愛生活,愛編碼,本文已收錄 架構技術專欄 關注這個喜歡分享的地方。
開源項目:
- 分布式監控(Gitee GVP最有價值開源項目 ): https://gitee.com/sanjiankethree/cubic
- 攝像頭視訊流采集: https://gitee.com/sanjiankethree/cubic-video
- Github 文章收錄: https://github.com/qianglu1989/technology
零、開局
前兩天我搞了兩個每日一個知識點,對多線程并發的部分知識做了下概括性的總結。但通過小夥伴的回報是,那玩意寫的比較抽象,看的雲裡霧裡暈暈乎乎的。
是以又針對多線程底層這一塊再重新做下系統性的講解。
有興趣的朋友可以先看下前兩節,可以說是個籠統的概念版。
好了,回歸正題。
在多線程并發的世界裡synchronized、volatile、JMM是我們繞不過去的技術坎,而重排序、可見性、記憶體屏障又有時候搞得你一臉懵逼。有道是知其然知其是以然,了解了底層的原理性問題,不論是日常寫BUG還是面試都是必備神器了。
先看幾個問題點:
1、處理器與記憶體之間是怎麼互動的?
2、什麼是緩存一緻性協定?
3、高速緩存内的消息是怎麼更新變化的?
4、記憶體屏障又和他們有什麼關系?
如果上面的問題你都能倒背如流,那就去看看電影放松下吧!
一、高速緩存
目前的處理器的處理能力要遠遠的勝于主記憶體(DRAM)通路的效率,往往主記憶體執行一次讀寫操作所需的時間足夠處理器執行上百次指令。是以為了填補處理器與主記憶體之間的差距,設計者們在主記憶體和處理器直接引入了高速緩存(Cache)。如圖:
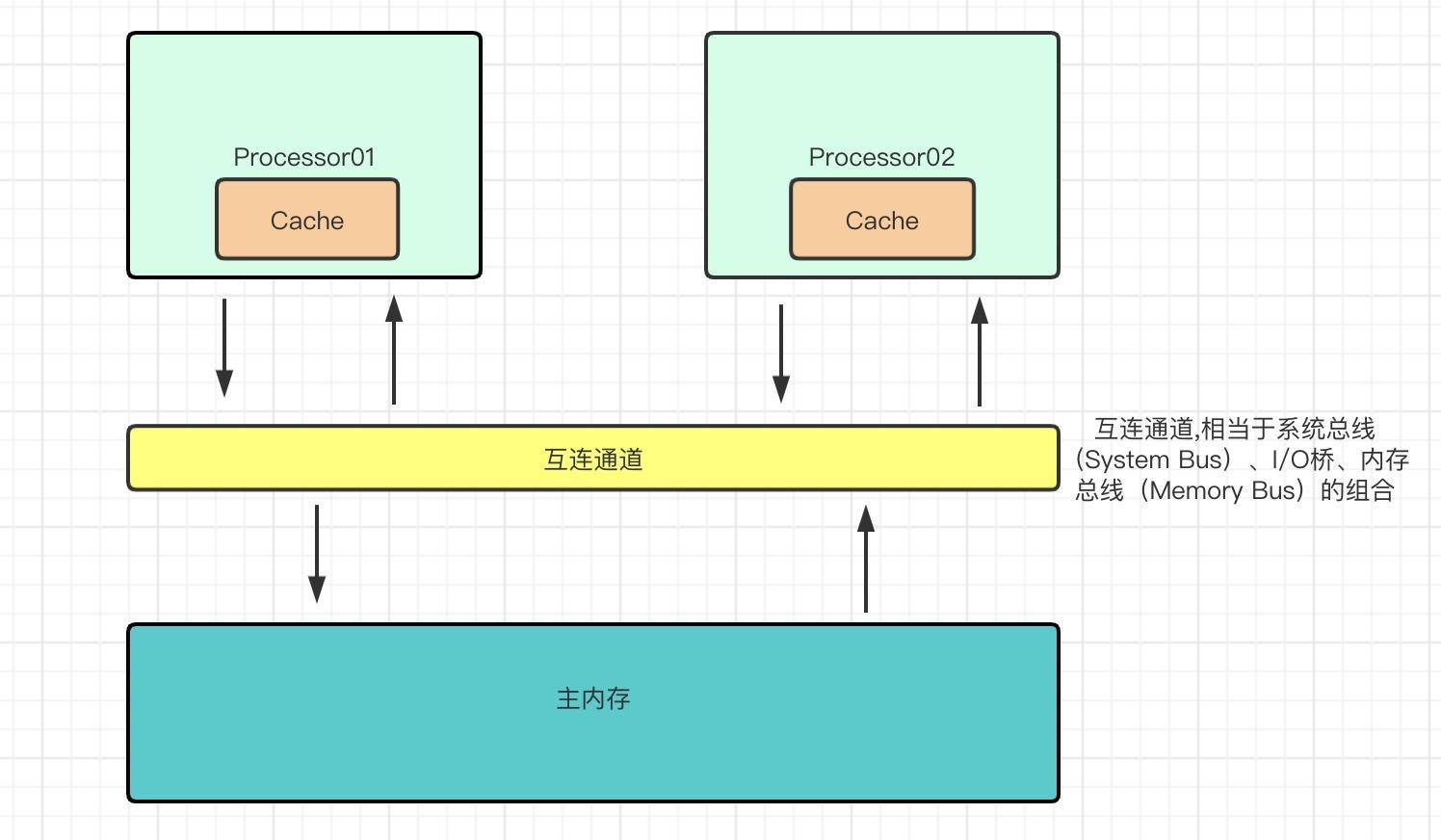
其實在現代處理器中,會有多級高速緩存。一般我們會成為一級緩存(L1 Cache)、二級緩存(L2 Cache)、三級緩存(L3 Cache)等,其中一級緩存一般會被內建在CPU核心中。如圖:

内部結構
高速緩存存在于每個處理器内,處理器在執行讀、寫操作的時候并不需要直接與記憶體互動,而是通過高速緩存進行。
高速緩存内其實就是為應用程式通路的變量儲存了一個資料副本。高速緩存相當于一個容量極小的散清單(Hash Table),其鍵是一個記憶體位址,值是記憶體資料的副本或是我們準備寫入的資料。從其内部來看,其實相當于一個拉鍊散清單,也就是包含了很多桶,每個桶上又可以包含很多緩存條目(想想HashMap),如圖:
緩存條目
在每個緩存條目中,其實又包含了Tag、Data Block、Flag三個部分,咱們來個小圖:
- Data Block : 也就是我們常常叨叨的緩存行(Cache Line),她其實是高速緩存與主記憶體間進行資料互動的最小單元,裡面存儲着我們需要的變量資料。
- Tag : 包含了緩存行中資料記憶體位址的資訊(其實是記憶體位址的高位部分的比特)
- Flag : 辨別了目前緩存行的狀态(MESI咯)
那麼,我們的處理器又是怎麼尋找到我們需要的變量呢?
不多說,上圖:
其實,在處理器執行記憶體通路變量的操作時,會對記憶體位址進行解碼的(由高速緩存控制器執行)。而解碼後就會得到tag、index 、offset三部分資料。
index : 我們知道高速緩存内的結構是一個拉鍊散清單,是以index就是為了幫我們來定位到底是哪個緩存條目的。
tag : 很明顯和我們緩存條目中的Tag 一樣,是以tag 相當于緩存條目的編号。主要用于,在同一個桶下的拉鍊中來尋找我們的目标。
offset : 我們要知道一個前提,就是一個緩存條目中的緩存行是可以存儲很多變量的,是以offset的作用是用來确定一個變量在緩存行中的起始位置。
是以,在如果在高速緩存内能找到緩存條目并且定位到了響應得緩存行,而此時緩存條目的Flag辨別為有效狀态,這時候也就是我們所說的緩存命中(Cache Hit),否則就是緩存未命中(Cache Miss)。
緩存未命有包括讀未命中(Read Miss)和寫未命中(Write Miss)兩種,對應着對記憶體的讀寫操作。
而在讀未命中(Read Miss) 産生時,處理器所需要的資料會從主記憶體加載并被存入高速緩存對應的緩存行中,此過程會導緻處理器停頓(Stall)而不能執行其他指令。
二、緩存一緻性協定
在多線程進行共享變量通路時,因為各個線程執行的處理器上的高速緩存中都會儲存一份變量的副本資料,這樣就會有一個問題,那當一個副本更新後怎麼保證其它處理器能馬上的擷取到最新的資料。這其實就是緩存一緻性的問題,其本質也就是怎麼防止資料的髒讀。
為了解決這個問題,處理器間出現了一種通信機制,也就是緩存一緻性協定(Cache Coherence Protocol)。
MESI是什麼
緩存一緻性協定有很多種,MESI(Modified-Exclusive-Shared-Invalid)協定其實是目前使用很廣泛的緩存一緻性協定,x86處理器所使用的緩存一緻性協定就是基于MESI的。
我們可以把MESI對記憶體資料通路了解成我們常用的讀寫鎖,它可以使對同一記憶體位址的讀操作是并發的,而寫操作是獨占的。是以在任何時刻寫操作隻能有一個處理器執行。而在MESI中,一個處理器要向記憶體寫資料時必須持有該資料的所有權。
MESI将緩存條目的狀态分為了Modified、Exclusive、Shared、Invalid四種,并在此基礎上定義了一組消息用于處理器的讀、寫記憶體操作。如圖:
MESI的四種狀态
是以MESI其實就是使用四種狀态來辨別了緩存條目目前的狀态,來保證了高速緩存内資料一緻性的問題。那我們來仔細的看下四種狀态
Modified :
表示高速緩存中相應的緩存行内的資料已經被更新了。由于MESI協定中任意時刻隻能有一個處理器對同一記憶體位址對應的資料進行更新,也就是說再多個處理器的高速緩存中相同Tag值得緩存條目隻能有一個處于Modified狀态。處于此狀态的緩存條目中緩存行内的資料與主記憶體包含的資料不一緻。
Exclusive:
表示高速緩存相應的緩存行内的資料副本與主記憶體中的資料一樣。并且,該緩存行以獨占的方式保留了相應主記憶體位址的資料副本,此時其他處理上高速緩存目前都不保留該資料的有效副本。
Shared:
表示目前高速緩存相應緩存行包含相應主記憶體位址對應的資料副本,且與主記憶體中的資料是一緻的。如果緩存條目狀态是Shared的,那麼其他處理器上如果也存在相同Tag的緩存條目,那這些緩存條目狀态肯定也是Shared。
Invalid:
表示該緩存行中不包含任何主記憶體中的有效資料副本,這個狀态也是緩存條目的初始狀态。
MESI處理機制
前面說了那麼多,都是MESI的基礎理論,那麼,MESI協定到底是怎麼來協調處理器進行記憶體的讀寫呢?
其實,想協調處理必然需要先和各個處理器進行通信。是以MESI協定定義了一組消息機制用于協調各個處理器的讀寫操作。
我們可以參考HTTP協定來進行了解,可以将MESI協定中的消息分為請求和響應兩類。處理器在進行主記憶體讀寫的時候會往總線(Bus)中發請求消息,同時每個處理器還會嗅探(Snoop)總線中由其他處理器發出的請求消息并在一定條件下往總線中回複響應得響應消息。
針對于消息的類型,有如下幾種:
- Read : 請求消息,用于通知其他處理器、主記憶體,目前處理器準備讀取某個資料。該消息内包含待讀取資料的主記憶體位址。
- Read Response: 響應消息,該消息内包含了被請求讀取的資料。該消息可能是主記憶體傳回的,也可能是其他高速緩存嗅探到Read 消息傳回的。
- Invalidate: 請求消息,通知其他處理器删除指定記憶體位址的資料副本。其實就是告訴他們你這個緩存條目内的資料無效了,删除隻是邏輯上的,其實就是更新下緩存條目的Flag.
- Invalidate Acknowledge: 響應消息,接收到Invalidate消息的處理器必須回複此消息,表示已經删除了其高速緩存内對應的資料副本。
- Read Invalidate: 請求消息,此消息為Read 和 Invalidate消息組成的複合消息,作用主要是用于通知其他處理器目前處理器準備更新一個資料了,并請求其他處理器删除其高速緩存内對應的資料副本。接收到該消息的處理器必須回複Read Response 和 Invalidate Acknowledge消息。
- Writeback: 請求消息,消息包含了需要寫入主記憶體的資料和其對應的記憶體位址。
了解完了基礎的消息類型,那麼我們就來看看MESI協定是如何協助處理器實作記憶體讀寫的,看圖說話:
舉例:假如記憶體位址0xxx上的變量s 是CPU1 和CPU2共享的我們先來說下CPU上讀取資料s
高速緩存記憶體在有效資料時:
CPU1會根據記憶體位址0xxx在高速緩存找到對應的緩存條目,并讀取緩存條目的Tag和Flag值。如果此時緩存條目的Flag 是M、E、S三種狀态的任何一種,那麼就直接從緩存行中讀取位址0xxx對應的資料,不會向總線中發送任何消息。
高速緩存内不存在有效資料時:
1、如CPU2 高速緩存内找到的緩存條目狀态為I時,則說明此時CPU2的高速緩存中不包含資料s的有效資料副本。
2、CPU2向總線發送Read消息來讀取位址0xxx對應的資料s.
3、CPU1(或主記憶體)嗅探到Read消息,則需要回複Read Response提供相應的資料。
4、CPU2接收到Read Response消息時,會将其中攜帶的資料s存入相應的緩存行并将對應的緩存條目狀态更新為S。
從宏觀的角度看,就是上面的流程了,我們再繼續深入下,看看在緩存條目為I的時候到底是怎麼進行消息處理的
說完了讀取資料,我們就在說下CPU1是怎麼寫入一個位址為0xxx的資料s的
MESI協定解決了緩存一緻性的問題,但其中有一個問題,那就是需要在等待其他處理器全部回複後才能進行下一步操作,這種等待明顯是不能接受的,下面就繼續來看看大神們是怎麼解決處理器等待的問題的。
三、寫緩沖和無效化隊列
因為MESI自身有個問題,就是在寫記憶體操作的時候必須等待其他所有處理器将自身高速緩存内的相應資料副本都删除後,并接收到這些處理器回複的Invalidate Acknowledge/Read Response消息後才能将資料寫入高速緩存。
為了避免這種等待造成的寫操作延遲,硬體設計引入了寫緩沖器和無效化隊列。
寫緩沖器(Store Buffer)
在每個處理器内都有自己獨立的寫緩沖器,寫緩沖器内部包含很多條目(Entry),寫緩沖器比高速緩存還要小點。
那麼,在引入了寫緩沖器後,處理器在執行寫入資料的時候會做什麼處理呢?還會直接發送消息到BUS嗎?
我們來看幾個場景:
(注意x86處理器是不管相應的緩存條目是什麼狀态,都會直接将每一個寫操作結果存入寫緩沖器)
1、如果此時緩存條目狀态是E或者M:
代表此時處理器已經擷取到資料所有權,那麼就會将資料直接寫入相應的緩存行内,而不會向總線發送消息。
2、如果此時緩存條目狀态是S
- 此時處理器會将寫操作的資料存入寫緩沖器的條目中,并發送Invalidate消息。
- 如果此時相應緩存條目的狀态是I ,那就稱之為寫操作遇到了寫未命中(Write Miss),此時就會将資料先寫入寫緩沖器的條目中,然後在發送Read Invalidate來通知其他處理器我要進行資料更新了。
- 處理器的寫操作其實在将資料寫入緩沖器時就完成了,處理器并不需要等待其他處理器傳回Invalidate Acknowledge/Read Response消息
- 當處理器接收到其他處理器回複的針對于同一個緩存條目的Invalidate Acknowledge消息時,就會将寫緩沖内對應的資料寫入相應的緩存行中
通過上面的場景描述我們可以看出,寫緩沖器幫助處理器實作了異步寫資料的能力,使得處理器處理指令的能力大大提升。
無效化隊列(Invalidate Queue)
其實在處理器接到Invalidate類型的消息時,并不會删除消息中指定位址對應的資料副本(也就是說不會去馬上修改緩存條目的狀态為I),而是将消息存入無效化隊列之後就回複Invalidate Acknowledge消息了,主要原因還是為了減少處理器等待的時間。
是以不管是寫緩沖器還是無效化隊列,其實都是為了減少處理器的等待時間,采用了空間換時間的方式來實作指令的異步處理。
總之就是,寫緩沖器解決了寫資料時要等待其他處理器響應得問題,無效化隊列幫助解決了删除資料等待的問題。
但既然是異步的,那必然又會帶來新的問題 -- 記憶體重排序和可見性問題。
是以,我們繼續接着聊。
存儲轉發(Store Fowarding)
通過上面内容我們知道了有了寫緩沖器後,處理器在寫資料時直接寫入緩沖器就直接傳回了。
那麼問題就來了,當我們寫完一個資料又要馬上進行讀取可咋辦呢?話不多說,咱們還是舉個例子來說,如圖:
此時第一步處理器将變量S的更新後的資料寫入到寫緩沖器傳回,接着馬上執行了第二布進行S變量的讀取。由于此時處理器對S變量的更新結果還停留在寫緩沖器中,是以從高速緩存緩存行中讀到的資料還是變量S的舊值。
為了解決這種問題,存儲轉發(Store Fowarding)這個概念上線了。其理論就是處理器在執行讀操作時會先根據相應的記憶體位址從寫緩沖器中查詢。如果查到了直接傳回,否則處理器才會從高速緩存中查找,這種從緩沖器中讀取的技術就叫做存儲轉發。看圖:
記憶體重排序和可見性的問題
由于寫緩沖器和無效化隊列的出現,處理器的執行都變成了異步操作。緩沖器是每個處理器私有的,一個處理器所存儲的内容是無法被其他處理器讀取的。
舉個例子:
CPU1 更新變量到緩沖器中,而CPU2因為無法讀取到CPU1緩沖器内容是以從高速緩存中讀取的仍然是該變量舊值。
其實這就是寫緩沖器導緻StoreLoad重排序問題,而寫緩沖器還會導緻StoreStore重排序問題等。
為了使一個處理器上運作的線程對共享變量所做的更新被其他處理器上運作的線程讀到,我們必須将寫緩沖器的内容寫到其他處理器的高速緩存上,進而使在緩存一緻性協定作用下此次更新可以被其他處理器讀取到。
處理器在寫緩沖器滿、I/O指令被執行時會将寫緩沖器中的内容寫入高速緩存中。但從變量更新角度來看,處理器本身無法保障這種更新的”及時“性。為了保證處理器對共享變量的更新可被其他處理器同步,編譯器等底層系統借助一類稱為記憶體屏障的特殊指令來實作。
記憶體屏障中的存儲屏障(Store Barrier)會使執行該指令的處理器将寫緩沖器内容寫入高速緩存。
記憶體屏障中的加載屏障(Load Barrier)會根據無效化隊列内容指定的記憶體位址,将相應處理器上的高速緩存中相應的緩存條目狀态标記為I。
四、記憶體屏障
因為說了存儲屏障(Store Barrier)和加載屏障(Load Barrier) ,是以這裡再簡單的提下記憶體屏障的概念。
劃重點:(你細品)
處理器支援哪種記憶體重排序(LoadLoad重排序、LoadStore重排序、StoreStore重排序、StoreLoad重排序),就會提供相對應能夠禁止重排序的指令,而這些指令就被稱之為記憶體屏障(LoadLoad屏障、LoadStore屏障、StoreStore屏障、StoreLoad屏障)
劃重點:
如果用X和Y來代替Load或Store,這類指令的作用就是禁止該指令左側的任何 X 操作與該指令右側的任何 Y 操作之間進行重排序(就是交換位置),確定指令左側的所有 X 操作都優先于指令右側的Y操作。
記憶體屏障的具體作用:
| 屏障名稱 | 示例 | 具體作用 |
|---|---|---|
| StoreLoad | Store1;Store2;Store3;StoreLoad;Load1;Load2;Load3 | 禁止StoreLoad重排序,確定屏障之前任何一個寫(如Store2)的結果都會在屏障後任意一個讀操作(如Load1)加載之前被寫入 |
| StoreStore | Store1;Store2;Store3;StoreStore;Store4;Store5;Store6 | 禁止StoreStore重排序,確定屏障之前任何一個寫(如Store1)的結果都會在屏障後任意一個寫操作(如Store4)之前被寫入 |
| LoadLoad | Load1;Load2;Load3;LoadLoad;Load4;Load5;Load6 | 禁止LoadLoad重排序,確定屏障之前任何一個讀(如Load1)的資料都會在屏障後任意一個讀操作(如Load4)之前被加載 |
| LoadStore | Load1;Load2;Load3;LoadStore;Store1;Store2;Store3 | 禁止LoadStore重排序,確定屏障之前任何一個讀(如Load1)的資料都會在屏障後任意一個寫操作(如Store1)的結果被寫入高速緩存(或主記憶體)前被加載 |
五、總結
其實從頭看到尾就會發現,一個技術點的出現往往是為了填補另一個的坑。
為了解決處理器與主記憶體之間的速度鴻溝,引入了高速緩存,卻又導緻了緩存一緻性問題
為了解決緩存一緻性問題,引入了如MESI等技術,又導緻了處理器等待問題
為了解決處理器等待問題,引入了寫緩沖和無效化隊列,又導緻了重排序和可見性問題
為了解決重排序和可見性問題,引入了記憶體屏障,舒坦。。。
關注這個喜歡分享的地方。本文 架構技術專欄 已收錄,有各種JVM、多線程、源碼視訊、資料以及技術文章等你來拿
往期推薦
每日一個知識點系列:volatile的可見性原理 (最新 9000字) Spring Boot 配置特性解析 何時用多線程?多線程需要加鎖嗎?線程數多少最合理? Spring Boot 知識清單(一)SpringApplication 高并發系統,你需要知道的名額(RT...)