間小,如果Cube沒有劃分Segment或是查詢時能嚴格保證按照Segment分區字段進行group by,則最好使用Segment Dictionary,避免單個字典過大的問題。
圖5 字典設定
查詢
在設計Cube後,可以基于原始資料進行Cube建構用于後續查詢。Kylin提供了SQL化的查詢方式,并支援多種查詢入口,包括WEB控制台、REST API、JDBC驅動、ODBC驅動等,表是對于示例SQL,分别直接從Hive查詢和查詢命中Cube的效果,直接從Hive查詢,耗時較高,但結果精準,查詢命中采用Bitmap方式進行基數統計的Cube,耗時較少,且結果精準,但Cube占用空間較大,查詢命中采用HLLC 10方式進行基數統計的Cube,耗時最少,Cube占用空間較小,但結果近似。
表2 不同查詢方式的耗時和結果
| 查詢方式 | Cube占用空間 | 查詢耗時 | 查詢結果 |
|---|---|---|---|
| 直接從Hive查詢 | 無 | 15.296秒 | 1000 |
| 查詢命中采用Bitmap方式進行基數統計的的Cube | 115.48MB | 0.075秒 | |
| 查詢命中采用HLLC 10方式進行基數統計的Cube | 93.39M | 0.056秒 | 955 |
Kylin中基數統計的實作
整體構架
Kylin的系統架構如圖6所示,它依賴大資料基礎設施HBase、Spark、Hadoop等實作分布式的存儲和計算,并基于這些基礎設施,設計了建構引擎和查詢引擎分别實作資料的建構和查詢。在建構引擎部分,Kylin支援使用MapReduce、Spark或Flink對來自Hive或Kafka的原始明細資料建構Cube,圖7是一個Cube示例,從下到上由多個Cuboid構成,最下層的Cuboid按所有次元對原始明細資料進行聚合,往上各Cuboid在下層Cuboid的基礎上,選取一個次元進行上卷,直至最上層的Cuboid不包含任何次元對資料進行聚合,是以,理論上n個次元的Cube包含2^n^個Cuboid,實際上Kylin會根據一定的規則進行剪枝,在減少資料規模的同時保證查詢性能。另外,在實體存儲Cube時,由于Cube可以按照時間等次元增量建構,是以Cube可以按分區字段劃分為多個Segment,每個Segment對應于一張HBase表,Cube中每一條記錄對應到HBase表的一行,次元和量度分别對應行的Key和Value。在查詢引擎部分,Kylin使用Calcite實作SQL的解析、優化和執行,将SQL查詢轉化為對存儲在HBase中的Cube資料的掃描,如果SQL能直接命中已預聚合資料,則直接傳回,否則在已聚合資料基礎上進行實時聚合,但相對于對原始明細資料進行臨時聚合,資料規模已大大減少,是以能實作亞秒級的線上OLAP分析。
圖6 Kylin整體架構
圖7 Cube示例
中繼資料
在設計Cube後,Kylin會将Cube中繼資料儲存至HBase kylin_metadata表中,每個Cube中繼資料包括次元、量度、rowkey、字典、聚合組等資訊,以下是采用Bitmap方式進行基數統計的Cube的部分中繼資料資訊:
{
"name": "kylin_sales_cube_bitmap",
"measures": [{
"name": "SELLER_CNT_BITMAP",
"function": {
"expression": "COUNT_DISTINCT",
"parameter": {
"type": "column",
"value": "KYLIN_SALES.SELLER_ID"
},
"returntype": "bitmap"
}
}],
"dictionaries": [{
"column": "KYLIN_SALES.SELLER_ID",
"builder": "org.apache.kylin.dict.GlobalDictionaryBuilder",
"cube": null,
"model": null
}],
"hbase_mapping": {
"column_family": [{
"name": "F2",
"columns": [{
"qualifier": "M",
"measure_refs": ["SELLER_CNT_BITMAP", "TOP_SELLER"]
}]
}]
}
} 其中,“measures”部分是量度資訊,“dictionaries”部分是字典資訊,“hbase_mapping”部分是列族資訊,後續Kylin在建構和查詢Cube時,都會依賴這份中繼資料。中繼資料在加載進記憶體時,會被反序列化為CubeDesc對象,該類及其部分關聯、依賴類的類圖如圖8所示,其中,,“dictionaries”部分反序列化為DictionaryDesc對象清單,“hbase_mapping”部分反序列化為HBaseMappingDesc對象,“measures”部分反序列化為MeasureDesc對象清單,“measures”中的“function”部分反序列化為FunctionDesc對象。
圖8 中繼資料類圖
FunctionDesc對象關聯了核心接口MeasureType,這個接口針對不同類型的量度有相應的實作,FunctionDesc通過工廠模式根據中繼資料中的expression和returntype擷取相應的MeasureType實作,代碼如下:
measureType = MeasureTypeFactory.create(getExpression(), getReturnDataType()); 對于expression為“COUNT_DISTINCT”、returntype為“bitmap”,相應的MeasureType實作為BitmapMeasureType,對于expression為“COUNT_DISTINCT”、returntype為“hllc(x)”,相應的MeasureType實作為HLLCMeasureType。MeasureType定義了兩個核心方法,代碼如下所示:
abstract public MeasureIngester<T> newIngester();
abstract public MeasureAggregator<T> newAggregator(); 其中,第一個方法用于建立MeasureIngester對象,該對象作用是從原始明細資料生成聚合對象,比如BitmapMeasureType中的MeasureIngester實作會從原始明細資料生成Bitmap,第二個方法用于建立MeasureAggregator對象,該對象作用是在聚合對象的基礎上進行聚合。進一步分析源碼,BitmapMeasureType和HLLCMeasureType的聚合對象分别是BitmapCounter和HLLCCounter,而BitmapCounter是委托給RoaringBitmap的官方Java實作生成Bitmap并進行多個Bitmap的合并,HLLCCounter則是由Kylin自己實作了HyperLogLog算法。後續在建構和查詢階段,Kylin均是通過量度類型擷取相應的MeasureType實作,再擷取相應的MeasureIngester和MeasureAggregator實作完成聚合對象的建立和聚合等操作,展現高内聚、低耦合的設計原則。
建構實作
Kylin的Cube建構流程主要包括以下5個步驟:
- 根據資料模型将Hive中的事實表和次元表關聯,建立中間寬表;
- 對中間寬表進行統計,并對部分字段建立字典,便于後續加速查詢;
- 根據Cube定義,基于中間寬表和字典,建構Cube;
- 建立HTable,并将建構好的Cube資料轉化為HFile,加載到HBase中;
- 更新Cube狀态,使建構後的資料生效。
在另一篇文章中已詳細分析其中的實作細節。Kylin支援使用MapReduce、Spark或Flink進行資料建構,以Spark建構方式為例,如圖所示,使用分層建構算法,首先執行mapToPair操作,将原始明細資料編碼為KV類型,key是次元值經編碼後組成的rowkey,value是量度經過轉化、編碼後的二進制資料,這步操作完成後,将獲得一個編碼後的中間RDD,随後對中間RDD進行reduceByKey操作,聚合得到RDD-1,也就是Base Cuboid。因為Base Cuboid向上有n個子Cuboid,是以在RDD-1的基礎上執行flatMap操作映射到各子Cuboid,再執行reduceByKey操作在各次元上進行上卷得到子Cuboid,flatMap和reduceByKey這兩個操作會逐層循環執行直至把所有層的Cuboid計算完成。每步生成的RDD會儲存至HDFS中,後續被轉化為HFile并加載到HBase。定義Spark建構任務的代碼在SparkCubingByLayer中,這裡隻再說明和“COUNT_DISTINCT”操作相關的兩步處理,一是在讀取原始明細資料生成編碼後的中間RDD時,其量度編碼實際是調用了各量度類型對應的MeasureIngester的valueOf方法,例如BitmapMeasureType中的MeasureIngester實作在valueOf方法中會傳回BitmapCounter對象(即Bitmap),代碼如下:
public Object[] buildValueObjects(String[] flatRow) {
Object[] measures = new Object[cubeDesc.getMeasures().size()];
for (int i = 0; i < measures.length; i++) {
String[] colValues = kvBuilder.buildValueOf(i, flatRow);
MeasureDesc measure = measureDescList.get(i);
measures[i] = aggrIngesters[i].valueOf(colValues, measure, dictionaryMap);
}
return measures;
} 二是在通過reduceByKey操作進行聚合時,實際也是調用了各量度類型對應的MeasureAggregator的aggregate方法,例如BitmapAggregator的aggregate方法會通過BitmapCounter對象的或操作進行聚合,代碼如下:
@Override
public Object[] call(Object[] input1, Object[] input2) throws Exception {
if (initialized == false) {
synchronized (SparkCubingByLayer.class) {
if (initialized == false) {
init();
initialized = true;
}
}
}
Object[] result = new Object[measureNum];
aggregators.aggregate(input1, input2, result);
return result;
} 查詢實作
Kylin的SQL解析和執行是基于Calcite實作的,其流程包括以下5個步驟:
- 将SQL解析成抽象文法樹;
- 對抽象文法樹進行校驗;
- 将抽象文法樹解析成關系代數表達式;
- 對關系代數表達式進行優化,在保持語義不變的前提下,轉化為較優的表達式;
- 将優化後的關系代數表達式轉化為實體執行計劃并執行,傳回最終的結果。
在另一篇文章中已詳細分析其中的實作細節,這裡隻列出示例SQL經過Calcite解析後得到的執行計劃:
OLAPAggregateRel(group=[{}], EXPR$0=[COUNT(DISTINCT $0)], ctx=[]): rowcount = 1.0, cumulative cost = {10.05625 rows, 5.050000000000001 cpu, 0.0 io}, id = 38
OLAPProjectRel(SELLER_ID=[$6], ctx=[]): rowcount = 100.0, cumulative cost = {10.0 rows, 5.050000000000001 cpu, 0.0 io}, id = 36
OLAPTableScan(table=[[DEFAULT, KYLIN_SALES]], ctx=[], fields=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]): rowcount = 100.0, cumulative cost = {5.0 rows, 5.050000000000001 cpu, 0.0 io}, id = 0 執行時,Kylin會根據解析出的表名、次元、量度等資訊,通過一定的規則,路由到相應的Cube,并進一步定位從哪些Cuboid中查詢資料(示例SQL中沒有次元,是以可以從盡量上層的Cuboid中查詢),同時會判斷是否需要作存儲端的實時聚合,随後,Kylin會向Cube各Segment所對應的HBase表發起資料掃描請求,并基于協處理器在存儲端作實時聚合,以減少資料在網絡中的傳輸。這裡,隻再說明和“COUNT_DISTINCT”操作相關的兩處處理,一是在存儲端,GTAggregateScanner會通過裝飾者模式對掃描出的原始資料作實時聚合,而聚合實際仍是調用了和各量度類型對應的MeasureAggregator實作所提供的aggregate方法,代碼如下所示:
@Override
public Iterator<GTRecord> iterator() {
long count = 0;
for (GTRecord r : inputScanner) {
//check limit
boolean ret = aggrCache.aggregate(r);
if (!ret) {
logger.info("abort reading inputScanner because storage push down limit is hit");
break;//limit is hit
}
count++;
}
logger.info("GTAggregateScanner input rows: " + count);
return aggrCache.iterator();
} 二是在查詢引擎側,Kylin在OLAPAggregateRel中重建了AggregateCall算子,代碼如下所示:
// 從各量度類型中擷取其AggrFunction類,例如BitmapMeasureType的AggrFunction類包括BitmapDistinctCountAggFunc、BitmapIntersectDistinctCountAggFunc和BitmapIntersectValueAggFunc,分别用于COUNT_DISTINCT、INTERSECT_COUNT和INTERSECT_VALUE場景
Map<String, Class<?>> udafMap = func.getMeasureType().getRewriteCalciteAggrFunctions();
if (func.isCount()) {
newAgg = SqlStdOperatorTable.SUM0;
} else if (udafMap != null && udafMap.containsKey(callName)) {
// 對于非COUNT場景,建立自定義SqlAggFunction類執行個體,其中主要是通過反射擷取AggrFunction類中init、add和result方法,用于Calcite運作時,調用相應方法進行再次聚合和擷取結果
newAgg = createCustomAggFunction(callName, fieldType, udafMap.get(callName));
}
// rebuild parameters
List<Integer> newArgList = Lists.newArrayList(aggCall.getArgList());
if (udafMap != null && udafMap.containsKey(callName)) {
newArgList = truncArgList(newArgList, udafMap.get(callName));
}
if (func.needRewriteField()) {
RelDataTypeField field = getInput().getRowType().getField(func.getRewriteFieldName(), true, false);
if (newArgList.isEmpty()) {
newArgList.add(field.getIndex());
} else {
// TODO: only the first column got overwritten
newArgList.set(0, field.getIndex());
}
}
// rebuild aggregate call
AggregateCall newAggCall = new AggregateCall(newAgg, false, newArgList, fieldType, callName); 進而在Calcite運作時進行再次聚合并得到最終的結果(例如從多個Segment擷取的值需進一步聚合),而該操作實際是通過反射調用了各量度類型中所指定的AggrFunction類的相應方法,例如BitmapMeasureType在COUNT_DISTINCT場景下的AggrFunction類是BitmapDistinctCountAggFunc,其代碼如下所示:
public class BitmapDistinctCountAggFunc {
public static BitmapAggregator init() {
return new BitmapAggregator();
}
public static BitmapAggregator add(BitmapAggregator agg, Object value) {
agg.aggregate((BitmapCounter) value);
return agg;
}
public static BitmapAggregator merge(BitmapAggregator agg, Object value) {
BitmapAggregator agg2 = (BitmapAggregator) value;
if (agg2.getState() == null) {
return agg;
}
return add(agg, agg2.getState());
}
public static long result(BitmapAggregator agg) {
BitmapCounter finalState = agg.getState();
return finalState == null ? 0 : finalState.getCount();
}
} 實際也是調用了BitmapAggregator的相關方法。
結語
本文主要介紹了基數統計的相關知識以及Kylin如何支援基數統計。Kylin同時支援精确統計和近似統計,可以針對實際應用場景,權衡查詢性能、存儲空間和計算精度,選擇合适的方式。
參考文獻
- 《Apache Kylin權威指南(第2版)》;
- 《大資料去重算法分析及其在Kylin中的應用》。