什麼是索引?
在mysql中,索引就是幫助mysql快速找到某條資料的一種資料結構,它是排好序的,獨立于mysql表資料之外的。
索引資料結構分為哪幾種
二叉樹、紅黑樹、Hash表、B樹。
在這裡我們主要介紹hash表和B樹
Hash表
什麼是hash?
hash是一種散列函數,通過将輸入值映射為一個數值,如: hash(100) = 1,不同的hash算法,hash之後的值有可能是不同的。
Hash表是以資料映射形式存在于mysql中的,那麼hash表是如何産生的呢?
當添加一條資料到表中的時候,首先會對主鍵進行hash,然後将這條資料存在的位址和hash值建立一個映射關系,當我們根據主鍵查找這條資料的時候,隻需要将主鍵進行hash,得到hash值,最後根據hash值就可以直接定位到這條資料。是以hash算法隻需要進行一次磁盤IO,查詢速度是非常快的。
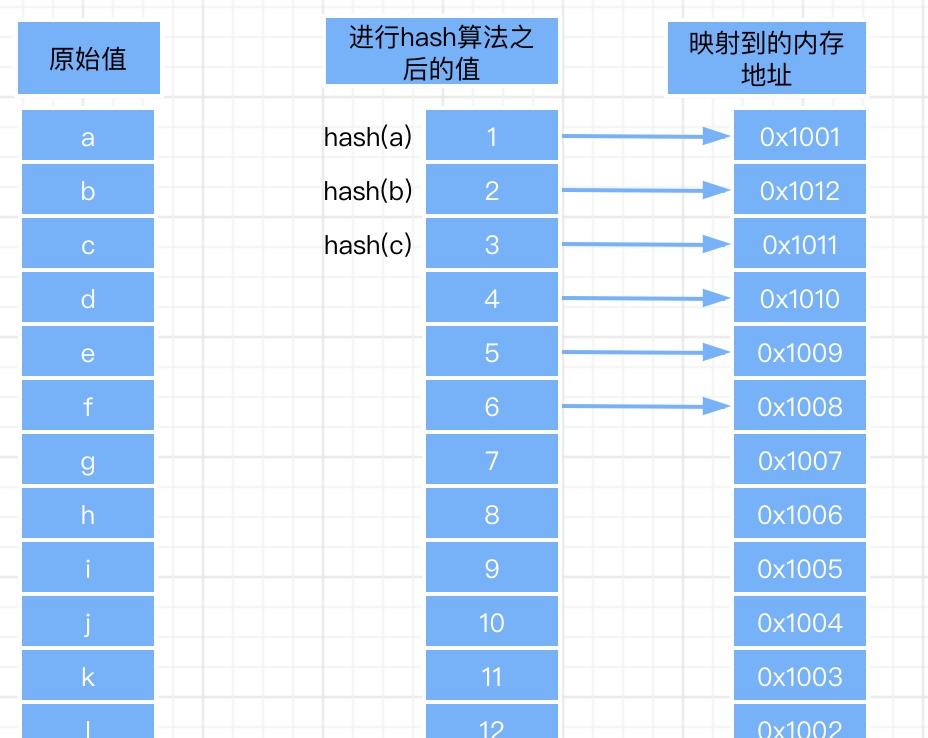
在這裡插入圖檔描述
BTree
B樹又稱為多叉樹,它在二叉樹的基礎之上,劃分出來多個叉,我們看下它的資料結構圖示。

我們從圖中可以看出B樹具有這幾種特性:
1.節點從左到右遞增排序
2.每個資料節點後面都會緊跟着一個指針,該指針是指向下一級的記憶體位址。下一級指的是位于目前指針左右兩邊數值中間的資料記錄所存在記憶體中的位址。
3.葉子節點 的指針為空
4.所有索引元素是不重複的。
5.每個索引節點都存着目前指向的記錄資料(或記憶體位址)
B+Tree
B+樹其實是B樹的一個變種,它在B樹的基礎之上做了一些改善,将索引節點所關聯的資料記錄全部移到葉子節點上了,目的是為了可以存儲更多的索引節點,但是卻增加了索引節點的備援,因為葉子節點包含了所有的索引節點。
從圖中可以看出,B+樹具有以下幾個特性:
1.葉子節點包含所有的索引節點
2.非葉子節點不存儲資料記錄
3.葉子節點之間使用指針連接配接,提高區間通路的便利
4.指針所指向的索引節點的最左邊都是大于等于指針所在深度左邊的值
mysql的b+ tree優化了什麼?
我們看下mysql中的B+樹長什麼樣子的
1.增加了一個雙向的指針
2.首尾節點也通過指針進行關聯起來
主要目的是為了更加友好的支援索引内部的範圍查找。如果不加雙向連結清單指針,我們每次查找的時候,都要回到根節點查找,增加了磁盤IO,增加查詢時間。
如何計算 B+ tree最大支援資料量
在mysql中,可以使用
SHOW GLOBAL STATUS LIKE 'Innodb_page_size%'
指令查找到mysql對索引節點頁面大小的設定,這個參數的大小決定了我們一次性能夠從磁盤盤中load出多少索引數量。
在5.7版本中Innodb_page_size 預設設定為16384,也就是16k。
我們現在計算下myssql中,如果存儲引擎為innodb的話,大概能支撐多少量級的資料?
我們按照高度為3的樹進行計算:
1.按照每個bigint資料類型的字段存儲,每個非葉子索引節點最多需要8B
2.再加上每個索引節點後面連接配接的指針,指針在innodb中設定的大小為6B
3.兩者加起來總共14B,是以一級節點總共能存儲 16kB/14B = 1170個索引節點
4.二級節點都是從一級節點劃分出來,也就是一級節點中的每個節點又能劃分出1170個,是以二級節點和一級節點總共能存儲11701170 = 1368900個 索引節點。
5.三級節點也就是葉子節點,葉子節點存儲的是主鍵值+記錄資料,記錄資料最多為1K,這個時候主鍵值8B可以忽略不計了,是以每個葉子節點最多能存儲16k/1k = 16條記錄。
6.是以Innodb引擎結構的表中最多能支撐11701170*16 = 21902400 條資料,大概21億,如果大于這個值,基本上都需要進行分庫分表了,mysql建議B+樹的深度最好小于3.
``
hash算法很快,為什麼mysql 很少使用hash索引?
在上面說過,hash算法,在查找資料的時候隻用進行一次磁盤IO,查詢速度非常快,但是為什麼mysql不推薦使用呢?主要有以下幾個原因
1.hash沖突(占比小,因為mysql的hash算法品質比較高,造成hash沖突的機率比較低)
2.無法進行範圍查詢(因為hash表裡面存放的是hash值,不是資料本身,是以無法進行資料的比較,如果你确定你的表中隻會用到精準查找的話,則可以使用hash結構的索引)
B tree與B+ tree差別?
1.增加了雙向連結清單,便于範圍查找.
2.隻有葉子節點才存儲資料記錄,意味着可以存儲更多的索引節點.
聚集(聚簇)索引與非聚集(聚簇)索引的差別?
聚集(聚簇)索引:索引檔案與資料檔案是合并在一起存放的
非聚集(聚簇)索引:索引檔案與資料檔案是獨立存放的
innodb存儲引擎實作(主鍵和輔助鍵)
主鍵索引:
在innodb中預設使用B+ tree結構類型,存儲的是聚集索引,葉子結點的data區域存儲的是目前主鍵關聯的整條記錄
輔助鍵:
輔助鍵的data區域存儲的是主鍵值,也就是說如果使用輔助鍵索引查詢,最後還得通過主鍵值查找對應的記錄。
myisam存儲引擎的索引,不管主鍵還是輔建索引,data區域儲存的都是所關聯資料的記憶體位址,因為myisam是非聚集索引,索引檔案和資料檔案是分開存儲的。
為什麼Innodb表必須有主鍵?并且推薦使用整型 并且 自增主鍵?
1.為什麼Innodb表必須有主鍵?
在innodb存儲引擎表中,mysql會給主鍵添加聚集索引,如果沒有主鍵,mysql則會選舉表中設定了唯一索引的字段設定為主鍵,建立主鍵索引;
如果表中沒有字段設定為唯一索引,則mysql會生成一個row_id,作為主鍵,建立主鍵索引。
2.為什麼mysql推薦使用整形作為主鍵字段類型?
在組建B樹的時候,mysql會按照從小到大的順序進行組建,如果是整形數字的話,mysql則可以直接進行比較,如果是其它類型的話,mysql還得需要将值轉換為ascill碼,進行比較,會增加建立索引和查詢的時間。
3.為什麼要求是自增類型?
這是由mysql限制條件決定的:
1.mysql設定innodb的一次性讀取到記憶體中的頁大小設定為16384B,也就是每個節點最大為16k,
2.btree按照順序從左往右排列;
假如現在主鍵不是自增的,這時候如果加入了一個新的值11,那麼通過比較之後,11是需要存儲在10和12之間的:
1.如果這個時候該節點已經為16k了,再加入一個資料的話,會超過mysql設定的限制,就會出現分裂,拆分成兩個節點,這個操作同樣會增加索引建立的時間。
2.如果按照字段設定為自增的,則不會插入比目前序号小的資料,隻需要在右邊繼續擴充就行,不會出現節點分裂的情況。
為什麼非主鍵索引結構葉子節點存儲的是主鍵值 (一緻性和存儲空間)
1.如果存儲的是具體的資料的話,會造成資料不一緻的問題,因為主鍵索引和輔助索引會同時維護資料記錄,如果有一方維護失敗則會出現不一緻性的問題
2.都存儲具體資料的話,會造成存儲空間的浪費,如果隻存儲主鍵記錄的話,可以存儲更多的索引記錄,但是需要二次根據主鍵查找具體資料,以時間換空間
聯合索引的底層存儲結構
❝
微信搜一搜【樂哉開講】關注帥氣的我,回複【幹貨】,将會有大量面試資料和架構師必看書籍等你挑選,包括java基礎、java并發、微服務、中間件等更多資料等你來取哦。