Hive是大資料領域常用的元件之一,主要是大資料離線數倉的運算,關于Hive的性能調優在日常工作和面試中是經常涉及的一個點,是以掌握一些Hive調優是必不可少的技能。影響Hive效率的主要有資料傾斜、資料備援、job的IO以及不同底層引擎配置情況和Hive本身參數和HiveSQL的執行等因素。本文主要是從監控運維的角度對Hive進行整體性能把控,通過對hive中繼資料監控,提前發現Hive表的不合理處及可優化點,将被動運維轉化為主動運維。
1 Hive中繼資料簡介
Hive中繼資料一般會存儲在關系資料庫中,mysql是最常見的選擇,這裡介紹的就是Hive中繼資料就是存儲在myslq中的,本次會介紹幾張主要的中繼資料表,DBS、TBLS、SDS、PARTITIONS
1.1 Hive資料庫相關的中繼資料表(DBS)
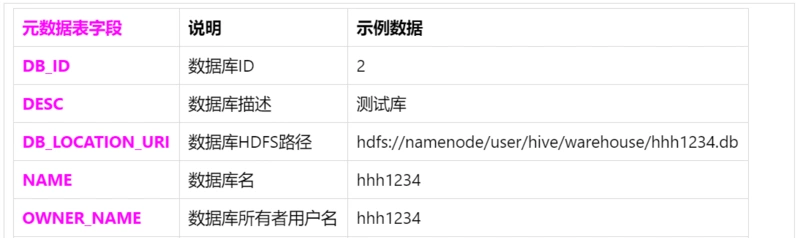
1.2 Hive表和視圖相關的中繼資料表(TBLS)

1.3 Hive檔案存儲資訊相關的中繼資料表(SDS)
1.4 Hive資料庫相關的中繼資料表(PARTITIONS)
2 收集Hive中繼資料
在使用Hive中繼資料做監控時要確定相應表或者分區的中繼資料資訊已經被收集。收集中繼資料的方式如下
2.1 收集表的中繼資料
analyze table 表名 compute statistic;
2.2 收集表的字段的中繼資料
analyze table 表名 compute statistic for columns;
2.3 收集所有分區的中繼資料
analyze table 表名 partition(分區列) compute statistic;
2.4 指定特定分區進行收集中繼資料
analyze table 表名 partition(分區列=分區值) compute statistic;
2.5 收集所有分區的列的中繼資料
analyze table 表名 partition(分區列) compute statistic for columns;
3 Hive中繼資料監控案例
3.1監控普通表存儲的檔案的平均大小
對于大的檔案塊可能導緻資料在讀取時産生資料傾斜,影響叢集任務的運作效率。下面sql是對于大于兩倍HDFS檔案塊大小的表:
-- 整體邏輯:通過DBS找到對應庫下面的表TBLS,再通過TBLS找到每個表對應的表屬性,取得totalSize和numFiles兩個屬性,前者表示檔案大小,後者表示檔案數量
**SELECT**
TBL_NAME,round(avgfilesize,1) **as** 'fileSize(Mb)'
**FROM** (
**SELECT**
tp.totalSize/(1024*1024)/numFiles avgfilesize,TBL_NAME
**FROM** metastore.dbs d
**INNER** **join** metastore.tbls t **on** d.DB_ID = t.DB_ID
**left** **join** (
**SELECT** TBL_ID,
**MAX**(**case** PARAM_KEY **when** 'numFiles' **then** PARAM_VALUE **ELSE** 0 **END**) numFiles,
**MAX**(**case** PARAM_KEY **when** 'totalSize' **then** PARAM_VALUE **ELSE** 0 **END** ) totalSize
**from** metastore.table_params
**GROUP** **by** TBL_ID
) tp **on** t.TBL_ID = tp.TBL_ID
**where** d.NAME = '要監控的庫'
**and** tp.numFiles **is** **not** **NULL**
**and** tp.numFiles > 0
) a **where** avgfilesize > hdfs的檔案塊大小*2
**ORDER** **BY** avgfilesize **desc**;
3.2監控分區存儲的檔案平均大小,大于兩倍HDFS檔案塊大小的分區,
-- 整體邏輯:先用DBS關聯TBLS表,TBLS表關聯PARTITIONS表PARTITION表關聯PARTITION_PARAMS
**SELECT**
TBL_NAME,part_name,round(avgfilesize,1) **as** 'fileSize(Mb)'
**FROM** (
**SELECT**
pp.totalSize/(1024*1024)/numFiles avgfilesize,TBL_NAME,part.PART_NAME
**FROM** metastore.dbs d
**INNER** **join** metastore.TBLS t **on** d.DB_ID = t.DB_ID
**INNER** **join** metastore.PARTITIONS part **on** t.TBL_ID = part.TBL_ID
**left** **join** (
**SELECT** PART_ID,
-- 每個表存儲的檔案個數
**MAX**(**case** PARAM_KEY **when** 'numFiles' **then** PARAM_VALUE **ELSE** 0 **END**) numFiles,
-- 檔案存儲的大小
**MAX**(**case** PARAM_KEY **when** 'totalSize' **then** PARAM_VALUE **ELSE** 0 **END** ) totalSize
**from** metastore.PARTITION_PARAMS
**GROUP** **by** PART_ID
) pp **on** part.PART_ID = pp.PART_ID
**where** d.NAME = '要監控的庫'
**and** pp.numFiles **is** **not** **NULL**
**and** pp.numFiles > 0
) a **where** avgfilesize >hdfs的檔案塊大小*2
**ORDER** **BY** avgfilesize **desc**;
3.3監控大表不分區的表
對于大資料量的表,如果不進行分區,意味着程式在讀取相同的資料時需要周遊更多的檔案塊,性能會下降很多。
**select** t.TBL_NAME ,round(totalSize/1024/1024,1) **as** 'fileSize(Mb)'
**FROM** metastore.DBS d
**inner** **join** metastore.TBLS t **on** d.`DB_ID` = t.`DB_ID`
**inner** **join** (
**select** `TBL_ID`,**max**(**case** `PARAM_KEY` **when** 'totalSize' **then** `PARAM_VALUE` **else** 0 **end**) totalSize
**from** `TABLE_PARAMS`
**group** **by** `TBL_ID`
) tp **on** t.`TBL_ID` = tp.`TBL_ID`
**left** **join**
(
**select** **distinct** `TBL_ID` **from** metastore.PARTITIONS p
) part **on** t.`TBL_ID` = part.`TBL_ID`
**where** d.`NAME` = '要監控的庫'
**and** part.`TBL_ID` **is** **null**
**and** totalSize/1024/1024/1024 > 30
**ORDER** **BY** totalSize/1024 **desc**;
3.4監控表分區的數量
了解表的分區數量,在做全表join時如果一個表數量不大,分區很多,可以考慮分區合并等優化手段
**SELECT**
t.TBL_NAME '表名',d.`NAME` '庫名', **COUNT**(part.PART_NAME) '分區數'
**FROM**
DBS d
**INNER** **JOIN** TBLS t **on** d.DB_ID = t.DB_ID
**INNER** **join** `PARTITIONS` part **on** part.TBL_ID = t.TBL_ID
**WHERE** d.`NAME` = '要監控的庫'
**GROUP** **by** t.TBL_NAME,d.`NAME`
**ORDER** **BY** **COUNT**(part.PART_NAME) **desc**;
結語:
Hive中繼資料的監控主要目的就是對Hive中表情況的整體把控,這裡主要介紹了大資料塊、不分區表、表分區這幾個名額的監控,當然還有很多,比如hive的小檔案、表的資料存儲格式等等,對這些資訊的長期監控,最好可以和grafana這些結合展示,這對整個數倉的穩定運作至關重要。後面我們還會出Hive SQL調優相關的文章,敬請期待。