平台需要具備的功能
1.基礎的軟體項⽬目代碼品質量檢測,類似sonarqube/xlint的較為全⾯面的代碼品質量檢測服務;
2.基于抽象文法樹的代碼分析服務,通過基于抽象文法樹的代碼分析⽅方法,能夠提供⽐比傳統根據送出數或者代碼⾏行行數更更科學有效的度量量軟體開發⼈人員⼯工作量量的⽅方法;
3.代碼價值貢獻度量量。通過圖算法和⾃自然語⾔言處理理/機器器學習等技術,我們能從結構化和非結構化(⽬目前在設計階段)兩⽅⾯度量量開發⼈人員代碼送出産⽣生的(軟體意義上的)價值;
4.基于深度學習的履歷解析服務。通過深度學習,更更快更更準确的提供職位和履歷比對。
5.在上述服務的基礎上建構⼈人才技能能⼒力力名額體系,建構⼈人才畫像,從⽽而能夠更更精準有效地為企業提供⼈人才的挖掘/比對等服務。
平台服務架構
平台架構具有⾼高度可擴充性,服務間普遍通過異步消息通信,指令服務接收代碼分析請求,轉化為指令消息下發消息隊列列,各分析服務收到指令消息執⾏行行各種分析任務,然後将分析資料⼊入庫。在基礎分析資料和次元模型的基礎上,提供了了多種形式的查詢視圖。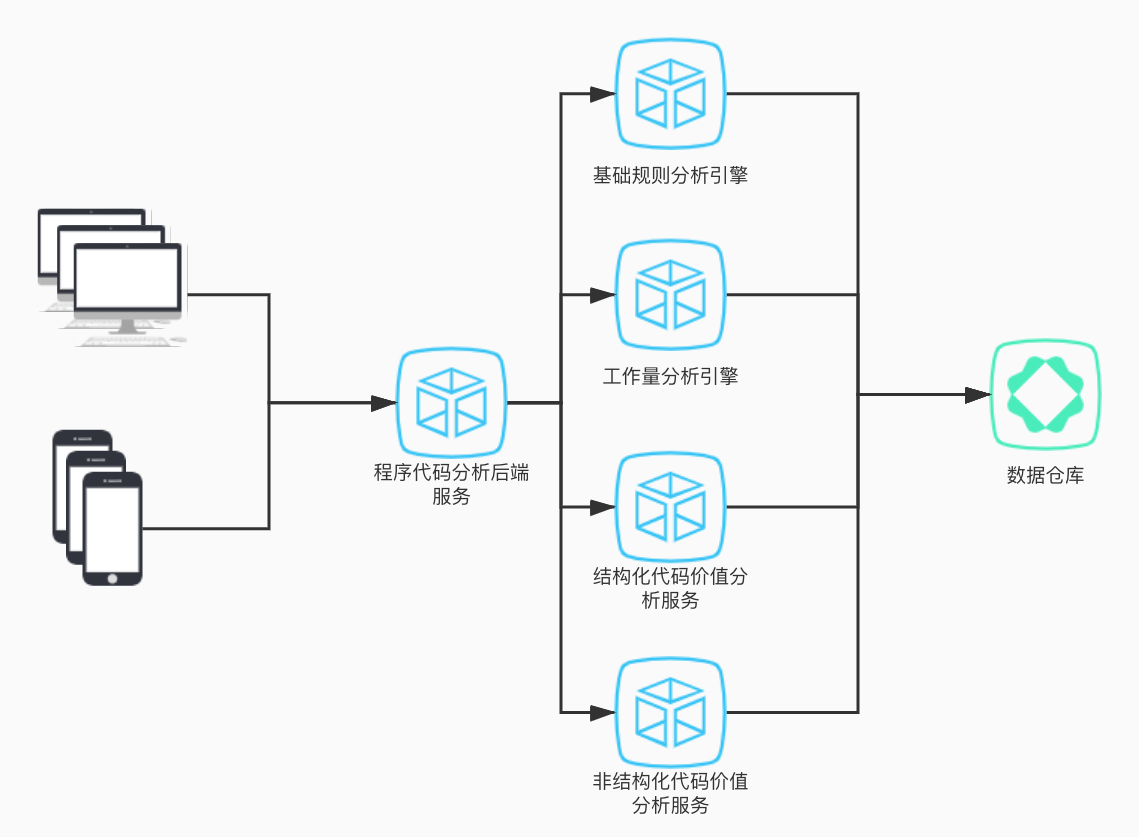 基于抽象文法樹的代碼分析
⽬前⼯業界有多種分析⽅法可以作為⼯作量度量的基礎⽅法:
1.基于⾏⽂本的差異分析
2.基于送出數的分析
3.基于文法元素token的分析
4.基于抽象文法樹的分析
基于⾏⽂本和送出數的分析相對簡單,能⽐較粗粒度地度量開發⼯作量,⼤部分版本控制軟體預設的diff⼯具都是采⽤的基于⾏⽂本的差異分析⽅法。
代碼分析服務采⽤的是基于抽象文法樹的分析⽅法,該⽅法能追蹤軟體不同層次上(全局、類
型、函數、變量)的演化,⽐⾏⽂本分析能提供更多更精确的資訊。
基于抽象文法樹(ast)的分析,通過将不同語⾔的抽象文法樹映射到⼀個抽象的樹結構模型來屏蔽不
同程式設計語⾔的ast的差異,在樹模型基礎上通過多種樹比對算法和結構化資訊差異分析算法,對⽐得到不同送出(或代碼⽂件)之間文法元素的差異,能進⽽計算得到⼯作量的相對精确量化值。該服務通過挖掘軟體代碼庫中代碼資訊來提供更豐富更準确的軟體演化資訊,以及開發⼈員在軟體⽣命周期中開發⼯作量的跟蹤度量。

樹模型結構
ITree: type(節點類型,如:IfStmt;ForStmt), label(根據類型存放對應值), children(⼦節點集合),
parent(⽗節點)
樹的編輯操作
前後兩次送出源代碼的變化會導緻⽣成的樹結構變化,對應為樹結構A轉化為B的⼀系列編輯操作,這樣
源代碼的變化檢測就轉換為了樹編輯距離問題。對樹的編輯操作有增加/删除/替換/移動(即增加和删除
的組合),兩個版本的⽐較即為從A版本的ast轉化為B版本的ast的編輯操作清單(編輯腳本)。
樹比對算法
找到樹A到樹B之間的⼀個合适的比對
比對算法的輸出為兩棵樹中最合适的節點對比對集合(Iterable[Pair[ITree, ITree]])。服務包含了多種比對
算法,如最⻓公共⼦序列比對,樹編輯距離比對等。
尋找産⽣最⼩确認編輯腳本的合适比對集算法需要滿⾜以下兩個比對标準:
x,y均為葉⼦節點:
matchLeafNode(x, y) = if (l(x) == l(y) && sim(v(x), v(y)) >= f) true else
false
其中sim(v(x), v(y)) 為x,y兩節點的值相似度,f為字元串相似度門檻值
x,y均為⾮葉⼦節點:
matchInternalNode(x, y) = if (l(x) == l(y) && common(x, y) /
max(leafNodesCount(x), leafNodesCount(y)) >= t) true else false
内部節點,使⽤計算⼦樹中公共葉⼦節點的⽅式度量節點相似度, t為内部節點相似度門檻值 根據計算出的比對,找到最⼩的将樹A轉化為樹B的确認編輯腳本(Chawathe) 編輯操作的計算算法⼤緻為:
1.根據比對算法得到的mapping清單⽣成從樹A到樹B的比對清單Map1和從樹B到樹A的比對清單
Map2;
2.⼴度優先周遊樹B,對于樹B中每個節點x和其⽗節點y,從Map2中尋找x和y在樹A中最佳比對的節
點,如果存在,分别⽤w和z表示;
3.如果x的比對節點不存在,則x為新增節點,建立⼀個Insert操作;
4.如果w節點存在,但值不等于x節點的值,則建立⼀個Update操作;
5.如果w節點的⽗節點為v,v和y節點對在mapping清單中不存在,則可以判斷x的⽗節點發⽣了變
化,建立⼀個Move操作
6.對樹A進⾏後續周遊,通過Map1,如果節點在樹B中找不到比對節點,則建立Delete操作。
差異分類
将變更類型做出分類:
1.類級别修改(增删改類以及繼承關系的更改等)
2.⽅法函數級别修改(增删改⽅法以及⽅法簽名的更改等)
3.單條順序語句修改(增删改語句)
4.條件和循環語句修改(條件表達式變更,增删else語句塊等)
5.語句塊結構修改(語句順序變更等)
6.注釋語句修改(注釋語句塊增删改)
7.可⻅性修改(可⻅性增強或降低)
對應⼯作量名額的計算來說,不同分類會對應不同的計算權重。
⼯作量計算
在差異分類的基礎上,不同類型變更權重求和得到⼯作量名額。
代碼價值貢獻度量
結構化代碼價值分析服務
采⽤PageRank的變種算法結構化分析軟體靜态調⽤圖,計算函數/⽅法的重要性排名,得到結構化的代
碼價值貢獻名額
PageRank算法是google早期評價⽹⻚重要性的算法,其核⼼思想為:1.如果⼀個⽹⻚被很多其他⽹⻚連結到,說明這個⽹⻚⽐較重要,rank值會相對較⾼;2.如果⼀個rank值很⾼的⽹⻚連結到⼀個其他的⽹⻚,那麼被連結到的⽹⻚的rank值會相應地是以⽽提⾼。
這種思想可以遷移到軟體調⽤關系的分析上,從⽽得到在⼀個軟體項⽬中,哪些函數或子產品處于相對重要的位置,相應的開發⼈員價值貢獻也會有⼀個⾼的權重。
我們在上⾯基于抽象文法樹的代碼分析建構的樹模型基礎上,通過對文法元素的識别,周遊得到函數⽅法的靜态調⽤關系。相對于運⾏時得到的動态調⽤關系圖,從代碼分析得到的靜态調⽤關系圖會缺少資訊,但是結合繼承/接⼝實作等關系的分析⽣成的靜态調⽤圖還是有相當的可⽤性。
履歷解析服務
雲沃客平台為企業提供了招聘獵聘服務,同時有⼤量⼈才在平台上求職。履歷解析服務嘗試⽤機器學習/深度學習的技術,更精準快速地從⾮結構化⽂本中提取結構化的⼈才資料,為後⾯的分析查詢檢索服務提供基礎資料。傳統的履歷解析,需要依賴⼤量的段落關鍵詞,設計規則來對不同子產品進⾏劃分。如履歷某⼀⾏出現了教育經曆/學習經曆, 則說明下⾯的内容屬于教育子產品。如出現了⼯作經曆/實習經曆則說明下⾯内容屬于⼯作經曆子產品。如果該履歷沒有使⽤子產品關鍵詞,或者使⽤的詞庫沒有子產品關鍵詞,則整個段落就都漏掉了。
如果對于某⼀⾏,上⽂是該⼈的基本資訊,⽽下⾯連續出現了多⾏都是學校的資訊,則知道這⾥是基本資訊和教育經曆的劃分點了,平台履歷解析服務通過雙向⻓短記憶神經⽹絡(BiLSTM)模型,解析時同時考慮正序和逆序,引⼊上下⽂的序列資訊,可以更精确地劃分子產品資訊。
分詞
中⽂⽂本分析需要做分詞處理,⼀種是傳統的基于詞表的規則分詞(如jieba等庫);還有就是統計分詞,需要⽤到機器學習或深度學習技術。⽬前常⽤的深度學習模型是BiLSTM。基于LSTM模型最⼤的優
勢是能處理較⻓的順序依賴性,例如 在履歷頭部出現了姓名,在履歷中段出現了另外⼀個類似姓名的公司名,就能判斷這個是别的實體。
詞向量
詞向量是詞語的數字形式表示,相近意思的詞語會有相似的詞向量。在履歷分析的場景⾥⾯,詞向量可以幫助識别訓練資料集中沒有的的公司,職位,技能等資訊,以及作為序列标注當成BiLSTM的輸⼊層。
![【趨高機器視覺】機器視覺技術原了解析及解決方案[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)